Быстрый старт
Развертывание
Моделирование данных
Подключение
Запись данных
Миграция
Запросы
Операции и обслуживание
Типовое обслуживание
Секционирование
Резервное копирование и восстановление
Масштабирование
Зеркалирование
Группы ресурсов
Безопасность
Мониторинг
Настройка производительности
Устранение неполадок
Справочник
Руководство по инструментам
Типы данных
Хранилище данных
Выполняющая система
Потоковая передача
Восстановление после сбоев
Конфигурация
Индексы
Расширения
Справочник по SQL
Часто задаваемые вопросы
YMatrix — это высокодоступная распределённая база данных, поддерживающая восстановление после сбоев узлов. Высокая доступность обеспечивается за счёт избыточного развертывания: узел Master должен иметь резервный узел Standby; для узлов данных (Segments) каждый узел Primary должен иметь соответствующий зеркальный узел Mirror.
Следующая диаграмма иллюстрирует типичное развертывание с высокой доступностью:
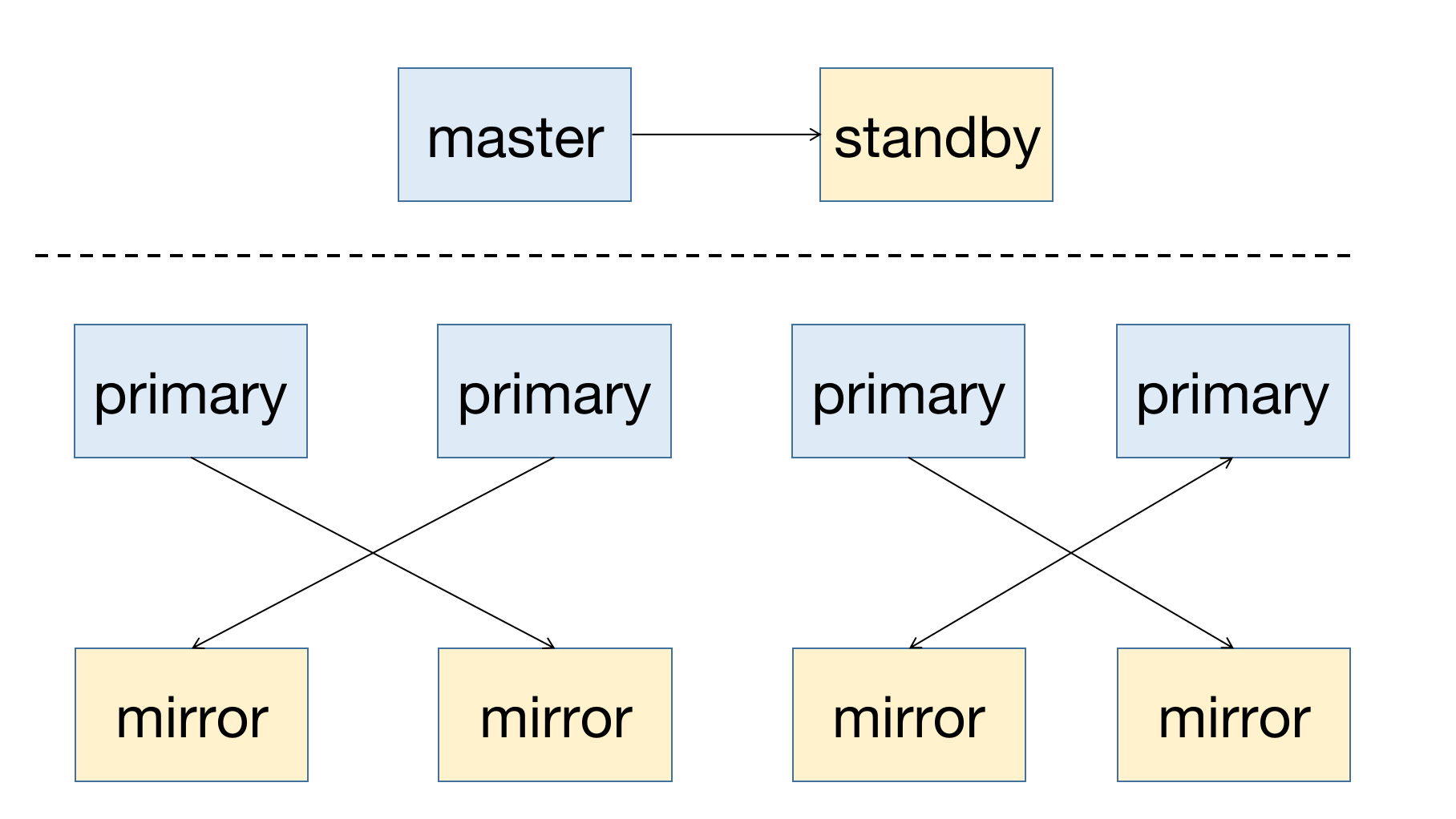
При сбое узла в кластере вы можете проверить статус узла через графический интерфейс (MatrixUI). В данном примере Master — mdw, Standby — smdw, а Segments — sdw1 и sdw2, каждый из которых имеет свой Mirror.
Принципы развертывания:
Такое развертывание исключает возможность отказа системы из-за сбоя одного хоста и обеспечивает балансировку нагрузки в кластере.
Ниже описаны механизмы автоматического обслуживания кластеров YMatrix и решения для различных сценариев сбоев узлов.
YMatrix поддерживает Cluster Service для автоматизированного обслуживания. Эта служба включает две ключевые функции: автоматический отказ (failover) и автоматическое восстановление (failback) (реализованы с помощью инструмента mxrecover). Вместе они обеспечивают полный цикл восстановления узлов.
Автоматический отказ — это механизм, при котором при обнаружении сбоя узла через проверки состояния кластера etcd система автоматически переключает роли между основным и резервным узлами. Кластер etcd является ключевым компонентом Cluster Service YMatrix и управляет состоянием всех узлов. При возникновении сбоя любого узла база данных автоматически выполняет отказ без участия оператора.
После завершения отказа остаётся активным только новый Primary/Master — здорового Mirror/Standby больше нет. При возникновении нового сбоя восстановление станет невозможным. Поэтому для создания нового здорового Mirror/Standby для повышенного Primary/Master используйте инструмент mxrecover.
Инструмент mxrecover предоставляет следующие функции:
Примечание!
Подробное использованиеmxrecoverсм. в документации mxrecover.
Когда система обнаруживает сбой узла Mirror/Standby, его статус в графическом интерфейсе изменяется на down.
Примечание!
Сбой Mirror не влияет на доступность кластера, поэтому система не восстанавливает его автоматически.
Для восстановления Mirror используйте инструментmxrecover— см. ниже.
Если время простоя было небольшим, а объём данных на отказавшем узле невелик, сначала попробуйте инкрементальное восстановление. Запуск mxrecover без параметров или с параметром только -c запускает режим инкрементального восстановления. Если инкрементальное восстановление не удаётся, выполните полную репликацию данных для восстановления узла с помощью команды mxrecover -F.
При сбое узла Primary система автоматически повышает его Mirror до роли Primary.
После того как система повысила Mirror/Standby до Primary, запустите mxrecover, чтобы создать новый Mirror/Standby для текущего Primary/Master и синхронизировать данные инкрементально или полностью, восстановив отказавший узел. Простой запуск mxrecover восстанавливает отказавший Mirror/Standby с использованием инкрементального восстановления. Как указано выше, используйте mxrecover -F, чтобы принудительно выполнить полное восстановление при необходимости.
[mxadmin@mdw ~]$ mxrecoverХотя mxrecover создаёт новый Mirror для повышенного Primary, это может привести к неравномерному распределению — один хост теперь управляет двумя узлами Primary (например, оба на sdw2). Это вызывает дисбаланс ресурсов и увеличивает нагрузку на sdw2.
Для перераспределения ролей выполните:
[mxadmin@mdw ~]$ mxrecover -rПосле выполнения mxrecover -r проверьте обновлённую конфигурацию на странице управления кластером графического интерфейса.
Отказ Master происходит в двух случаях:
Ниже подробно описано влияние отказа Master на различные компоненты и рекомендуемые действия для каждого сценария.
Это означает, что после сбоя Master произошёл отказ, и Standby теперь управляет кластером.
В этом случае обращайтесь к графическому интерфейсу на узле Standby. Адрес по умолчанию: http://<standbyIP>:8240.
Вы можете войти, используя либо пароль базы данных, либо пароль суперпользователя из файла mxadmin/etc/matrixdb6/auth.conf`` на узле Standby.

Все функции остаются полностью доступными после входа. Красный цвет слева указывает на отказавший узел; жёлтый — на завершённый отказ.
Это означает, что весь кластер недоступен. Вы всё ещё можете получить доступ к MatrixUI через узел Master для просмотра статуса, но функциональность запросов к базе данных будет ограничена.
Примечание!
Если в вашем кластере изначально не был настроен Standby, но позже он был добавлен с помощью инструментаmxinitstandby, поведение будет аналогично предварительно настроенному Standby.
Примечание!
В производственных средах всегда настраивайте Standby.
Произошёл отказ — Standby теперь управляет кластером.
Возможны два сценария:
MatrixGate размещён на хосте Master, который вышел из строя, и кластер стал неработоспособным.
В этом случае процесс MatrixGate считается умершим или изолированным от сети вместе с хостом.
MatrixGate автоматически перенаправляет вставку данных мониторинга на Standby. Мониторинг продолжается без перерывов — ручное вмешательство не требуется.
Для просмотра дашбордов Grafana вручную обновите источник данных, указав адрес Standby.
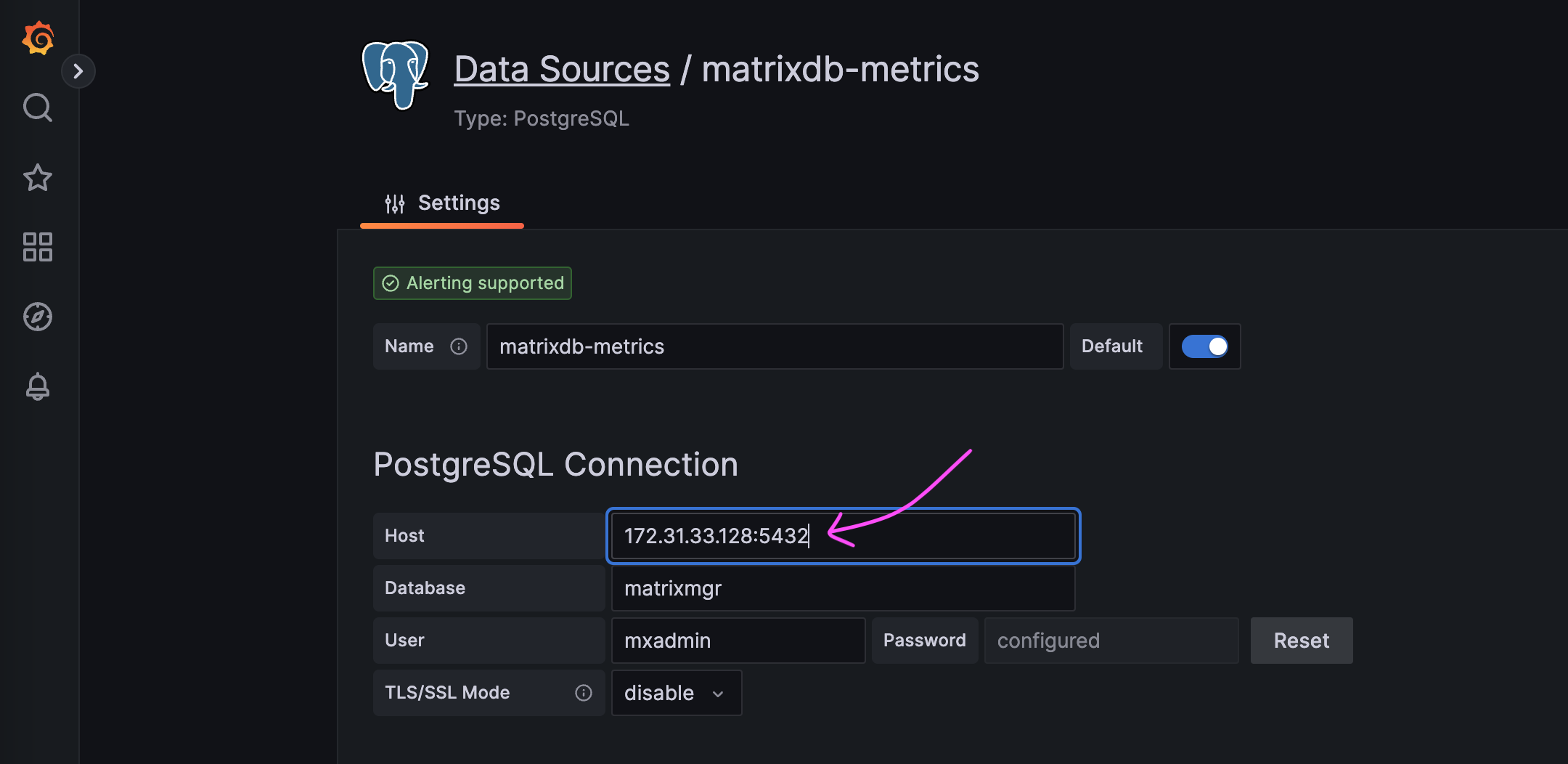
В этом случае экземпляр MatrixGate, используемый для мониторинга, вышел из строя, и новые данные мониторинга не будут генерироваться.