YMatrix — это высокодоступная распределённая база данных, поддерживающая восстановление после отказа узлов. Предпосылкой высокой доступности является избыточное развертывание: узел Master должен иметь резервный узел (Standby); для узла данных (Segment) Primary является основным узлом, и ему требуется соответствующий зеркальный узел (Mirror).
Схема развертывания системы с высокой доступностью приведена ниже:
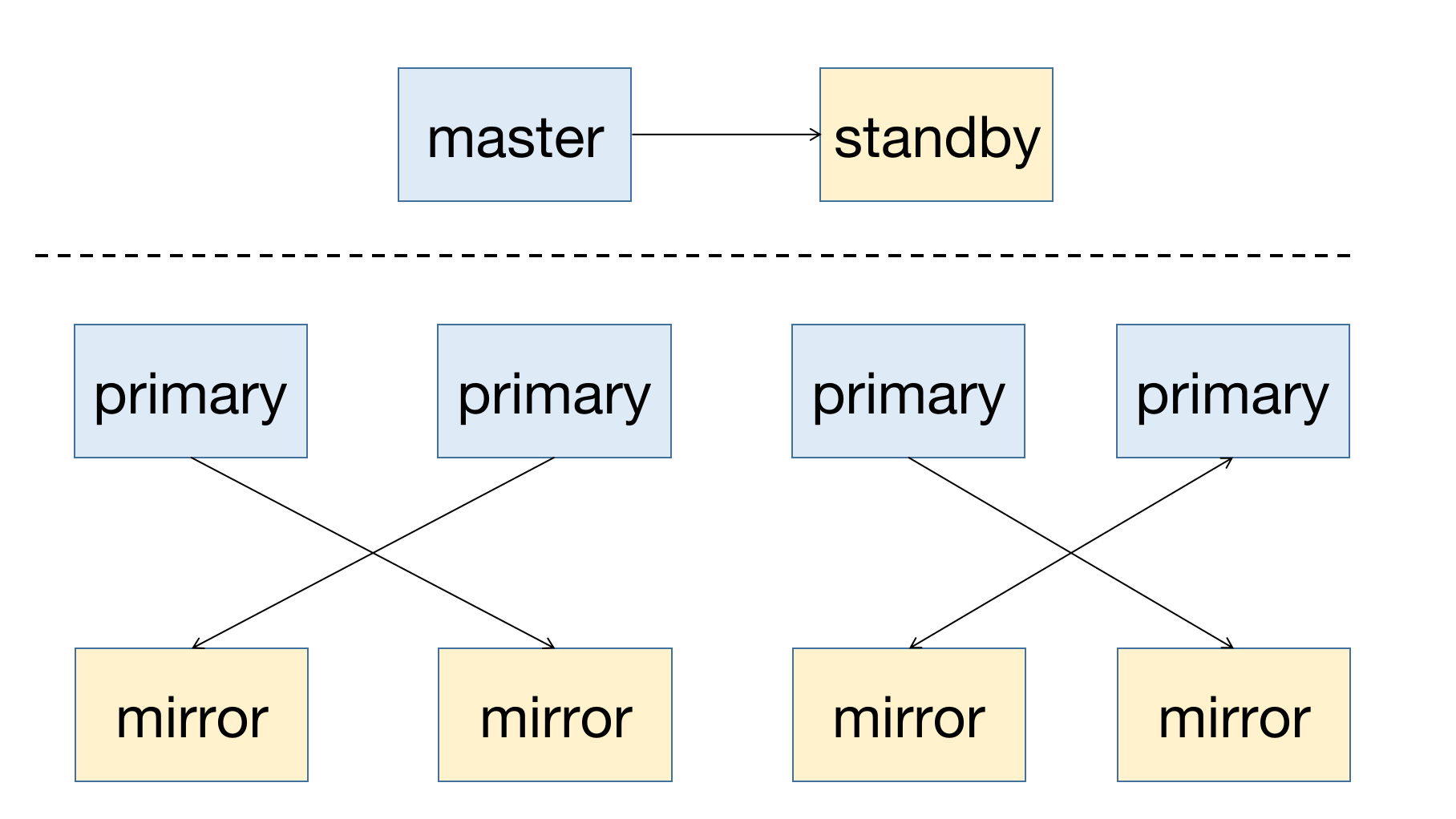
При отказе узла в кластере вы можете получить информацию о статусе узла через графический интерфейс (MatrixUI). В примере кластера Master — mdw, Standby — smdw, Segment — sdw1 и sdw2, каждый из которых имеет соответствующий Mirror.
Статус развертывания:
Данный метод развертывания предотвращает недоступность системы при отказе одного хоста и распределяет нагрузку по кластеру.
Далее кратко описаны принципы автоматического обслуживания кластера YMatrix и решения для различных сценариев отказа узлов разных ролей.
YMatrix поддерживает сервис кластера для автоматизации обслуживания. Этот сервис включает две основные функции: Failover и Failback, реализованные с помощью инструмента mxrecover. Используя эти функции, можно полностью восстановить работу после отказа узла.
Автоматический отказ от отказавшего узла — это механизм в системе автоматического обслуживания, который переключает основной и резервный узлы на основе диагностической информации о состоянии узлов, полученной из кластера etcd. Кластер etcd является ключевым компонентом службы состояния кластера YMatrix и отвечает за управление информацией о состоянии всех узлов. При отказе любого узла в кластере система автоматически выполняет переключение без вмешательства пользователя.
После завершения автоматического отказа соответствующий узел содержит только Primary/Master, но отсутствует здоровый резервный узел. При повторном отказе восстановление невозможно. Поэтому необходимо использовать инструмент mxrecover для создания здоровых Mirror/Standby для нового Primary/Master.
Инструмент mxrecover выполняет следующие функции:
Примечание!
Подробности использования инструмента mxrecover см. в документации: mxrecover.
Когда система обнаруживает, что Mirror / Standby недоступен, статус узла в графическом интерфейсе изменяется на down.
Примечание!
Отказ Mirror не приводит к недоступности кластера, поэтому система не активирует Mirror автоматически.
Для активации Mirror необходимо использовать инструментmxrecover. Подробности ниже.
Если интервал простоя короткий, а объём данных на отказавшем узле невелик, рекомендуется сначала попробовать инкрементальное восстановление. Инкрементальный режим используется, когда после команды mxrecover не указаны параметры или указан только -c. Если инкрементальное восстановление не удаётся, необходимо выполнить полное восстановление путём копирования всех данных — используйте команду mxrecover -F.
Когда система обнаруживает отказ Primary, соответствующий Mirror автоматически повышается до роли Primary.
После автоматического повышения Mirror/Standby выполните mxrecover, чтобы создать соответствующий Mirror/Standby для нового Primary/Master и синхронизировать данные узла полностью или инкрементально, восстановив отказавший узел. Выполните mxrecover для немедленной активации отказавшего Mirror/Standby и инкрементного восстановления данных. Как указано выше, если требуется полное восстановление, используйте команду mxrecover -F.
[mxadmin@mdw ~]$ mxrecoverХотя mxrecover создал новый Mirror для Primary-узла, это привело к новой проблеме: распределение Primary-узлов изменилось, и оба Primary-узла теперь находятся на sdw2. Это вызывает неравномерное распределение ресурсов хостов, и sdw2 будет нести повышенную нагрузку.
Команда для перераспределения:
[mxadmin@mdw ~]$ mxrecover -rПосле выполнения mxrecover -r вы можете проверить результат на странице управления кластером в графическом интерфейсе.
Автоматический отказ Master происходит в двух случаях:
Ниже описано влияние автоматического отказа Master на различные компоненты и рекомендуемые действия в этих сценариях.
В этом случае отказ автоматически переключает Master на Standby, который берёт на себя управление кластером.
Пользователь должен подключиться к графическому интерфейсу на узле Standby, как указано в подсказках. Стандартный адрес: http://<standbyIP>:8240.
Войти можно с использованием пароля базы данных mxadmin или суперпользователя /etc/matrixdb5/auth.conf на узле Standby.
Все функции остаются полностью доступными после входа. Красный цвет слева означает отказавший узел; жёлтый — завершённый отказ.
Это означает, что весь кластер недоступен. Вы всё ещё можете получить доступ к MatrixUI через узел Master для просмотра статуса, но функциональность запросов к базе данных ограничена.
Примечание!
Если ваш кластер изначально не имел настроенного Standby, но позже был добавлен с помощью инструментаmxinitstandby, поведение будет аналогично предварительно настроенному Standby.
Примечание!
В производственных средах всегда настраивайте Standby.
В этом случае отказ автоматически переключает Master на Standby, который берёт на себя управление кластером.
Здесь возможны два сценария влияния:
В этом случае MatrixGate должен работать на узле Master, который отказался, что привело к недоступности кластера.
В этом сценарии процесс MatrixGate можно считать завершившимся вместе с хостом или изолированным от сети других узлов на отключённом хосте.
В этом случае MatrixGate автоматически переключается на запись данных в Standby, и данные мониторинга продолжают сохраняться нормально без вмешательства пользователя.
Если необходимо просмотреть страницу мониторинга Grafana, необходимо вручную изменить источник данных и указать адрес Standby.

В этом случае сервис MatrixGate, отвечающий за мониторинг, завершил работу, и новые данные мониторинга не генерируются.