YMatrix
Quick Start
Connecting
Benchmarks
Deployment
Data Usage
Data Ingestion
Data Migration
Data Query
Manage Clusters
Upgrade
Global Maintenance
Expansion
Monitoring
Security
Best Practice
Technical Principles
Data Type
Storage Engine
Execution Engine
Streaming Engine(Domino)
MARS3 Index
Extension
Advanced Features
Advanced Query
Federal Query
Grafana
Backup and Restore
Disaster Recovery
Graph Database
Introduction
Clauses
Functions
Advanced
Guide
Performance Tuning
Troubleshooting
Tools
Configuration Parameters
SQL Reference
YMatrix is an enterprise-grade distributed database product based on PostgreSQL. Integrating time-series, analytics (OLAP), transaction processing (OLTP), and AI capabilities into a single platform, YMatrix delivers full-scenario support, low cost, high performance, high availability, easy scalability, and compliance with security standards. With its "hyper-converged" architecture, YMatrix addresses the challenges of complex traditional systems and high operational costs, offering enterprises a unified data storage solution.

Optimized for time-series workloads, YMatrix provides high concurrency and is deeply tuned for applications such as connected vehicles and smart factories. It supports advanced SQL features like CTEs and window functions, along with native time-series functions. It enables out-of-order and batched writes in complex network environments. Cluster expansion with zero business interruption allows flexible scaling for growing data volumes. Cold data can be automatically offloaded to object storage, significantly reducing storage costs.
Supports TB to PB-scale data volumes, delivering reliable and high-performance data processing and service capabilities for enterprise reporting and BI applications. Offers powerful performance and excels at multi-table JOIN operations. Supports advanced analytical features such as window functions and materialized views. Beyond traditional batch processing, YMatrix introduces the Domino streaming engine, enabling real-time data processing via SQL—replacing tools like Flink or Spark.
Provides full ACID compliance, ensuring financial-grade data reliability. Meets the stringent performance, correctness, and consistency requirements of critical systems such as finance and ERP. Supports stored procedures, triggers, and cross-site disaster recovery, making it suitable for complex OLTP use cases.
Enables vector search for large language models (LLM), helping enterprises rapidly build AI agents using business data. Supports in-database execution of PL/Python without requiring Spark, fully utilizing hardware resources and improving machine learning efficiency. Offers multimodal data management and hybrid search capabilities.
SQL : 2016 standardsMatrixUI is a graphical operations and management tool designed for simplicity and comprehensive monitoring.

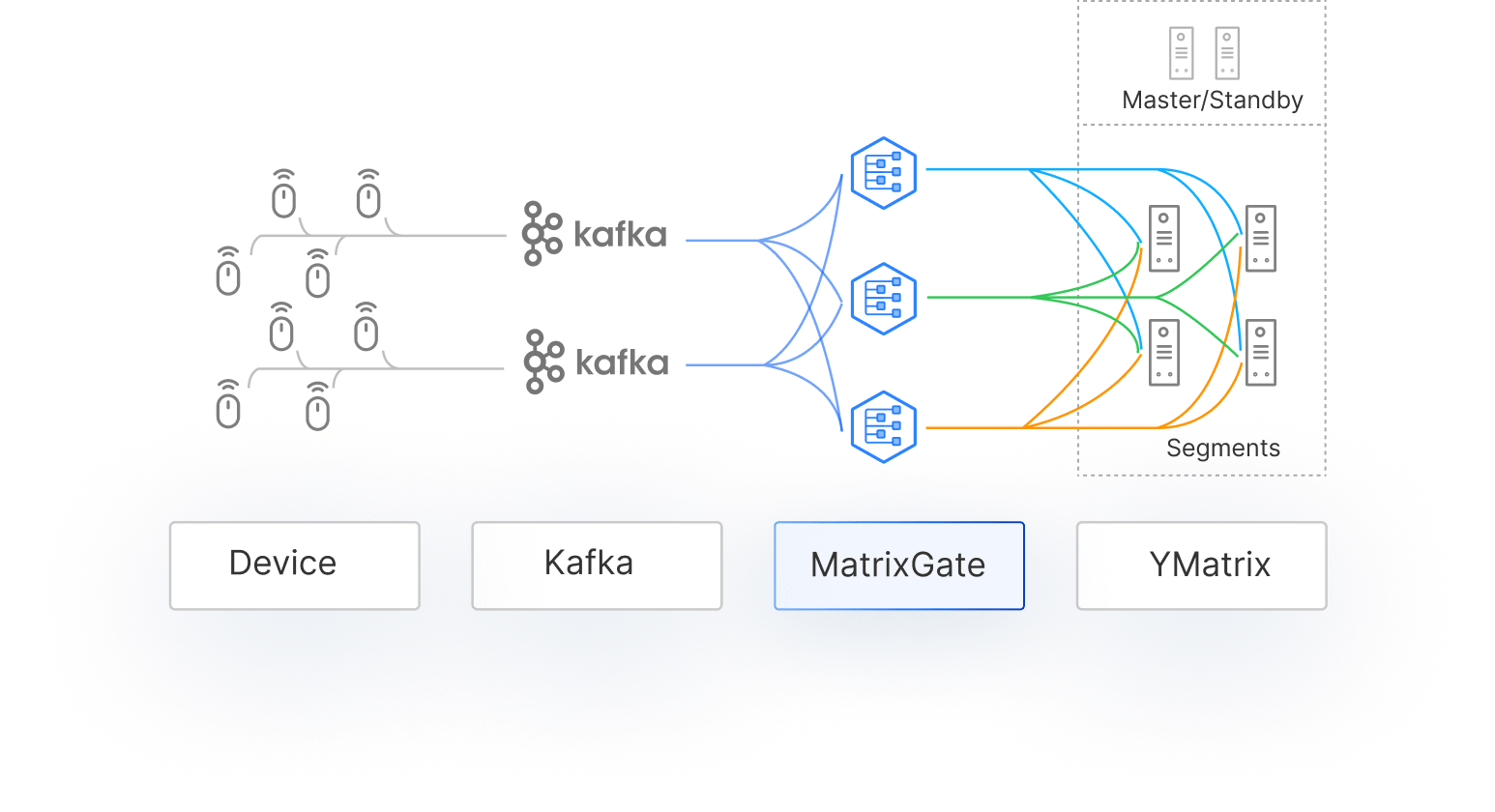
MatrixGate is a high-performance data loader that distributes data evenly across all segments for parallel ingestion.
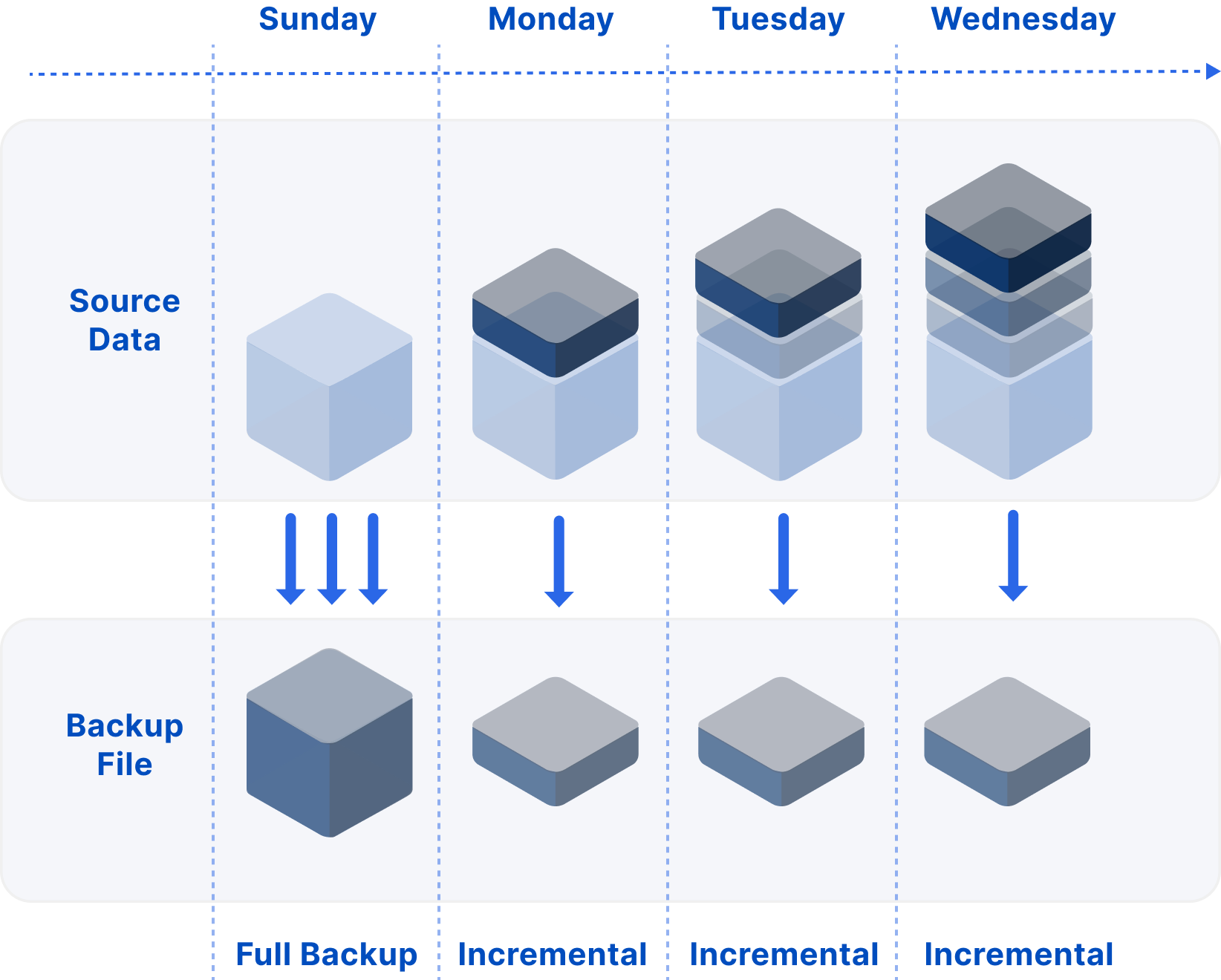
MatrixArchive captures a running YMatrix cluster’s data at a specific point in time, saving it according to defined rules to ensure data integrity and consistency. From these backup files, a fully functional YMatrix cluster can be restored, matching the original cluster’s state at that moment.
MatrixShift is a dedicated data migration tool supporting full, incremental, and conditional migrations between different versions of Greenplum and YMatrix. Features include high efficiency (peer-to-peer transfer, small-table optimization, data compression) and flexible configuration.
YMatrix System Architecture
Quick Start Guide
Standard Cluster Deployment
Use Cases