Быстрый старт
Развертывание
Моделирование данных
Подключение
Запись данных
Миграция
Запросы
Операции и обслуживание
Типовое обслуживание
Секционирование
Резервное копирование и восстановление
Масштабирование
Зеркалирование
Управление ресурсами
Безопасность
Мониторинг
Настройка производительности
Устранение неполадок
Справочник
Руководство по инструментам
Типы данных
Хранилище данных
Выполняющая система
Потоковая передача
Восстановление после сбоев
Конфигурация
Индексы
Расширения
Справочник по SQL
Часто задаваемые вопросы
YMatrix — это корпоративная распределённая база данных на основе PostgreSQL. Интегрируя возможности обработки временных рядов, аналитики (OLAP), транзакционной обработки (OLTP) и искусственного интеллекта в единую платформу, YMatrix обеспечивает поддержку полного спектра сценариев использования, низкую стоимость владения, высокую производительность, высокую доступность, простое масштабирование и соответствие стандартам безопасности. Благодаря своей «гиперконвергентной» архитектуре YMatrix решает проблемы сложных традиционных систем и высоких эксплуатационных затрат, предлагая предприятиям единое решение для хранения данных.

Оптимизированная для рабочих нагрузок с временными рядами, YMatrix обеспечивает высокую пропускную способность и глубоко настроена для приложений, таких как подключённые автомобили и умные производства. Поддерживает расширенные функции SQL, включая CTE и оконные функции, а также родные функции для временных рядов. Обеспечивает запись данных с нарушением порядка и пакетную запись в условиях сложных сетей. Масштабирование кластера без прерывания бизнес-процессов позволяет гибко наращивать объёмы хранимых данных. Холодные данные могут автоматически перемещаться в объектное хранилище, что значительно снижает затраты на хранение.
Поддерживает объёмы данных от терабайт до петабайт, обеспечивая надёжную и высокопроизводительную обработку данных и сервисные возможности для корпоративной отчётности и BI-приложений. Обладает высокой производительностью и отлично справляется с операциями соединения нескольких таблиц. Поддерживает продвинутые аналитические функции, такие как оконные функции и материализованные представления. Помимо традиционной пакетной обработки, YMatrix предлагает потоковый движок Domino, позволяющий выполнять обработку данных в реальном времени с помощью SQL — заменяя такие инструменты, как Flink или Spark.
Обеспечивает полную поддержку ACID, гарантируя надёжность данных на уровне финансовых систем. Соответствует строгим требованиям по производительности, корректности и согласованности для критически важных систем, таких как финансы и ERP. Поддерживает хранимые процедуры, триггеры и аварийное восстановление между сайтами, что делает её подходящей для сложных OLTP-сценариев.
Позволяет выполнять векторный поиск для больших языковых моделей (LLM), помогая предприятиям быстро создавать агентов ИИ на основе бизнес-данных. Поддерживает выполнение PL/Python непосредственно внутри базы данных без необходимости использования Spark, что позволяет полностью использовать аппаратные ресурсы и повышает эффективность машинного обучения. Предоставляет возможности управления мультимодальными данными и гибридного поиска.
SQL : 2016MatrixUI — это графический инструмент управления и администрирования, разработанный для простоты использования и комплексного мониторинга.

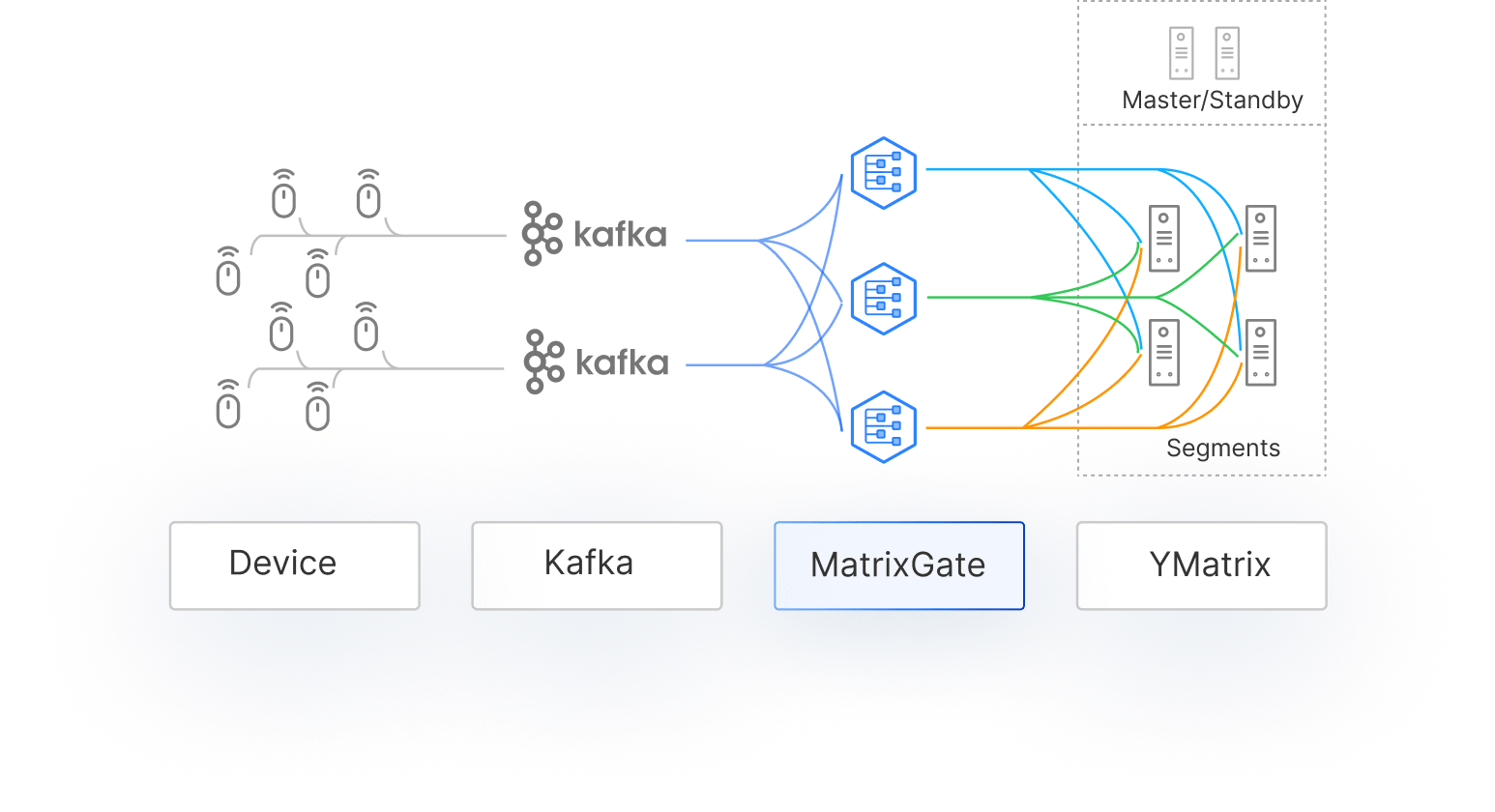
MatrixGate — высокопроизводительный загрузчик данных, который равномерно распределяет данные по всем сегментам для параллельной загрузки.
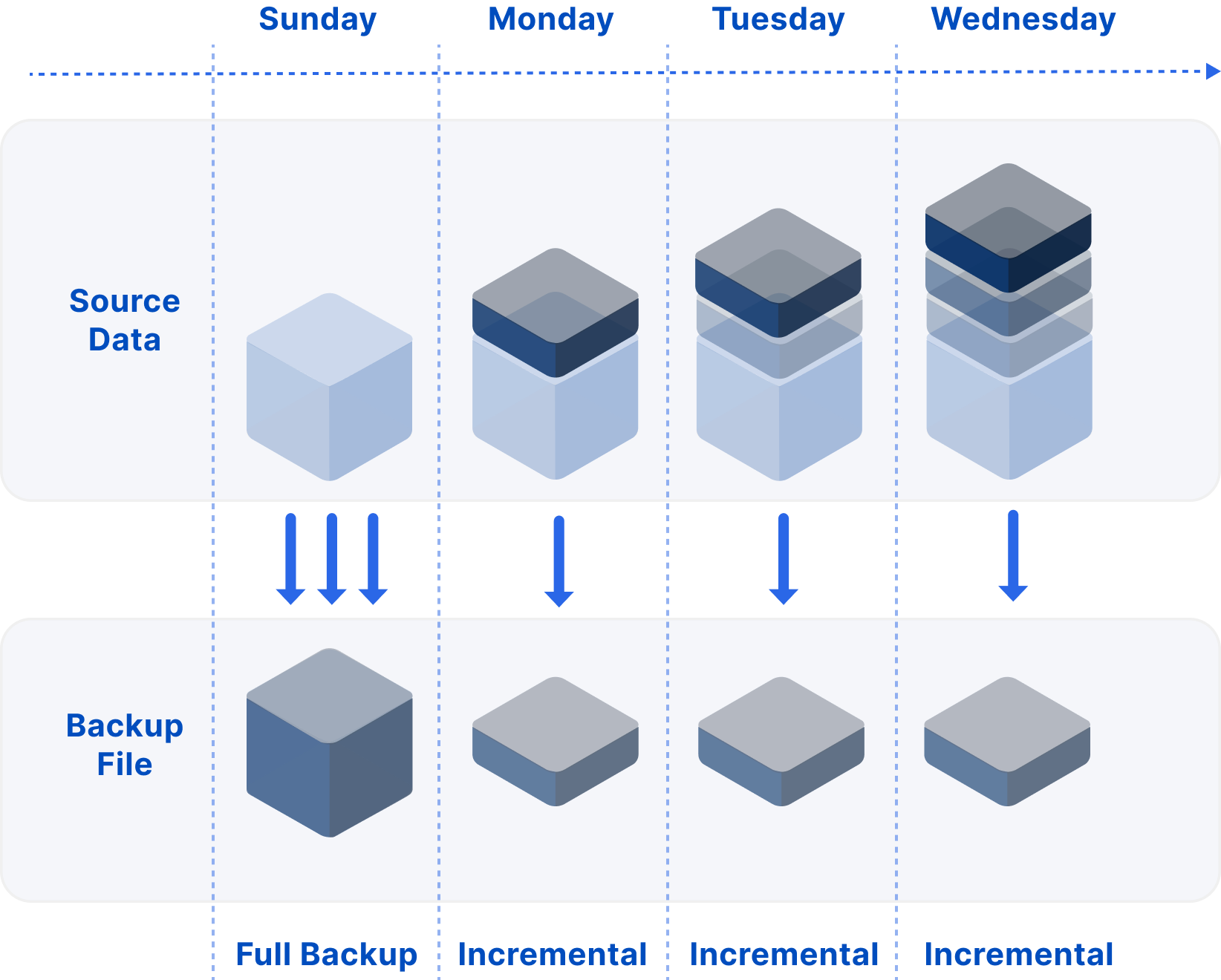
MatrixArchive фиксирует состояние работающего кластера YMatrix в определённый момент времени и сохраняет его в соответствии с заданными правилами, обеспечивая целостность и согласованность данных. Из этих файлов резервной копии можно восстановить полностью функционирующий кластер YMatrix, соответствующий состоянию исходного кластера на момент создания резервной копии.
MatrixShift — специализированный инструмент миграции данных, поддерживающий полную, инкрементальную и условную миграцию между различными версиями Greenplum и YMatrix. Включает высокую эффективность (передача по принципу «точка-точка», оптимизация для малых таблиц, сжатие данных) и гибкую настройку.
YMatrix: архитектура системы
Краткое руководство
Развертывание стандартного кластера
Примеры использования