В этом разделе описывается, как развернуть компоненты аварийного восстановления YMatrix и резервный кластер, используя существующий кластер YMatrix в качестве основного (мастер-кластера).
Перед развертыванием функции аварийного восстановления ознакомьтесь со следующими четырьмя ключевыми понятиями:
Кластер базы данных YMatrix
Полнофункциональный кластер базы данных YMatrix, включающий компоненты высокой доступности и сервисы базы данных.
Основной кластер (мастер-кластер)
Кластер базы данных, который обычно предоставляет сервисы данных или требует защиты данных с помощью аварийного восстановления.
Резервный кластер
Кластер базы данных, получивший данные от основного кластера и способный восстановить данные или предоставить сервисы данных в случае аварии.
Компоненты аварийного восстановления
Компоненты, обеспечивающие резервное копирование данных с основного кластера и переключение сервисов при аварийном восстановлении. Включают:
Подписчик (Subscriber)
Подписчик — это компонент аварийного восстановления, развернутый на стороне основного кластера. Его функции:
a. Принимает запросы на резервное копирование от Издателя на стороне резервного кластера и передает их основному кластеру.
b. Захватывает данные резервного копирования из основного кластера и передает их Издателю на стороне резервного кластера.
Подписчик должен быть развернут на отдельном сервере в той же подсети, что и основной кластер, с сетевой доступностью ко всем узлам основного кластера.
Кроме того, этот сервер должен иметь сетевую доступность к серверу, на котором развернут Издатель на стороне резервного кластера (желательно в той же подсети).
Издатель (Publisher)
Издатель — это компонент аварийного восстановления, развернутый на стороне резервного кластера. Его функции:
a. Принимает запросы на резервное копирование от резервного кластера и передает их Подписчику на стороне основного кластера.
b. Получает данные резервного копирования от Подписчика и доставляет их резервному кластеру.
Издатель должен быть развернут на отдельном сервере в той же подсети, что и резервный кластер, с сетевой доступностью ко всем узлам резервного кластера.
Этот сервер также должен поддерживать сетевую доступность к серверу, на котором развернут Подписчик на стороне основного кластера.
Резервный кластер
В режиме резервного копирования резервный кластер асинхронно или синхронно реплицирует все данные с основного кластера и поддерживает только операции чтения.
После переключения при аварийном восстановлении резервный кластер становится полнофункциональным кластером YMatrix, поддерживающим все типы операций с данными.
Примечание: В настоящее время резервный кластер не поддерживает высокую доступность; каждая шард-часть имеет только одну реплику.
Для включения аварийного восстановления параметр GUC synchronous_commit в основном кластере поддерживает только следующие значения: off (рекомендуется), local, remote_apple и on.
Перед развертыванием войдите на мастер-узел основного кластера под пользователем mxadmin и выполните следующую команду для установки параметра synchronous_commit:
gpconfig -c synchronous_commit -v <one_of_the_supported_values>Выполните команду mxstop -u, чтобы перезагрузить конфигурацию и применить изменения.
Сторона основного кластера
Сторона резервного кластера
Межсетевое соединение
Примечание: Данная сетевая настройка применима только при развертывании резервного кластера в другом центре обработки данных, чем основной кластер. Адаптируйте настройку для других сценариев развертывания.
Примечание!
Версия программного обеспечения YMatrix, установленная на резервном кластере, должна точно совпадать с версией на основном кластере.Архитектура процессора резервного кластера должна быть идентична архитектуре основного кластера.
Добавление сервера Подписчика на сторону основного кластера
a. Установите на сервере Подписчика ту же версию программного обеспечения YMatrix, что и на основном кластере.
b. На любом узле основного кластера с правами root добавьте имя хоста (или IP-адрес) сервера Подписчика (IP-адрес Подписчика со стороны основного кластера) в системный файл /etc/hosts.
c. На мастер-узле основного кластера войдите под пользователем root и создайте каталог конфигурации:
mkdir ~/subscriberЗатем выполните следующие команды:
# Initialize expand
/opt/ymatrix/matrixdb6/bin/mxctl expand init \
> ~/subscriber/expand.init
# Add subscriber host
cat ~/subscriber/expand.init | \
/opt/ymatrix/matrixdb6/bin/mxctl expand add --host {{subscriber_hostname_or_primary_side_IP}} \
> ~/subscriber/expand.add
# Perform network connectivity check
cat ~/subscriber/expand.add | \
/opt/ymatrix/matrixdb6/bin/mxctl expand netcheck \
> ~/subscriber/expand.nc
# Generate plan
cat ~/subscriber/expand.nc | \
/opt/ymatrix/matrixdb6/bin/mxbox deployer expand --physical-cluster-only \
> ~/subscriber/expand.plan
# Execute plan
cat ~/subscriber/expand.plan | \
/opt/ymatrix/matrixdb6/bin/mxbox deployer execd. Отредактируйте файл pg_hba.conf на всех сегментах (включая мастер, резервный, основные и зеркальные) основного кластера. Вставьте следующую строку перед секцией #user access rules (желательно перед первым правилом типа trust), чтобы разрешить репликационные подключения от Подписчика:
host all,replication mxadmin {{subscriber_primary_side_IP}}/32 truste. На мастер-узле основного кластера войдите под пользователем mxadmin и выполните следующую команду для перезагрузки конфигурации и активации настройки pg_hba.conf:
/opt/ymatrix/matrixdb6/bin/mxstop -uФайл конфигурации Подписчика
a. На сервере Подписчика войдите под пользователем mxadmin и создайте каталог конфигурации:
mkdir ~/subscriberb. Под пользователем mxadmin создайте файл конфигурации Подписчика ~/subscriber/sub.conf на основе следующего шаблона:
# ~/subscriber/sub.conf
module = 'subscriber'
perf_port = 5587
verbose = true # Set log level as needed
debug = false # Set log level as needed
[[receiver]]
type = 'db'
cluster_id = '' # Primary cluster cluster_id
host = '' # Hostname or IP of primary cluster master
port = 4617 # Listening port of primary cluster master supervisor
dbname = 'postgres'
username = 'mxadmin'
resume_mode = 'default'
restore_point_creation_interval_minute = '3' # Data consistency ensured via restore points
# Controls interval between restore point creation
# Adjustable per requirement
# Default is 5 minutes
slot = 'internal_disaster_recovery_rep_slot' # Deprecated option (retained temporarily)
[[sender]]
type = 'socket'
port = 9320 # Listening port of subscriberФайл конфигурации Supervisor
a. Под пользователем root создайте файл конфигурации subscriber.conf в каталоге /etc/matrixdb6/service для управления subscriber через supervisor:
# /etc/matrixdb/service/subscriber.conf
[program:subscriber]
process_name=subscriber
command=%(ENV_MXHOME)s/bin/mxdr -s <COUNT> -c /home/mxadmin/subscriber/sub.conf
directory=%(ENV_MXHOME)s/bin
autostart=true
autorestart=true
stopsignal=TERM
stdout_logfile=/home/mxadmin/gpAdminLogs/subscriber.log
stdout_logfile_maxbytes=50MB
stdout_logfile_backups=10
redirect_stderr=true
user=mxadminЗдесь <COUNT> — количество шардов в основном кластере, которое можно получить, выполнив:
SELECT count(1) FROM gp_segment_configuration WHERE role='p'Запуск и управление Подписчиком через Supervisor
a. На сервере Подписчика войдите под пользователем root и выполните следующие команды для регистрации и запуска Подписчика через supervisor:
/opt/ymatrix/matrixdb6/bin/supervisorctl update
/opt/ymatrix/matrixdb6/bin/supervisorctl start subscriberУстановите ту же версию программного обеспечения YMatrix (что и на основном кластере), а также необходимые зависимости, на серверах Издателя и резервного кластера.
На одном из узлов резервного кластера с правами root добавьте имя хоста Издателя (IP-адрес Издателя со стороны резервного кластера) в системный файл /etc/hosts.
На сервере Издателя войдите под пользователем root и создайте каталог конфигурации:
mkdir ~/publisherГенерация файла сопоставления
На мастер-узле основного кластера войдите под пользователем mxadmin и выполните следующий SQL-запрос для генерации шаблонного файла /tmp/mapping.tmp для сопоставления шардов:
COPY (
SELECT content, hostname, port, datadir
FROM gp_segment_configuration
WHERE role='p'
ORDER BY content
) TO '/tmp/mapping.tmp' DELIMITER '|'Отредактируйте сгенерированный файл в соответствии с реальными условиями развертывания:
content) указывает на content id основного кластера и должен остаться неизменным.主机名: Имя хоста резервного сегментаprimary 端口号: Номер порта резервного сегмента数据目录: Путь к каталогу данных резервного сегментаДля получения подробной справки используйте следующую команду:
mxbox deployer dr pub configПосле редактирования переместите файл в каталог ~/publisher пользователя root на сервере Издателя.
Пример до и после редактирования:
| До | После |
|---|---|
 |
 |
Файл конфигурации Издателя
На сервере Издателя под пользователем root создайте файл конфигурации Издателя ~/Publisher/pub.conf по следующему шаблону:
# ~/publisher/pub.conf
module = 'publisher'
perf_port = 6698
verbose = true # Set log level as needed
debug = false # Set log level as needed
[[receiver]]
type = 'socket'
host = '' # Subscriber external IP (from above)
port = 9320 # Subscriber listening port
[[sender]]
type = 'db'
host = '127.0.0.1'
listen = 6432 # Base listening port for publisher; varies with shard count
username = 'mxadmin'
dbname = 'postgres'
dir = '/tmp' # Temporary directory for runtime data
schedule = 'disable' # Disable M2 schedulerРазвертывание резервного кластера
На сервере Издателя войдите под пользователем root и выполните следующие шаги:
a. collect
Соберите информацию о аппаратном обеспечении и сети узлов резервного кластера.
# Collect info from master node
/opt/ymatrix/matrixdb6/bin/mxctl setup collect --host {{backup_cluster_master_IP}} \
> ~/publisher/collect.1
# Collect info from other segment hosts
cat ~/publisher/collect.1 | \
/opt/ymatrix/matrixdb6/bin/mxctl setup collect --host {{other_backup_host_IP}} \
> ~/publisher/collect.2
...
# Collect info from last segment host
cat ~/publisher/collect.n-1 | \
/opt/ymatrix/matrixdb6/bin/mxctl setup collect --host {{other_backup_host_IP}} \
> ~/publisher/collect.n
# Collect info from publisher host
cat ~/publisher/collect.n | \
/opt/ymatrix/matrixdb6/bin/mxctl setup collect --host {{publisher_IP}} \
> ~/publisher/collect.ncb. netcheck
Проверьте сетевую доступность между узлами резервного кластера.
cat ~/publisher/collect.nc | \
/opt/ymatrix/matrixdb6/bin/mxctl setup netcheck \
> ~/publisher/plan.ncc. plan
Сгенерируйте план развертывания для Издателя.
/opt/ymatrix/matrixdb6/bin/mxbox deployer dr pub plan \
--wait \
--enable-redo-stop-pit \
--collect-file ~/publisher/plan.nc \
--mapping-file ~/publisher/mapping.conf \
--publisher-file ~/publisher/pub.conf \
> ~/publisher/planПримечание!
Вы должны установить--enable-redo-stop-pit. Эта опция гарантирует окончательную согласованность данных в резервном кластере.
d. setup
Разверните резервный кластер и подключите его к Издателю для начала репликации данных.
/opt/ymatrix/matrixdb6/bin/mxbox deployer dr pub setup \
--plan-file ~/publisher/planwalsender основного кластера
root и выполните: ps aux | grep postgres | grep walsendersubscriber, в состоянии streaming, как показано ниже:
Подписчик
mxadmin и выполните: supervisorctl statussubscriber в состоянии Running:
Издатель
mxadmin и выполните: supervisorctl statuspublisher в состоянии Running:
walreceiver резервного кластера
root и выполните: ps aux | grep postgres | grep walreceiversubscriber, в состоянии streaming:
Примечание: Общее количество процессов
walreceiverв резервном кластере должно равняться количеству шардов в исходном кластере.
Выполните следующие шаги для проверки репликации:
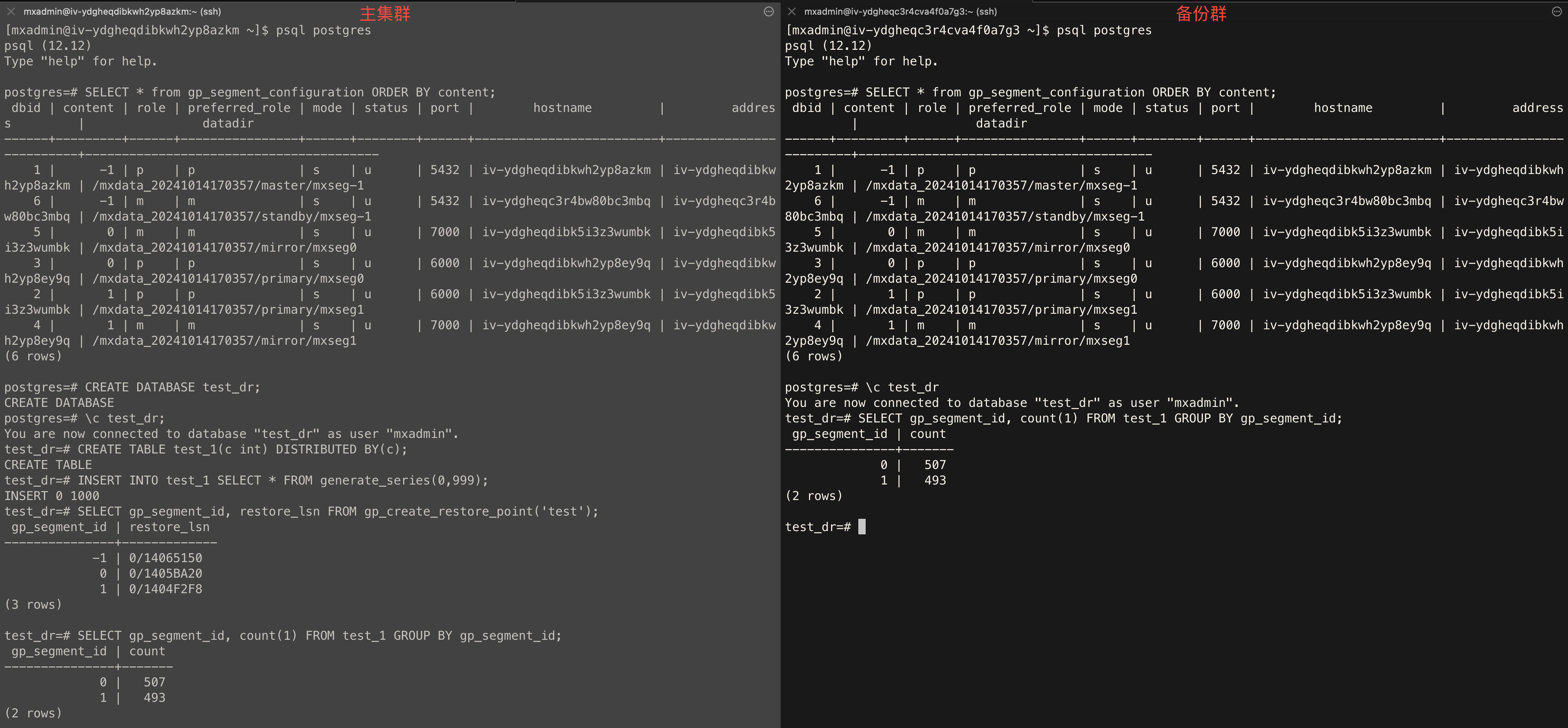
Топология кластера
SELECT * from gp_segment_configuration ORDER BY content, dbid;Создание базы данных
CREATE DATABASE test_dr;Создание таблицы
test_dr на основном кластере и выполните: CREATE TABLE test_1(c int) DISTRIBUTED BY (c);Вставка данных
test_dr на основном кластере и вставьте тестовые данные: INSERT INTO test_1 SELECT * FROM generate_series(0,999);Создание точки восстановления
test_dr на основном кластере и создайте глобальную точку согласованности: SELECT gp_segment_id, restore_lsn FROM gp_create_restore_point('test');Проверка статуса синхронизации
test_dr на обоих кластерах и выполните: SELECT gp_segment_id, count(1) FROM test_1 GROUP BY gp_segment_id;Пример вывода: