Начало работы
Подключение
Тесты производительности
Развёртывание
Использование данных
Управление кластерами
Обновление
Глобальное обслуживание
Масштабирование
Мониторинг
Безопасность
Лучшие практики
Технические принципы
Типы данных
Хранилище
Исполняющий движок
Потоковая обработка (Domino)
MARS3 Индексы
Расширения
Расширенные функции
Расширенный запрос
Федеративные запросы
Grafana
Резервное копирование и восстановление
Аварийное восстановление
Графовая база данных
Введение
Предложения
Функции
Расширенные темы
Руководство
Настройка производительности
Устранение неполадок
Инструменты
Параметры конфигурации
SQL-команда
Часто задаваемые вопросы
YMatrix 6 вводит etcd для хранения конфигурации и состояния кластера. etcd критически важен: любые аномалии могут привести к нестабильности базы данных или даже к сбоям системы.
В этом документе описано, как установить и развернуть мониторинг etcd. Мы рекомендуем настроить этот мониторинг для всех производственных кластеров, поскольку стабильное состояние etcd является обязательным условием для устойчивой работы базы данных.
Перейдите на официальный сайт Prometheus и скачайте следующее:
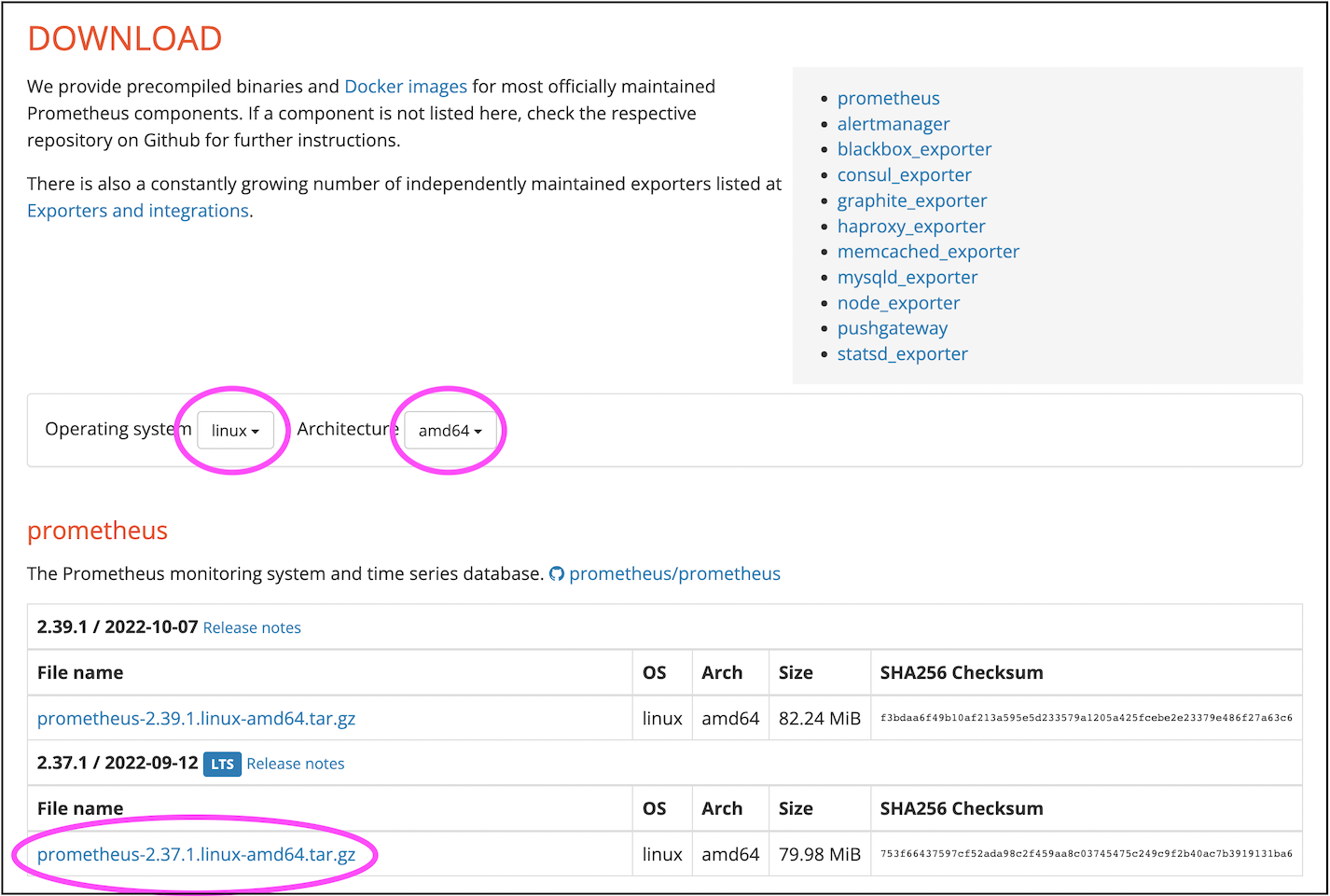
Загрузите скачанный tar-архив на Linux-сервер. При возможности запустите Prometheus на выделенном сервере. При ограниченных ресурсах временно разместите его на резервном или мастер-узле.
$ tar xvfz prometheus-*.tar.gzВы можете переместить извлечённую директорию prometheus-* в /usr/local/.
Отредактируйте конфигурационный файл:
$ cd prometheus-*
sudo vi prometheus.ymlДобавьте в конец файла следующий контент:
- job_name: "etcd"
static_configs:
- targets: ["172.31.33.128:4679", "172.31.45.253:4679", "172.31.35.134:4679"]Массив targets необходимо заменить адресами всех узлов etcd в вашем кластере.
Эту информацию можно найти в файле /etc/matrixdb6/physical_cluster.toml на мастер-узле:
$ cat physical_cluster.toml
cluster_id = '79LhQxjuwmXgSWZCjcdigF'
supervisord_grpc_port = 4617
deployer_port = 4627
etcd_endpoints = ['http://10.0.159.1:4679', 'http://10.0.172.185:4679', 'http://10.0.170.90:4679', 'http://10.0.146.2:4679', 'http://10.0.146.195:4679', 'http://10.0.150.110:4679', 'http://10.0.169.149:4679']Примечание!
Если файл/etc/matrixdb6/physical_cluster.tomlотсутствует и не обнаруживается процесс etcd, ваш кластер был развернут не с использованием архитектуры 6.x и не требует мониторинга etcd.
./prometheus --config.file=prometheus.ymlПримечание!
Как правило, Prometheus следует запускать как фоновую системную службу, настроив её как systemd-службу.
Следуйте официальной документации по установке Grafana.
Примечание!
Требуется Grafana версии 8.2.5 или выше.
Сначала войдите в веб-интерфейс Grafana. Стандартный URL:
http://<IP_or_domain_of_the_host>:3000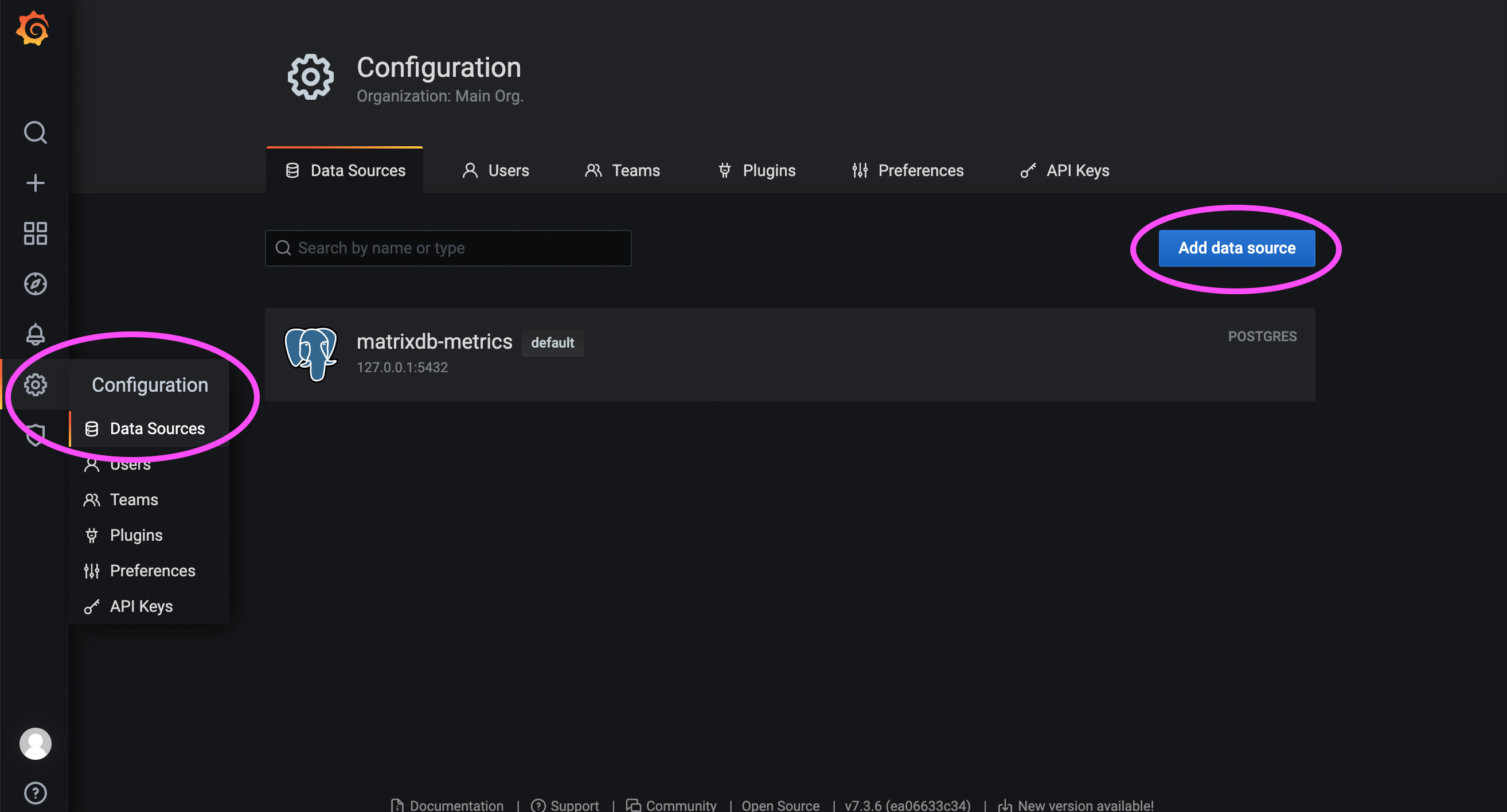
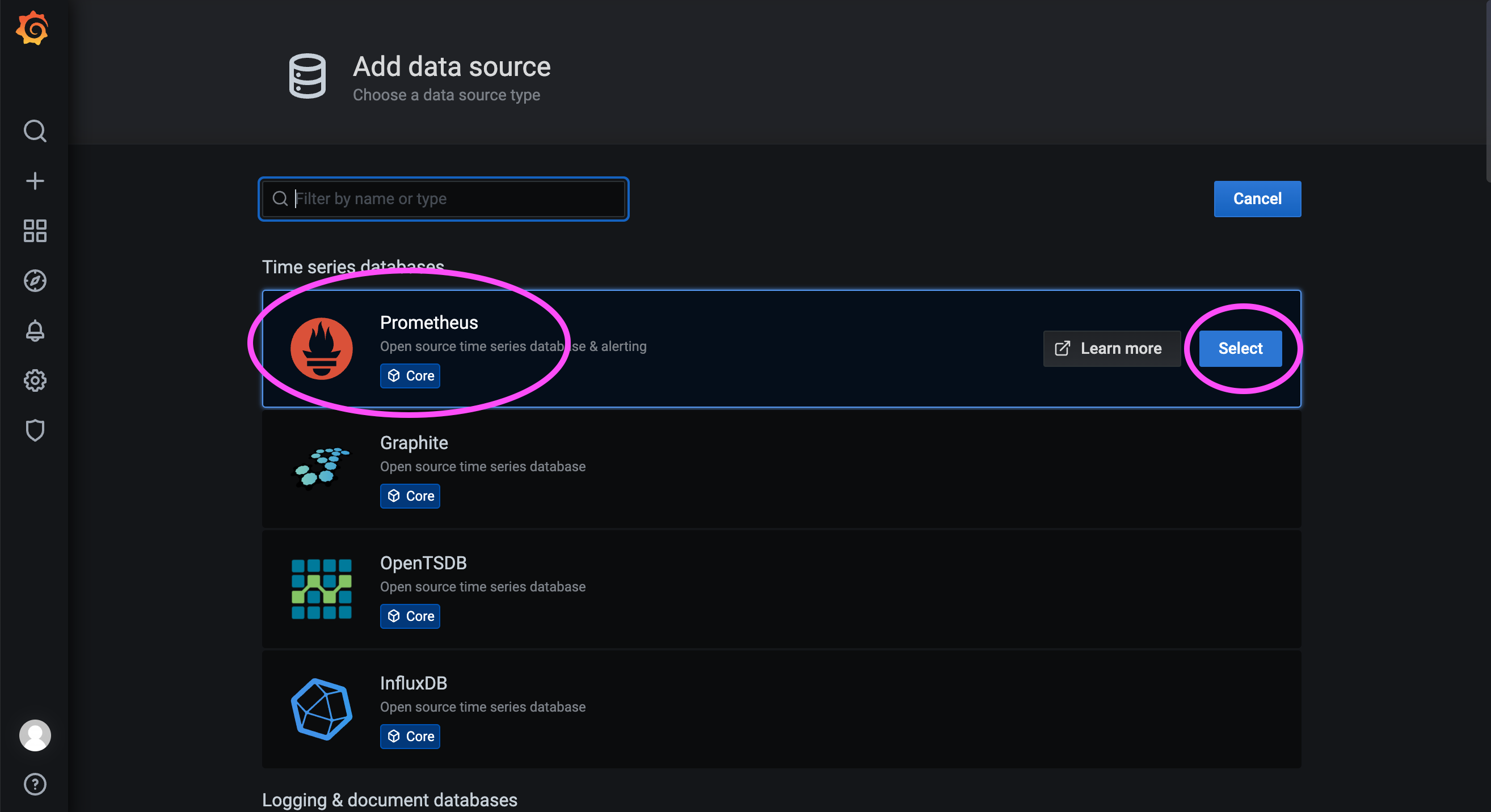

172.31.23.21:9090 — это порт сервиса Prometheus, развернутого на предыдущем шаге.
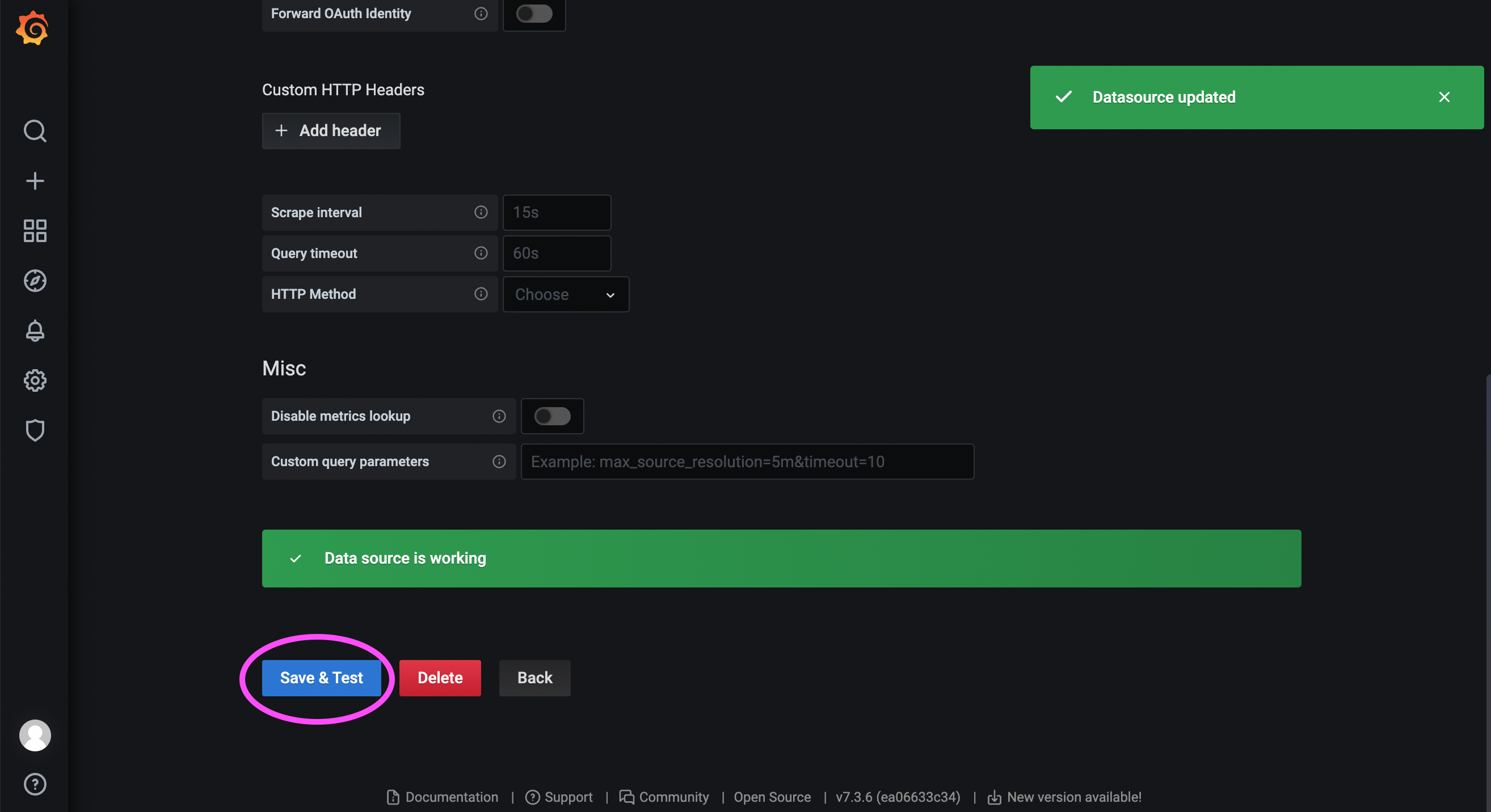
Перейдите на сообщество Grafana:
https://grafana.com/grafana/dashboards/?search=Etcd+Cluster+Overview
На этой странице представлены дашборды, предоставленные сообществом:
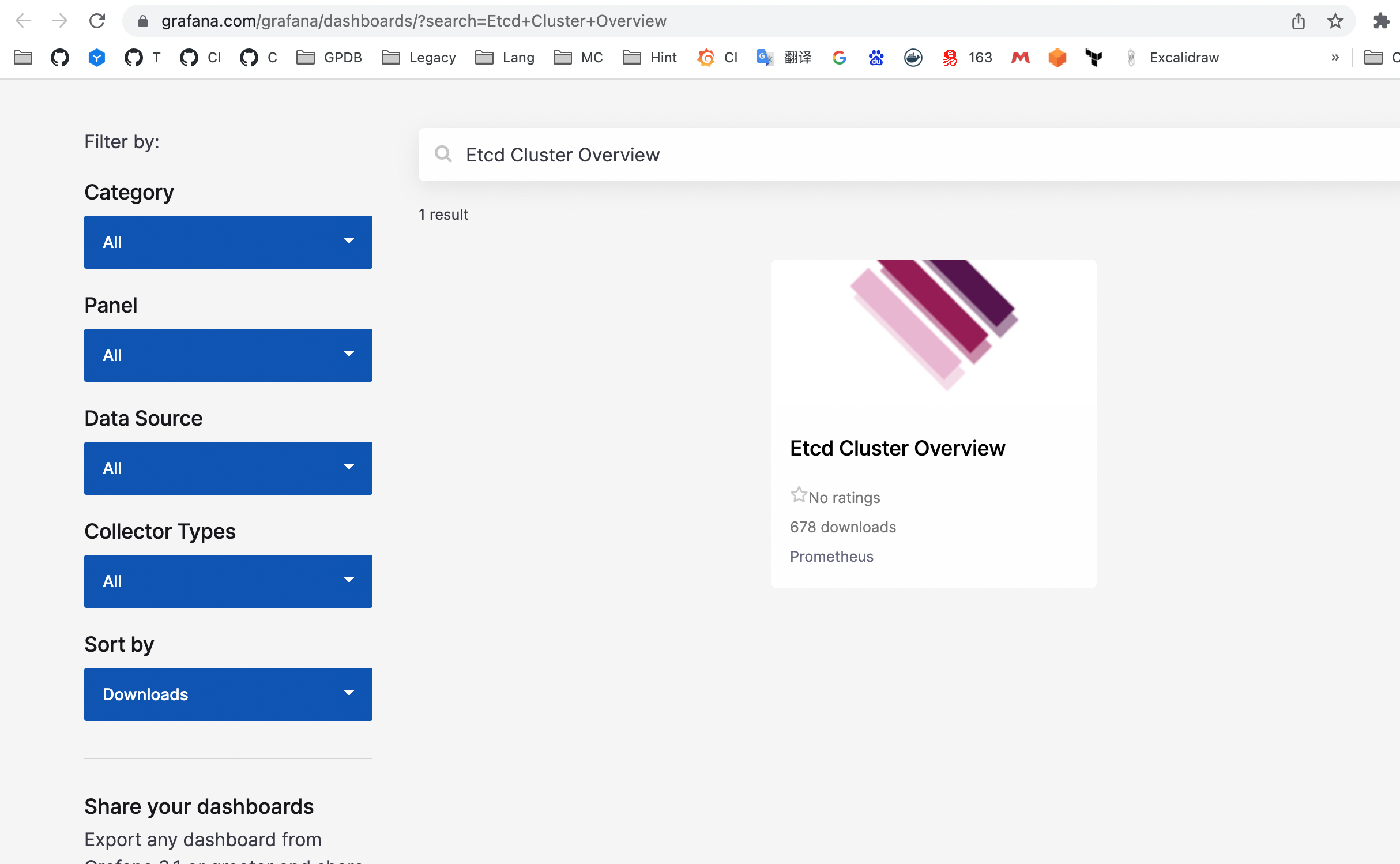
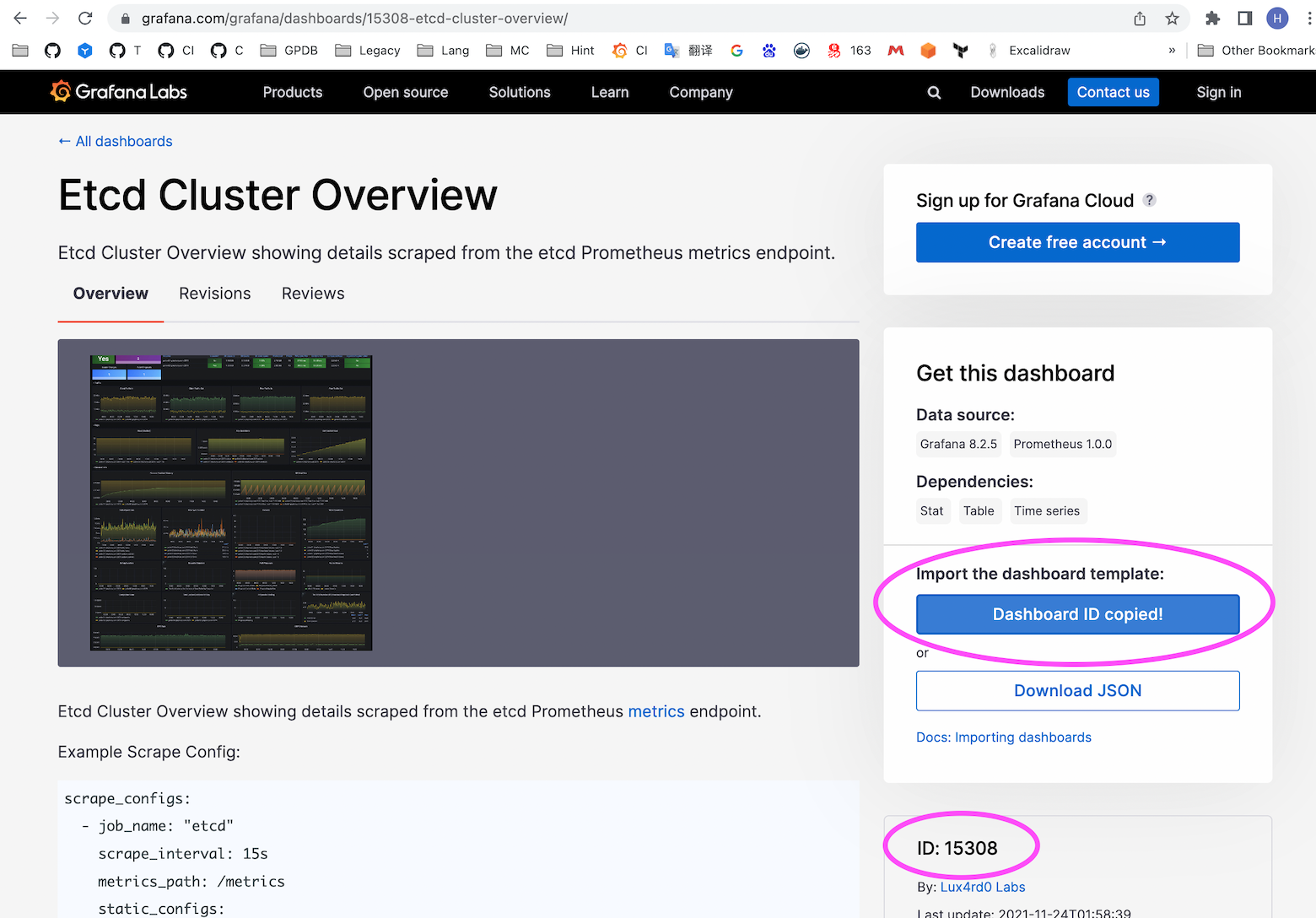
Щёлкните по нужному дашборду, чтобы получить его ID:
Примечание!
ID дашборда может со временем измениться. В настоящее время ID — 15308; пользователи должны проверять актуальность по результатам поиска.
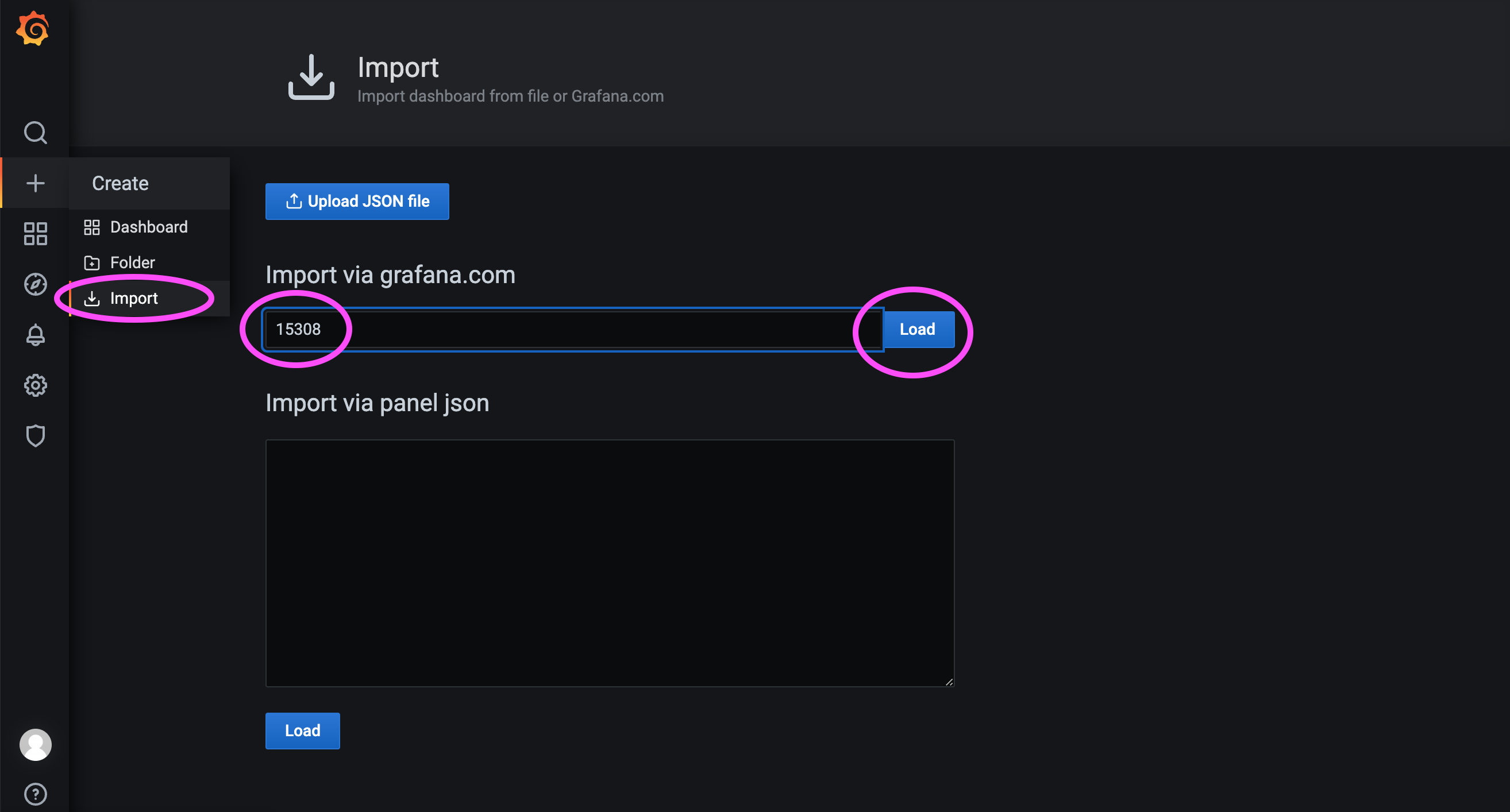
Как показано ниже, импортируйте дашборд с ID 15308:
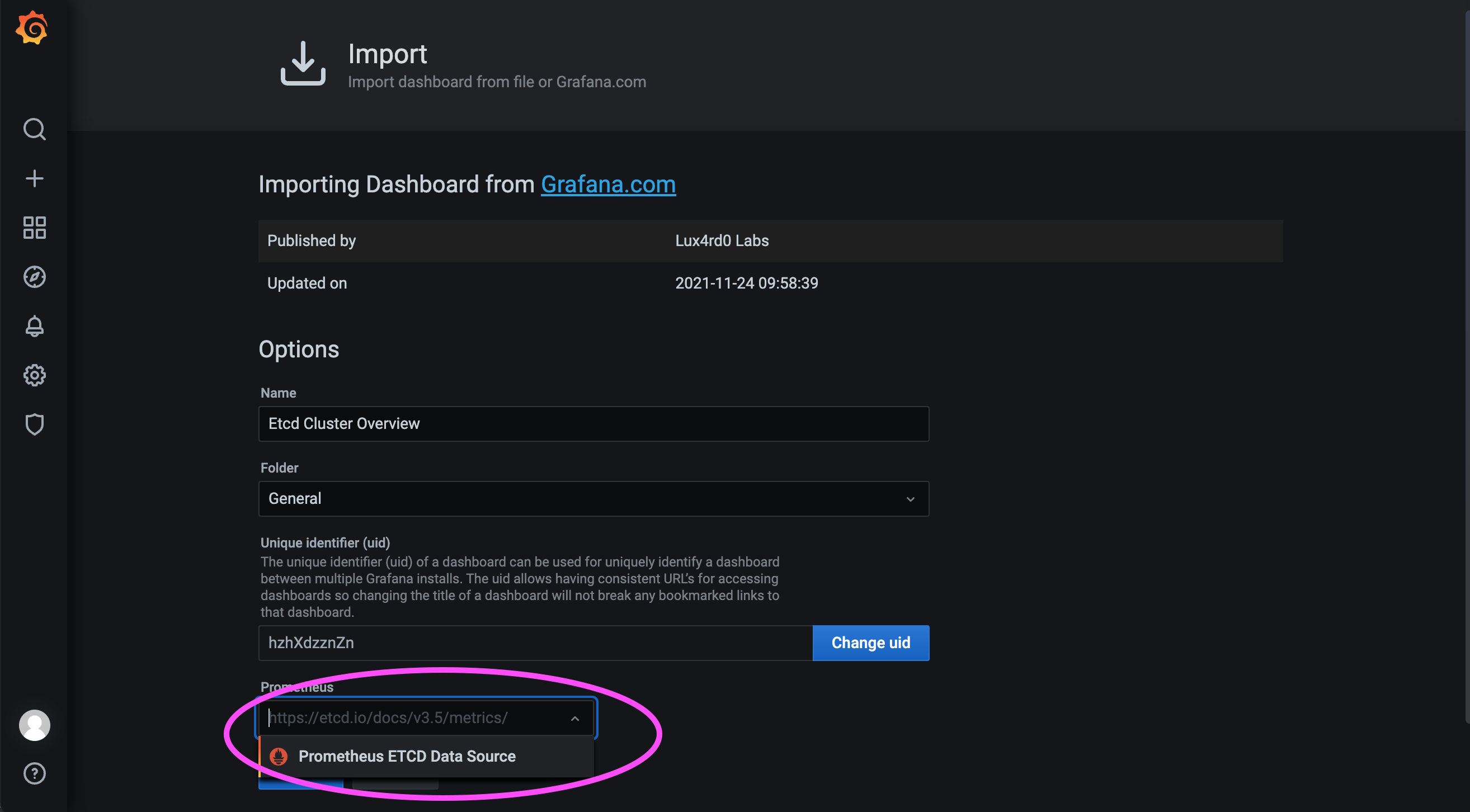
Затем выберите ранее настроенный источник данных и загрузите дашборд:
Если сервер находится во внутренней сети, импорт по ID 15308 может не сработать. В этом случае скачайте JSON-файл дашборда с машины, подключённой к интернету, и импортируйте его вручную:
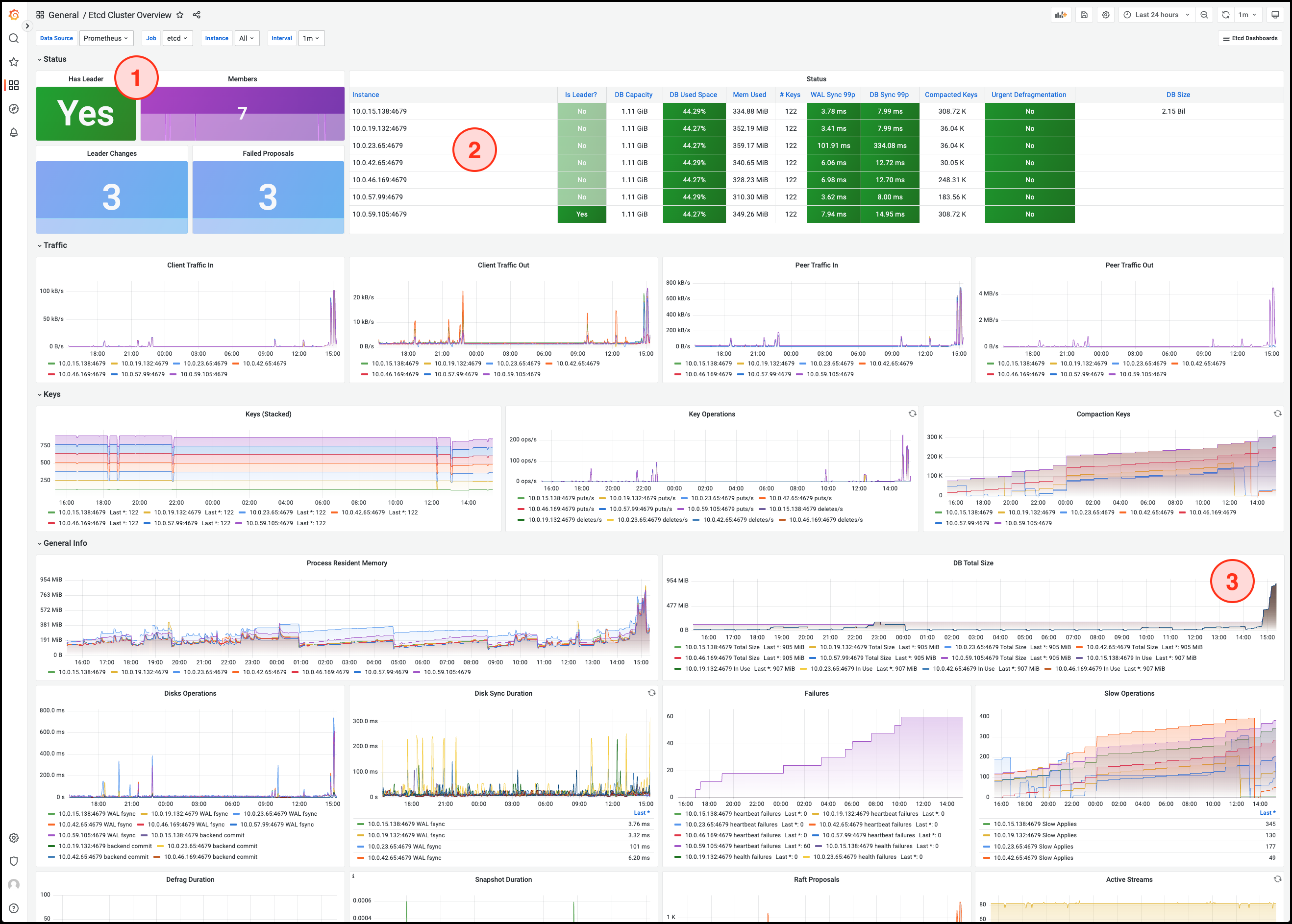
Статус службы etcd и количество участников
Список кворумных участников и статус процессов
Общий размер БД показывает рост данных etcd во времени. Аномальное увеличение может привести к достижению лимита размера базы.
Примечание!
Для получения дополнительных метрик и подробных пояснений обратитесь к официальной документации etcd.