A database stores data. After completing table modeling and selecting appropriate storage types, the next step is to write data into tables.
Data ingestion faces the following challenges:
The most prominent feature of time series data is its large volume. In practical applications, this manifests in three aspects:
Given the vast number of devices and high-frequency metric collection, the resulting data volume is enormous, posing a significant challenge to database throughput.
MatrixDB provides MatrixGate, a high-speed data ingestion tool. By leveraging parallel data loading across MXSegment nodes, MatrixGate achieves an ingestion rate of up to 50 million data points per second.
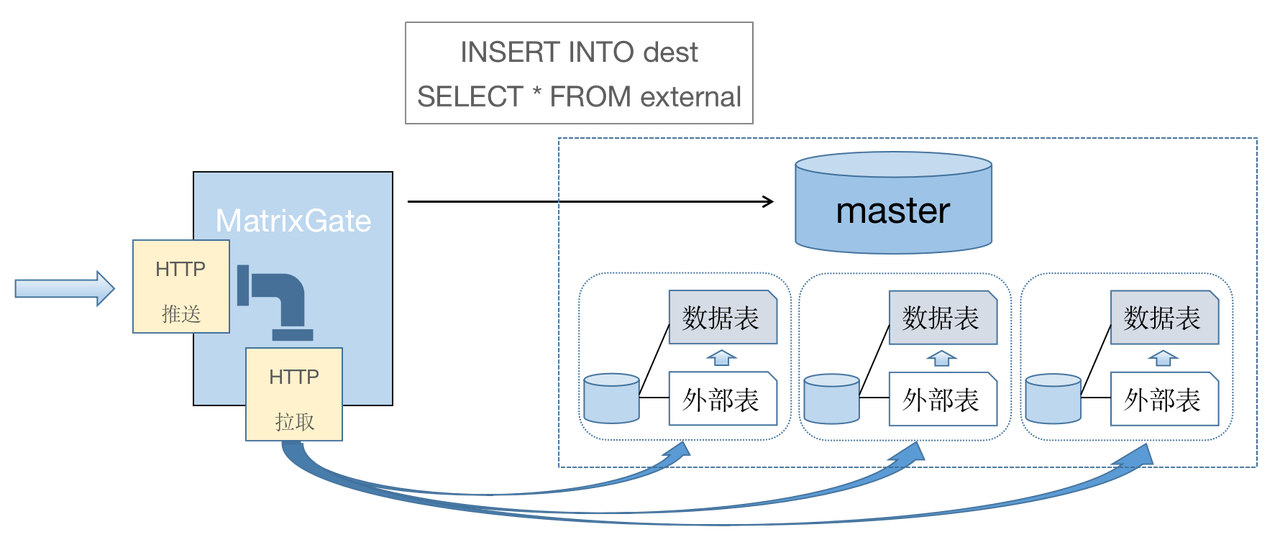
For implementation details, refer to:
MatrixDB - How MatrixDB Achieves 50 Million Data Points Per Second on a Single Node
For benchmarking results, refer to:
MatrixDB - Time Series Database Insert Performance Benchmark: MatrixDB is 78x Faster Than InfluxDB
In real-world deployments, data ingestion involves not only massive volumes and diverse sources, but also complex edge cases such as:
In certain scenarios, all metrics collected by a device at a given timestamp are not sent in a single batch, but transmitted incrementally over multiple transmissions. These partial updates must be merged into a single record rather than stored as separate rows.
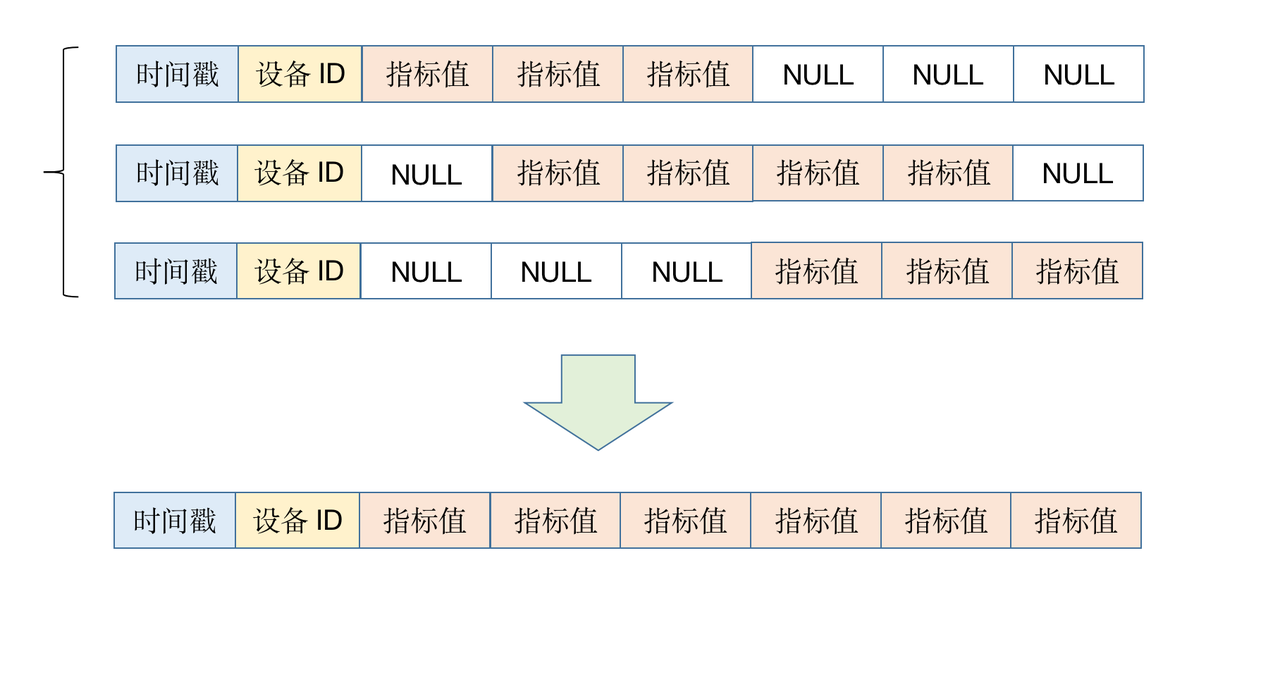
To address this, MatrixDB supports UPSERT semantics, enabling data merge operations based on unique constraints. For usage instructions, see:
MatrixDB - Understanding UPSERT: A New Feature in MatrixDB 4.2
Out-of-order and delayed data arrivals are also handled using UPSERT functionality.
Mixed-frequency reporting refers to different metrics from the same device being collected at different intervals — for example, one metric every 1 second, another every 2 seconds. As shown below:
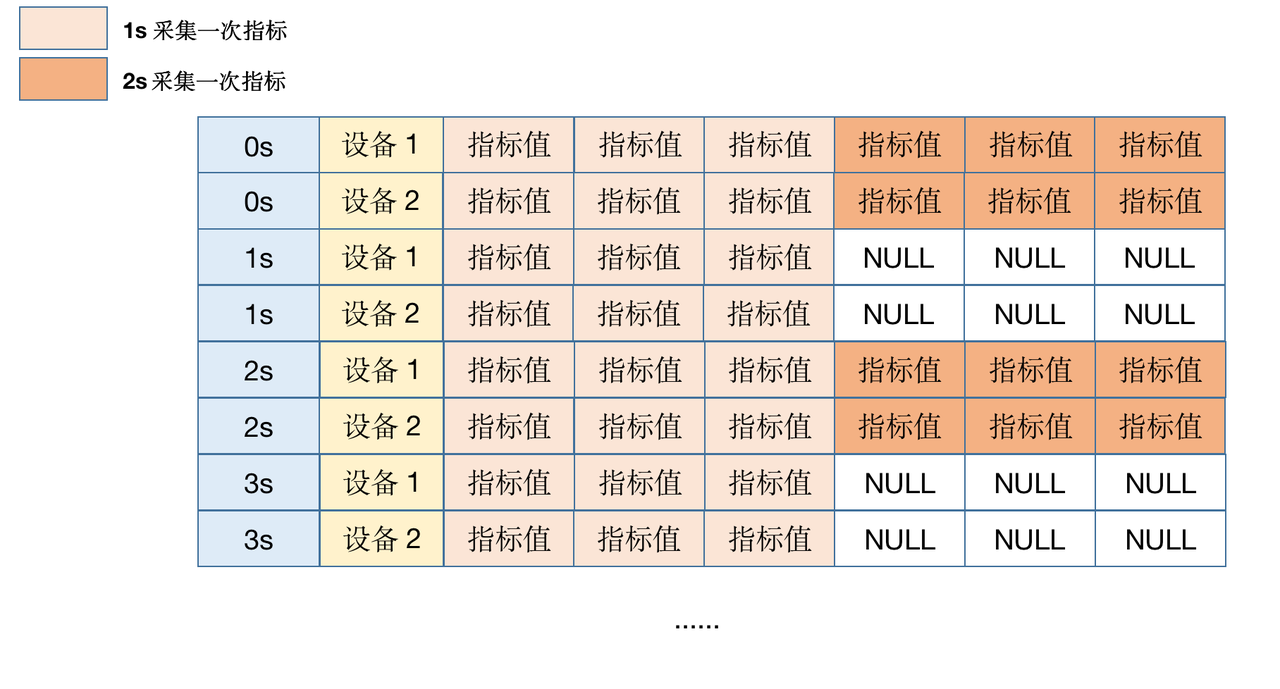
This leads to numerous NULL values in the stored data for low-frequency metrics. In MatrixDB, any column containing NULL still consumes storage space:
[number of columns / 8] bytes [number of rows in RowGroup / 8] bytes Therefore, when dealing with frequent NULLs, storage efficiency should be carefully evaluated and optimized accordingly.