datainspect — встроенный инструмент диагностики хранилища в MARS2, предоставляющий низкоуровневые данные для точной оптимизации хранения и производительности запросов.
Оптимизация хранилища требует понимания реального содержимого данных в физических файлах. Аналогично PostgreSQL's Pageinspect, вы можете использовать datainspect для простого извлечения сегментов данных из физического хранилища MARS2 для дальнейшего анализа.
Кроме того, datainspect интегрирует соответствующие индексы и метаданные в MARS2, предоставляя базовую информацию, такую как распределение NULL и минимальные/максимальные значения, что помогает оптимизировать сканирование I/O.
Примечание!
Этот инструмент применим только к таблицам MARS2.
datainspect состоит из системных функций, встроенных в MARS2, и становится доступным после корректной установки MARS2. Таблицы MARS2 зависят от расширения временных рядов matrixts. Перед созданием таблиц необходимо сначала создать это расширение в базе данных, где будет использоваться движок хранения MARS2.
Примечание!
Расширениеmatrixtsимеет область действия базы данных. Создавайте его один раз на базу данных; не создавайте его повторно.
=# CREATE EXTENSION matrixts;Сначала создайте тестовую таблицу с именем tb1 для демонстрации. В следующих разделах представлены четыре связанные функции, использующие эту таблицу.
=# CREATE TABLE tb1(
f1 int8 encoding(minmax),
f2 int8 encoding(minmax),
f3 float8 encoding(minmax),
f4 text
) USING MARS2
WITH (compresstype=lz4);Создайте индекс MARS2:
=# CREATE INDEX ON tb1 USING mars2_btree(f1);Вставьте 24 000 тестовых записей:
=# INSERT INTO tb1 SELECT
generate_series(1, 24000),
mod((random()*1000000*(generate_series(1, 1200)))::int8, (random()::int8/100 + 100)),
(random() * generate_series(1, 24000))::float8,
(random() * generate_series(1, 24000))::text;Функция desc_ranges интегрирует низкоуровневые метаданные и индексы MARS2, предоставляя информацию, такую как минимальные/максимальные значения индекса и статистика по NULL-значениям. Она также поддерживает точный мониторинг использования физического пространства хранилища.
Синтаксис
SELECT <* / column1,column2,...> FROM matrixts_internal.desc_ranges(<'tablename'>)Параметры
| Поле | Описание | Обязательно |
|---|---|---|
| tablename | Имя таблицы; для партиционированных таблиц используйте имя родительской таблицы | Да |
| Поле | Описание |
|---|---|
| segno | Номер сегмента, начинается с 0 |
| attno | Номер атрибута (индекс столбца), начинается с 0 |
| forkno | Номер вилки физического файла. Низкоуровневый идентификатор базы данных, соответствующий конкретному файлу. По умолчанию начинается с первой вилки. |
| offno | Байтовый сдвиг RANGE внутри физического файла, начинается с 0. В MARS2 данные хранятся пакетами. Каждый пакет формирует хранилище RANGE на основе настроенного compress_threshold (порог сжатия), позиция которого определяется байтовым сдвигом. |
| nbytes | Фактический объем занимаемого SPACE в байтах |
| nrows | Значение, заданное при создании таблицы для compress_threshold, по умолчанию 1200. Это порог сжатия, определяющий, сколько кортежей сжимаются вместе — максимальное количество кортежей в одном блоке сжатия. |
| nrowsnotnull | Количество ненулевых записей в RANGE |
| mmin | Минимальное значение в RANGE, если столбец поддерживает minmax-индексирование; иначе NULL |
| mmax | Максимальное значение в RANGE, если столбец поддерживает minmax-индексирование; иначе NULL |
=# SELECT attno, sum(nbytes)/1024 as "Size in KB"
FROM matrixts_internal.desc_ranges('tb1') GROUP BY attno ORDER BY attno;
attno | Size in KB
-------+----------------------
0 | 94.9062500000000000
1 | 7.8203125000000000
2 | 187.3437500000000000
3 | 386.3515625000000000
(4 rows)=# SELECT * FROM matrixts_internal.desc_ranges('tb1') WHERE segno = 1;
segno | attno | forkname | forkno | offno | nbytes | nrows | nrowsnotnull | mmin | mmax
-------+-------+----------+--------+--------+--------+-------+--------------+--------------------+--------------------
1 | 0 | data1 | 304 | 0 | 4848 | 1200 | 1200 | 15 | 7240
1 | 1 | data1 | 304 | 16376 | 856 | 1200 | 199 | 0 | 99
1 | 2 | data1 | 304 | 17712 | 9072 | 1200 | 1200 | 1.4602231817218758 | 704.8010557110921
1 | 3 | data1 | 304 | 50024 | 20272 | 1200 | 1200 | NULL | NULL
1 | 0 | data1 | 304 | 4848 | 4856 | 1200 | 1200 | 7243 | 14103
1 | 1 | data1 | 304 | 17232 | 160 | 1200 | 0 | NULL | NULL
1 | 2 | data1 | 304 | 26784 | 9760 | 1200 | 1200 | 705.0931003474365 | 1372.9018354549075
1 | 3 | data1 | 304 | 70296 | 19680 | 1200 | 1200 | NULL | NULL
1 | 0 | data1 | 304 | 9704 | 4856 | 1200 | 1200 | 14125 | 21417
1 | 1 | data1 | 304 | 17392 | 160 | 1200 | 0 | NULL | NULL
1 | 2 | data1 | 304 | 36544 | 9760 | 1200 | 1200 | 1375.043496121433 | 2084.906658862494
1 | 3 | data1 | 304 | 89976 | 19792 | 1200 | 1200 | NULL | NULL
1 | 0 | data1 | 304 | 14560 | 1816 | 445 | 445 | 21429 | 23997
1 | 1 | data1 | 304 | 17552 | 160 | 445 | 0 | NULL | NULL
1 | 2 | data1 | 304 | 46304 | 3720 | 445 | 445 | 2086.0748374078717 | 2336.065046118657
1 | 3 | data1 | 304 | 109768 | 7576 | 445 | 445 | NULL | NULL
(16 rows)Функция show_range считывает указанный сегмент физических данных из MARS2 и представляет их в человеко-читаемом формате. В настоящее время поддерживаются следующие типы данных: int2, int4, int8, float4, float8, timestamp, date и text.
Синтаксис
SELECT <* / column1,column2,...> FROM matrixts_internal.show_range(
tablename text,
attno int4,
forkno int4,
offno int4,
nbytes int4
)Параметры
| Поле | Описание | Обязательно |
|---|---|---|
| tablename | Имя таблицы; для партиционированных таблиц используйте имя родительской таблицы | Да |
| attno | Индекс столбца, нумеруется последовательно с 0 при определении таблицы |
Да |
| forkno | Номер вилки физического файла | Да |
| offno | Байтовый сдвиг данных в физическом файле | Да |
| nbytes | Фактический размер в байтах, занимаемый данными | Да |
Примечание!
Сведения об этих параметрах см. в полях возврата функцииdesc_ranges, описанной выше.
| Поле | Описание |
|---|---|
| rowno | Номер строки. Это относительный индекс внутри текущего RANGE, а не абсолютный сдвиг по всей таблице. |
| val | Фактическое значение данных |
Примечание!
Отображаемые значения с плавающей запятой могут содержать погрешности точности (val).
=# SELECT * FROM matrixts_internal.show_range('tb1', 1, 304, 16176, 808) LIMIT 20;
rowno | val
-------+-----
1 | 4
2 | 36
3 | 81
4 | 58
5 | 17
6 | 75
7 | 11
8 | 84
9 | 60
10 | 78
11 | 69
12 | 0
13 | 87
14 | 40
15 | 72
16 | 58
17 | 17
18 | 48
19 | 70
20 | 6
(20 rows)Функция dump_range распаковывает выбранные физические данные из MARS2 и экспортирует их в двоичный файл для вторичного анализа.
Синтаксис
=# SELECT <* / column1,column2,...> FROM matrixts_internal.dump_ranges(
tablename text,
attno int4,
outfile text,
forkno int4,
offno int4,
limits int4
);Параметры
| Поле | Описание | Обязательно |
|---|---|---|
| tablename | Имя таблицы; для партиционированных таблиц используйте имя родительской таблицы | Да |
| attno | Индекс столбца | Да |
| outfile | Имя выходного файла. После экспорта каждый сегмент добавляет уникальный суффикс. Например, если файл назван tb1-f2.bin, на сегменте 1 он будет отображаться как tb1-f2.bin-seg1 |
Да |
| forkno | Номер вилки физического файла | Нет |
| offno | Байтовый сдвиг данных в физическом файле | Нет |
| limits | По умолчанию 100. Ограничивает количество экспортируемых RANGE, начиная с позиции, заданной forkno и offno |
Нет |
Примечание!
Параметрlimitsограничивает количество экспортируемых RANGE на каждом сегменте.
Примечание!
Сведения об этих параметрах см. в полях возврата функцииdesc_ranges.
Возвращаемые значения
nbytes: Объем экспортированных данных с каждого узла сегмента, в байтах.Пример
=# SELECT * FROM matrixts_internal.dump_ranges('tb1', 1, '/data/demo/tb1-f2.bin', 304, 16176, 1) LIMIT 20;
nbytes
--------
0
0
1480
1632
1704
1592
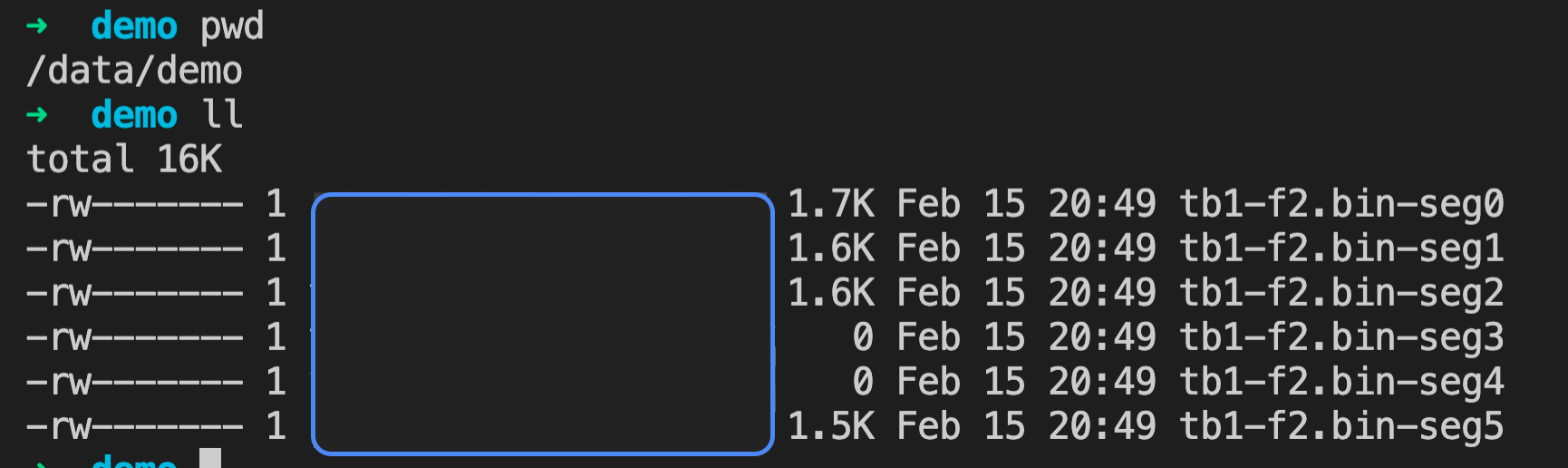
(6 rows)В этом примере возвращается шесть результатов, поскольку экспорт выполняется независимо на каждом сегменте. Каждая строка представляет результат одного сегмента. Две строки показывают nbytes как 0, что означает отсутствие совпадающих данных на этих сегментах.
После выполнения каждый хост, запускающий сегмент, генерирует двоичный файл с уникальным суффиксом, добавленным к исходному имени файла (.-seg<no>).
Функция desc_compress сравнивает два заданных пользователем алгоритма сжатия на непрерывном фрагменте физических данных в столбцовом хранилище MARS2.
Синтаксис
=# SELECT <* / column1,column2,...> FROM matrixts_internal.desc_compress(
tablename text,
attno int4,
<method1> text,
<method2> int4,
forkno int4,
offno int4,
limits int4
);Параметры
| Поле | Описание | Обязательно |
|---|---|---|
| tablename | Имя таблицы; для партиционированных таблиц используйте имя родительской таблицы | Да |
| attno | Индекс столбца | Да |
| Compression Method 1 | Например, zstd, lz4, deltadelta и т.д. | Да |
| Compression Method 2 | Например, zstd, lz4, deltadelta и т.д. | Да |
| forkno | Номер вилки физического файла | Нет |
| offno | Байтовый сдвиг данных в физическом файле | Нет |
| limits | По умолчанию 100. Количество RANGE для оценки, начиная с позиции, заданной forkno и offno |
Нет |
| Поле | Описание |
|---|---|
| segno | Номер сегмента, начинается с 0 |
| attno | Номер атрибута (индекс столбца), начинается с 0 |
| forkno | Номер вилки физического файла |
| offno | Байтовый сдвиг RANGE в физическом файле, начинается с 0. См. описание в desc_ranges. |
| nbytes | Фактический объем занимаемого SPACE в байтах |
| nrows | Значение compress_threshold, по умолчанию 1200. Это порог сжатия — максимальное количество кортежей в одном блоке сжатия. |
| nrowsnotnull | Количество ненулевых записей в RANGE |
| mmin | Минимальное значение в RANGE, если поддерживается minmax-индексирование; иначе NULL |
| mmax | Максимальное значение в RANGE, если поддерживается minmax-индексирование; иначе NULL |
| decompresstime0 | Время распаковки с использованием исходного алгоритма, в циклах CPU |
| compressedsize1 | Размер в байтах при сжатии с помощью <method1> |
| compressedtime1 | Время сжатия с помощью <method1>, в циклах CPU |
| selectiontime1 | Если <method1> — адаптивное кодирование (Auto), это время, затраченное на анализ характеристик данных (циклы CPU) |
| decompressedtime1 | Время распаковки с помощью <method1>, в циклах CPU |
| iscompressible1 | Эффективно ли сжатие с помощью <method1>. Если сжатый размер близок к исходному или больше, сжатие не рекомендуется. |
| dataloss1 | Происходит ли потеря точности при сжатии с помощью <method1> |
| compressedsize2 | Размер в байтах при сжатии с помощью <method2> |
| compressedtime2 | Время сжатия с помощью <method2>, в циклах CPU |
| selectiontime2 | Если <method2> — адаптивное кодирование, это время, затраченное на анализ характеристик данных (циклы CPU) |
| decompressedtime2 | Время распаковки с помощью <method2>, в циклах CPU |
| iscompressible2 | Эффективно ли сжатие с помощью <method2> |
| dataloss2 | Происходит ли потеря точности при сжатии с помощью <method2> |
lz4. Используйте desc_compress для анализа, какой алгоритм обеспечивает лучший коэффициент сжатия для столбца f1.=# SELECT compressedsize1,compressedsize2,dataloss1,dataloss2,compressedtime1,compressedtime2,iscompressible1,iscompressible2
FROM matrixts_internal.desc_compress(
'tb1', 0, 'lz4', 'deltadelta') limit 10;
compressedsize1 | compressedsize2 | dataloss1 | dataloss2 | compressedtime1 | compressedtime2 | iscompressible1 | iscompressibl
e2
-----------------+-----------------+-----------+-----------+-----------------+-----------------+-----------------+--------------
---
4835 | 975 | NO | NO | 275976 | 171902 | YES | YES
4848 | 1041 | NO | NO | 241742 | 111632 | YES | YES
4843 | 995 | NO | NO | 161580 | 123520 | YES | YES
4843 | 976 | NO | NO | 180704 | 118966 | YES | YES
4846 | 1009 | NO | NO | 157268 | 123994 | YES | YES
4844 | 1025 | NO | NO | 93118 | 70050 | YES | YES
4846 | 1018 | NO | NO | 91896 | 64120 | YES | YES
4843 | 997 | NO | NO | 89732 | 64062 | YES | YES
4845 | 1013 | NO | NO | 95010 | 71106 | YES | YES
4561 | 975 | NO | NO | 84664 | 82220 | YES | YES
(10 rows)Вывод показывает метрики сравнения для каждого RANGE в выбранном фрагменте данных. Очевидно, что алгоритм deltadelta обеспечивает значительно более высокий коэффициент сжатия для столбца f1 по сравнению с lz4, а также требует меньше времени на сжатие. Следовательно, использование deltadelta вместо lz4 в столбце f1 является явно лучшим выбором.