Imagine driving an electric vehicle on a highway. A data collector under your foot captures 80 data points per second across 80 predefined metrics, totaling 2 KB. Within one minute, you can observe this continuously streaming data and use it for real-time analysis of any condition. However, before that, you must rely on a reliable database to ingest and store this valuable data.
Undoubtedly, time-series databases need to handle massive real-time data from numerous devices—loading performance is critical!
In this section, you will use advanced components in YMatrix—MatrixGate and MatrixBench—to conduct powerful data ingestion performance testing, ensuring reliability for subsequent analytics.
Our physical machine test environment is listed below. Hardware specifications may affect tool configuration parameters, so be sure to choose appropriate settings for your own system.
The machine configuration is as follows:
| Parameter | Configuration |
|---|---|
| CPU Cores | 2 physical cores, 32 logical cores |
| CPU Platform | Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz |
| Memory | 256 GB |
| Storage Capacity | 9.0 TB (1.4 GB/s write, 3.3 GB/s read) |
| Linux Distribution | CentOS Linux release 7.8.2003 (Core) |
| Linux Kernel | 3.10.0-1127.el7.x86_64 |
MatrixGate (shortened as mxgate) is a high-performance streaming data loading server located at bin/mxgate under the YMatrix installation directory. It fully leverages the parallel processing capabilities of the distributed database and is the preferred tool for data loading in production environments. During testing, mxgate works with the writer component of mxbench to rapidly ingest random data generated by the generator.
For more information, see mxgate.
mxbench is a stress-testing tool for data loading and querying. It generates random data based on configurations such as number of devices, time range, and number of metrics. It automatically creates tables and supports serial or concurrent data loading and queries. You can configure and run mxbench via command line or define settings in a configuration file—choose the method that suits your preference. The mxbench tool is located at bin/mxbench under the YMatrix installation directory.
Single-machine deployment: Master + 6 Segments
Note!
You must deploy MatrixGate and MatrixBench on the same machine as the YMatrix cluster.
We provide three test cases with varying metric scales to simulate different time-series scenarios. At the end of this section, we will visually compare YMatrix's write performance across these different metric scales:
Note!
Before usingmxbenchfor load testing, ensure your test environment is ready: a running YMatrix cluster and properly configured environment variables. This step is mandatory! No manual setup is required for mxgate—it is automatically configured and started when you launch mxbench.
For cluster deployment instructions, refer to Cluster Deployment. For mxbench configuration, see mxbench.
mxbench configuration parameters are divided into two parts: global settings and pluggable component settings. Global settings include the database and global sections; pluggable settings cover the generator, writer, and benchmark tools.
Since this section focuses on evaluating YMatrix’s loading performance, we will not elaborate on the benchmark query tool here.
For details about benchmark, see mxbench.
The following table describes key parameters:
| Parameter Name | Default Value | Description |
|---|---|---|
--database |
Value of environment variable PGDATABASE, otherwise postgres |
Target database name |
--db-master-port |
— | Instance port number; must match the value in environment variables |
--db-user |
Current username | Database user |
--workplace |
/tmp/mxbench |
Directory for CSV data files and query files |
--watch |
true |
Enable process monitoring (default: enabled) |
--simultaneous-loading-and-query |
false |
Load and query simultaneously. Default false: load first, then query |
--table-name |
— | Target table name (required, must be specified manually) |
--tag-num |
25000 | Number of devices |
--metrics-type |
float8 |
Metric data type. Supported: "int4", "int8", "float4", "float8" |
--total-metrics-count |
300 | Total number of metrics |
--ts-start |
— | Start timestamp for generated data |
--ts-end |
— | End timestamp for generated data |
--ts-step-in-second |
1 | Interval between metric samples (seconds) |
--generator |
telematics |
Random data generator. Defaults to generating telematics scenario data. Can also read from custom data files or skip generation |
--generator-batch-size |
1 | Number of rows per device per timestamp. Default 1 means no splitting |
--generator-disorder-ratio |
0 | Percentage of out-of-order (delayed) data. Range: 0–100. Default 0 (no delay). Use to simulate real-world latency |
--generator-empty-value-ratio |
90 | Percentage of null values per row. Range: 0–100. Default 90 (90% nulls), simulating sparse time-series data |
--generator-randomness |
OFF |
Data randomness level: OFF/S/M/L. Default OFF (constant values). Increases randomness from S to L |
--writer |
http |
Data writer mode. Determines how mxgate receives data |
For more configurable parameters, visit mxbench or run mxbench --help in the command line.
Use the following command to configure and run mxbench. Adjust parameter values according to your environment. Since mxgate and mxbench are co-located, using the "stdin" writer avoids network overhead by leveraging Linux pipes—lightweight and efficient.
[mxadmin@mdw ~]$ mxbench run \
--db-database "load_test" \
--db-database "load_test" \
--db-master-port 5432 \
--db-master-host "mdw" \
--db-user "mxadmin" \
--workspace "/tmp/mxbench/workspace" \
--watch \
--simultaneous-loading-and-query \
--table-name "test_table" \
--tag-num 100000 \
--metrics-type "float8" \
--total-metrics-count 10 \
--ts-start "2022-04-19 00:00:00" \
--ts-end "2022-04-19 00:01:00" \
--generator "telematics" \
--generator-batch-size 1 \
--generator-disorder-ratio 0 \
--generator-empty-value-ratio 0 \
--generator-randomness "OFF" \
--writer "stdin" If --watch is not disabled, progress updates appear every 5 seconds. Upon completion, you’ll see output like:
┌───────────────────────────────────────────────────────┐
│ Summary Report for STDIN Writer │
├─────────────────────────────────┬─────────────────────┤
│ start time: │ 2022-07-21 15:14:08 │
├─────────────────────────────────┼─────────────────────┤
│ stop time: │ 2022-07-21 15:14:27 │
├─────────────────────────────────┼─────────────────────┤
│ size written to MxGate (bytes): │ 695333400 │
├─────────────────────────────────┼─────────────────────┤
│ lines inserted: │ 6000000 │
├─────────────────────────────────┼─────────────────────┤
│ compress ratio: │ 5.399120 : 1 │
└─────────────────────────────────┴─────────────────────┘ Writer report explanation:
| Parameter Name | Description |
|---|---|
| start time | Data loading start time |
| stop time | Data loading end time |
| size written to MxGate (bytes) | Total bytes sent to mxgate |
| lines inserted | Number of data rows inserted |
| compress ratio | Compression ratio: size written to mxgate vs. actual table size in database |
Actual runtime depends on total data volume and machine performance. As long as watch is enabled, you’ll get real-time progress every 5 seconds, allowing you to monitor write speed and duration.
Note!
mxbenchruns continuously until all data fromts-starttots-endis loaded. You can pressCtrl+Cto terminate early.
If writing long command lines feels cumbersome, create a config file mxbench.conf, place your parameters inside, and run:
[mxadmin@mdw ~]$ mxbench --config mxbench.confNote!
You might encounter a "hang" during data loading—progress logs keep printing but no real progress occurs. Stay calm. Run the following command to check logs and troubleshoot:cd ~/gpAdminLogs/.
[mxadmin@mdw ~]$ mxbench run \
--db-database "load_test" \
--db-master-port 5432 \
--db-master-host "mdw" \
--db-user "mxadmin" \
--workspace "/tmp/mxbench/workspace" \
--watch \
--simultaneous-loading-and-query \
--table-name "test_table2" \
--tag-num 100000 \
--metrics-type "float8" \
--total-metrics-count 100 \
--ts-start "2022-04-19 00:00:00" \
--ts-end "2022-04-19 00:01:00" \
--generator "telematics" \
--generator-batch-size 1 \
--generator-disorder-ratio 0 \
--generator-empty-value-ratio 0 \
--generator-randomness "OFF" \
--writer "stdin" Output upon completion:
┌───────────────────────────────────────────────────────┐
│ Summary Report for STDIN Writer │
├─────────────────────────────────┬─────────────────────┤
│ start time: │ 2022-07-21 15:19:48 │
├─────────────────────────────────┼─────────────────────┤
│ stop time: │ 2022-07-21 15:21:02 │
├─────────────────────────────────┼─────────────────────┤
│ size written to MxGate (bytes): │ 5555333400 │
├─────────────────────────────────┼─────────────────────┤
│ lines inserted: │ 6000000 │
├─────────────────────────────────┼─────────────────────┤
│ compress ratio: │ 25.519937 : 1 │
└─────────────────────────────────┴─────────────────────┘[mxadmin@mdw ~]$ mxbench run \
--db-database "load_test" \
--db-master-port 5432 \
--db-master-host "mdw" \
--db-user "mxadmin" \
--workspace "/tmp/mxbench/workspace" \
--watch \
--simultaneous-loading-and-query \
--table-name "test_table3" \
--tag-num 100000 \
--metrics-type "float8" \
--total-metrics-count 1000 \
--ts-start "2022-04-19 00:00:00" \
--ts-end "2022-04-19 00:01:00" \
--generator "telematics" \
--generator-batch-size 1 \
--generator-disorder-ratio 0 \
--generator-empty-value-ratio 0 \
--generator-randomness "OFF" \
--writer "stdin" Output upon completion:
┌───────────────────────────────────────────────────────┐
│ Summary Report for STDIN Writer │
├─────────────────────────────────┬─────────────────────┤
│ start time: │ 2022-07-21 15:22:27 │
├─────────────────────────────────┼─────────────────────┤
│ stop time: │ 2022-07-21 15:33:40 │
├─────────────────────────────────┼─────────────────────┤
│ size written to MxGate (bytes): │ 54305333400 │
├─────────────────────────────────┼─────────────────────┤
│ lines inserted: │ 6000000 │
├─────────────────────────────────┼─────────────────────┤
│ compress ratio: │ 47.488209 : 1 │
└─────────────────────────────────┴─────────────────────┘Based on the above writer reports, we provide a clear line chart comparison below. It illustrates YMatrix’s strong data loading performance and how it scales with increasing metric counts. This insight helps you make informed decisions about metric count in real-world deployments.
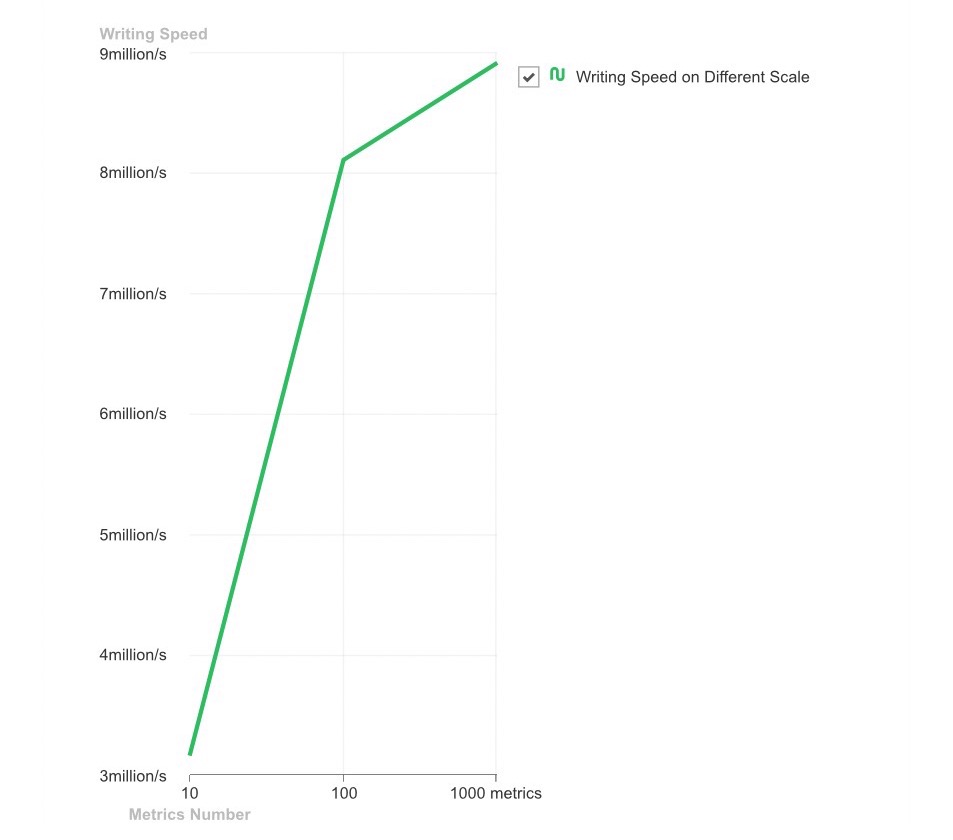
Time-series data consists of timestamped data points—each representing a metric value at a specific moment. Without timestamps, it cannot be considered time-series data. Understanding data points helps interpret the chart above.
The x-axis shows different metric scales (total-metrics-count). The y-axis shows write throughput, i.e., number of data points written per second. As metric count increases, write throughput grows rapidly—but growth slows with higher metric counts. Regardless, YMatrix maintains million-level write speeds. Instead of painfully inserting rows one by one with INSERT, why not take YMatrix for a high-speed ride?