Архитектура YMatrix
Документ описывает следующие аспекты архитектуры YMatrix:
-
Глобальная архитектура
- Гиперконвергентная архитектура
- Архитектура базы данных
-
Локальная архитектура
- Архитектура высокой доступности
Обзор
Чтобы снизить сложность экосистемы данных, YMatrix разработала простую архитектуру с гиперконвергентными компонентами, интегрирующую вычислительные, хранилищные и сетевые ресурсы в единую систему. Она основана на системе массово параллельной обработки (MPP) и соответствует принципам архитектуры микроядра.
Эта архитектура гибка и адаптируется к различным сценариям. Она не только оптимизирована для сценариев IoT с временными рядами, но и поддерживает традиционные аналитические хранилища данных и задачи бизнес-аналитики (BI).
Преимущества
Замена традиционных стеков технологий данных гиперконвергентными архитектурами может показаться сложной задачей. Зачем тогда это нужно?
На самом деле, независимо от ситуации, комплексное применение гиперконвергентных архитектур может принести выгоду многим предприятиям, обеспечивая унифицированную основу для сложных ИТ-систем, включая умные подключенные автомобили, промышленный интернет, умное производство, умные города, энергетику, финансы и фармацевтику.
По сравнению со сложными стеками технологий данных, такими как экосистема Hadoop, архитектура YMatrix предлагает следующие преимущества:
-
Гиперконвергенция
- Надежность: Сложный технологический стек обычно состоит из N отдельных систем обработки данных. Предположим, что вероятность сбоя любого компонента равна P, тогда стабильность всей системы может быть приближенно оценена как (1-P)^N, что означает, что каждый дополнительный компонент значительно снижает стабильность. Гиперконвергентная архитектура, использующая одну систему, по своей природе является наиболее стабильной и надежной.
- Экономичность: Благодаря гиперконвергентной природе, YMatrix может потреблять и управлять данными в рамках одной системы, не требуя передачи данных между несколькими распределенными системами, тем самым избегая необходимости хранить данные в нескольких системах. Физические требования к оборудованию, такие как диски, минимальны, что приводит к низкой стоимости хранения.
- Актуальность: В гиперконвергентной архитектуре данные не требуют передачи между несколькими системами, что обеспечивает низкую задержку и высокую актуальность.
- Упрощенное управление: Гиперконвергентное решение делает всю экосистему данных проще в управлении, исключая необходимость в экспертизе по множеству продуктов и языков программирования — для эксплуатации достаточно базовых знаний SQL.
-
Высокая доступность
- При отказе нескольких узлов служба управления состоянием YMatrix автоматически выполняет переключение на резервный узел без вмешательства человека, что делает процесс прозрачным для бизнеса. Это снижает ваши трудозатраты и уменьшает человеческий риск.
-
Богатая экосистема инструментов
- Совместима с экосистемой Postgres/Greenplum. Охватывает множество сценариев, включая миграцию данных, запись, тестирование производительности, резервное копирование и восстановление.
-
Поддержка стандартного SQL
- Поддерживает стандарт SQL:2016, включая типы данных, скалярные выражения, выражения запросов, наборы символов, правила распределения данных, операторы множеств и другие элементы.
-
Полная поддержка транзакций ACID
- Обеспечивает целостность и согласованность данных, исключая необходимость в сложной проверке и обработке ошибок на уровне пользователя, снижая вашу операционную нагрузку.
Гиперконвергентная архитектура
Обзор
В отличие от баз данных с другими архитектурами, гиперконвергенция YMatrix проявляется в интеграции множества типов данных и операций, обеспечивая высокопроизводительную поддержку множества типов данных + множества сценариев в рамках одной базы данных. Внутренняя архитектура YMatrix обладает микроядерными характеристиками. Основываясь на общих базовых компонентах, она предоставляет различные комбинации движков хранения и выполнения, адаптированные под требования различных бизнес-сценариев, что позволяет различным микроядрам достигать целенаправленного улучшения производительности записи, хранения и запросов.
Диаграмма
Ниже представлена диаграмма, описывающая состав и функции гиперконвергентной архитектуры в YMatrix:
_1696644131.png)
Следующие разделы содержат подробный обзор компонентов гиперконвергентной архитектуры YMatrix.
- Общие ядерные компоненты
Это в основном общие ресурсы базы данных, такие как управление памятью, протоколы сетевого взаимодействия и базовые структуры данных.
- Движки хранения и выполнения
Это комбинации движков хранения и выполнения, которые можно выбрать при создании таблиц в YMatrix для различных сценариев. Каждая комбинация может формировать микроядро.
- Оптимизатор
Преобразует строку SQL в план запроса и генерирует оптимальный план на основе возможностей выбранного нижележащего движка хранения.
- Журналирование, транзакции, управление конкурентностью, блокировки, снимки
Это стандартные компоненты ядра YMatrix, обеспечивающие общие функции, такие как контроль конкурентности, механизмы транзакций и восстановление после сбоев.
- SQL
Это стандартный SQL-интерфейс между YMatrix и клиентом.
- Аутентификация, роли, аудит, шифрование, мониторинг, резервное копирование, восстановление, высокая доступность
Это другие распространенные функции базы данных, поддерживаемые YMatrix.
Архитектура базы данных
Обзор
Высокоуровневая архитектура базы данных YMatrix основана на классической архитектуре MPP (массово параллельной обработки) с некоторыми улучшениями.
Диаграмма
Ниже представлена диаграмма, описывающая ключевые компоненты, составляющие систему базы данных YMatrix, и их взаимодействие:
_1693302582.png)
Следующие разделы содержат подробное описание различных компонентов системы базы данных YMatrix и их функций.
- Узел Master
- Отвечает за установление и управление сессионными соединениями с клиентами.
- Отвечает за разбор SQL-запросов и формирование планов запросов (Query Plan).
- Распределяет планы запросов на Segments, контролирует процесс выполнения запросов и собирает результаты для возврата клиентам.
- Master не хранит бизнес-данные; он хранит только словарь данных, то есть совокупность определений и атрибутов всех элементов данных, используемых в системе.
- В кластере допускается только один Master; может использоваться конфигурация основной-резервной копии, при этом резервный узел называется Standby.
- Узлы данных (Segments)
- Отвечают за хранение и распределение выполнения SQL-запросов.
- Ключ к достижению оптимальной производительности YMatrix заключается в равномерном распределении данных и нагрузки по большому числу Segment-узлов с одинаковыми возможностями, что позволяет всем Segment-узлам одновременно начать выполнение задачи и завершить её параллельно.
- Клиент
- Общий термин, обозначающий любое устройство, клиентское приложение или программу, способную подключаться к базе данных.
- MatrixGate
- MatrixGate (сокращённо mxgate) — это высокоскоростной инструмент записи потоковых данных YMatrix. Подробнее см. mxgate.
- Сетевой уровень (Interconnect)
- Сетевой уровень в архитектуре базы данных, отвечающий за межпроцессное взаимодействие между Segments и инфраструктуру сети, поддерживающую такое взаимодействие.
- Служба управления состоянием данных (Cluster Service)
- Cluster Service обеспечивает высокую доступность базы данных, управляя информацией о состоянии узлов. YMatrix использует кластер ETCD для реализации этой службы: при отказе узла базы данных ETCD извлекает сохранённые данные о состоянии узла, определяет текущий работоспособный узел как новый основной и повышает его статус, чтобы обеспечить доступность кластера.
Например, если отказывает узел Master, его Standby узел повышается до статуса Master; если отказывает Standby узел, это не влияет на весь кластер. Аналогично, если отказывает основной узел Primary, его зеркальный узел Mirror повышается до Primary; если отказывает сам Mirror, это не влияет на весь кластер. Подробнее см. Восстановление после сбоев.
Архитектура высокой доступности
Обзор
YMatrix использует собственную технологию ALOHA (Advanced Least Operation High Availability) для обеспечения высокой доступности кластера. При возникновении единичной точки отказа в кластере соответствующий резервный экземпляр автоматически переключает свою роль и заменяет отказавший экземпляр, обеспечивая бесперебойную работу кластера.
| Отказавший узел | Влияние | Время |
| Mirror | При отказе Mirror не влияет на запросы пользователей к данным соответствующего Primary, но отказавший Mirror необходимо восстановить вручную | Секунды в сети с подключением |
| Standby | При отказе Standby узла не влияет на запросы пользователей к данным кластера, но отказавший Standby необходимо восстановить вручную |
| Primary | При отказе Primary узла пользователи не могут выполнять запросы к соответствующим данным и должны ждать, пока система автоматически не повысит соответствующий Mirror до статуса Primary |
| Master | При отказе Master кластер становится недоступным, пользователи не могут выполнять запросы к данным и должны ждать, пока система автоматически не повысит соответствующий Standby до статуса Master |
Примечание!
Подробные шаги по восстановлению после сбоев см. в разделе Восстановление после сбоев.
Принцип работы
Службы ALOHA используют архитектуру высокой доступности на основе кластеров ETCD. Эта архитектура решает проблему автоматического переключения, что по сути означает реализацию механизма автоматического выбора главного узла и поддержание строгой согласованности данных.
Этот механизм включает следующие этапы:
- Сбор данных о состоянии
Существуют два источника данных, передаваемых в ETCD кластером данных:
- Регулярное обнаружение и передача данных независимо от наличия сбоев в кластере
- Обнаружение сбоя кластера и немедленная передача данных процессом службы
- Хранение данных о состоянии
Данные о состоянии хранятся в кластере ETCD. ETCD — это зрелое распределённое решение для хранения, реализованное на основе протокола Raft. Как уровень хранения состояния, он может предоставлять надёжную и уникальную информацию о состоянии кластера для управления и контроля процессов в случае сбоя.
Примечание!
Кластеры ETCD выполняют больше операций с диском при хранении состояния, поэтому идеально использовать несколько отдельных физических машин для развертывания кластера ETCD, что полностью гарантирует производительность ETCD. Однако на практике количество физических машин может быть недостаточным для независимого развертывания ETCD, поэтому нечётное количество экземпляров ETCD случайным образом размещается на некоторых или всех физических машинах в кластере данных для хранения состояния узлов и экземпляров.
- Управление процессами
На основе распределённого и согласованного хранения, предоставляемого ETCD, процесс postmaster, входящий в API-уровень, получает в реальном времени состояние каждого экземпляра. Таким образом, при возникновении сбоя роли различных основных и резервных экземпляров мгновенно перераспределяются, минимизируя влияние сбоя.
Схематическая диаграмма:
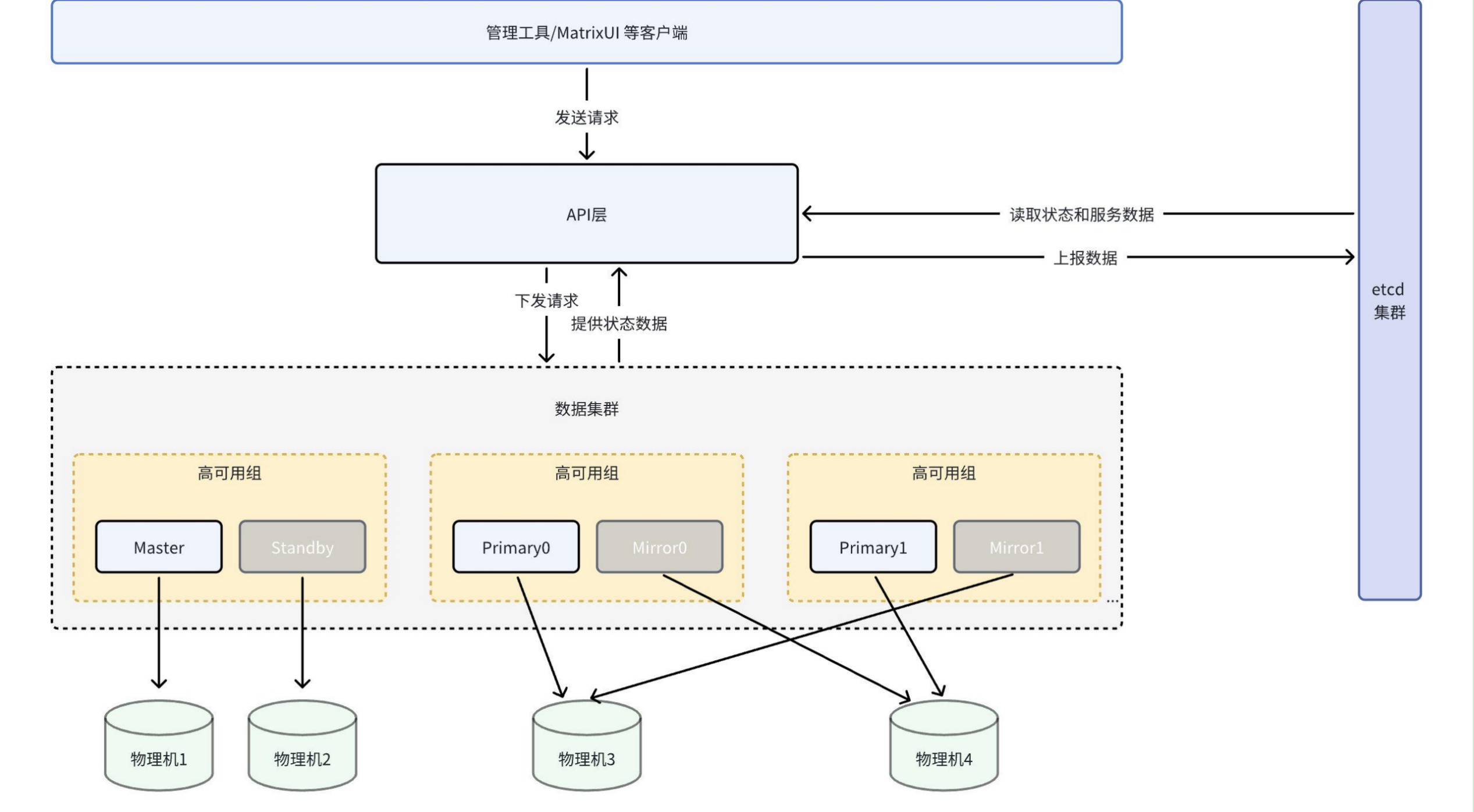
Вы можете увидеть:
- Клиенты, такие как инструменты управления или MatrixUI, отправляют запросы на API-уровень;
- API-уровень отправляет запросы в кластер данных, который предоставляет данные о состоянии API-уровню;
- API-уровень передаёт данные о состоянии кластера в кластер ETCD и также может читать данные о состоянии и сервисах из кластера ETCD.
Приложение
ETCD
ETCD — это распределённый кластер хранения ключ-значение, используемый для хранения и извлечения данных в распределённых системах. ETCD использует алгоритм согласованности Raft для обеспечения согласованности и надёжности данных. Он разработан для обеспечения высокой доступности и сильных возможностей восстановления после сбоев. ETCD предоставляет простой RESTful API-интерфейс, позволяющий приложениям легко получать доступ к ключ-значению и манипулировать ими.
Важные понятия:
- Leader: Руководитель кластера ETCD, выбирается и является уникальным.
- Follower: Подчинённый, синхронизирует журналы, полученные от лидера; по умолчанию находится в этом состоянии при запуске ETCD.
- Candidate: Кандидат, способный инициировать выборы лидера.