MatrixDB is a highly available distributed database system that supports failure recovery after node downtime. The premise of high availability is redundant deployment, so the master node needs to have a standby node as backup; for segment nodes, primary is the main node, and there needs to be a corresponding mirror node. The deployment diagram of a highly available system is as follows:
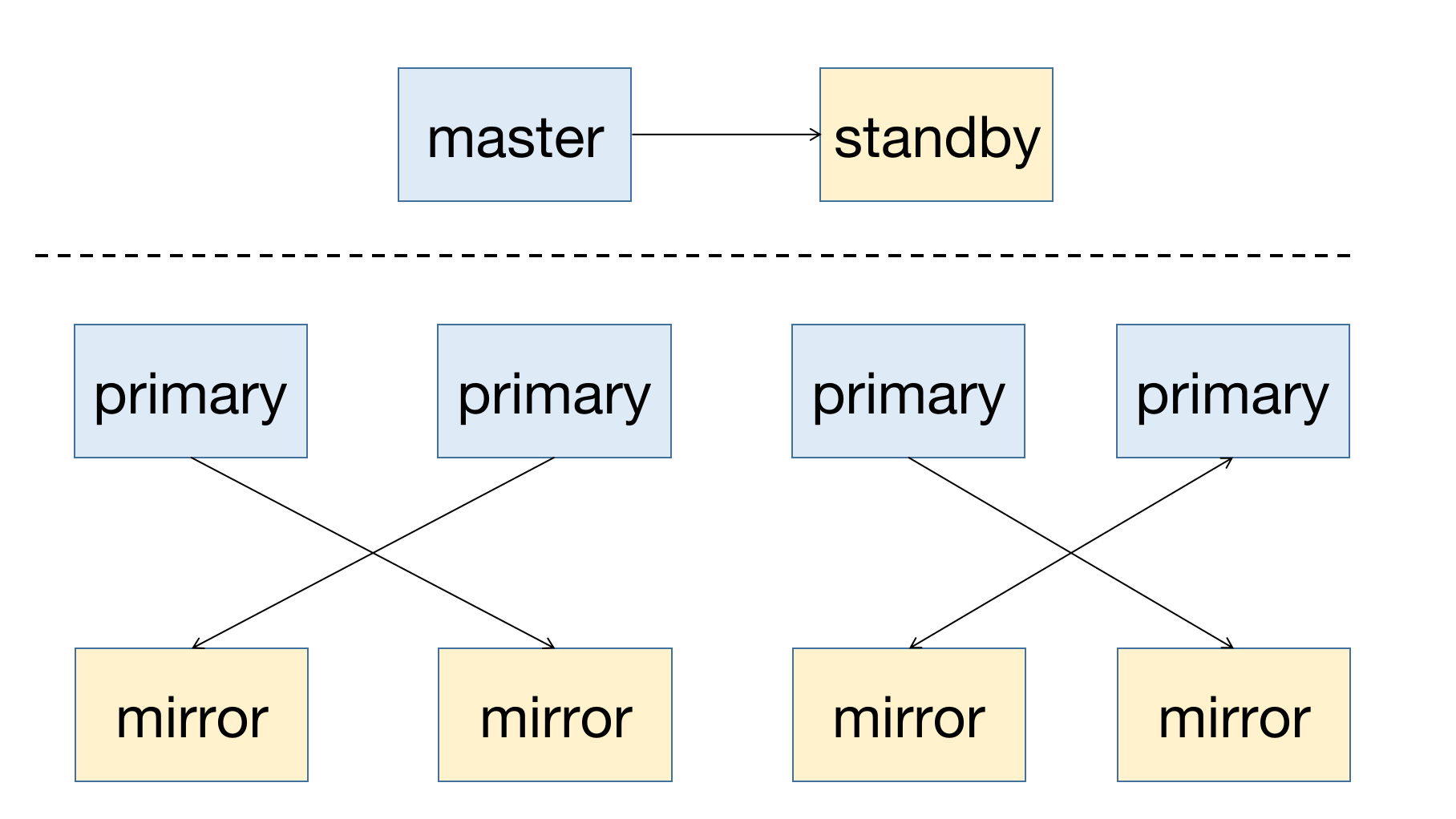
Whether it is a master node or a segment node, its corresponding backup node must be deployed to different hosts to prevent the cluster from being unavailable by a single host failure.
FTS (Fault Tolerance Service) is an affiliate process of the master node, which is used to manage the status of the segment node. When a segment node (primary or mirror) fails, the FTS process will automatically recover the fault. You can query the gp_segment_configuration table to get the node status:
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
-----+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | -1 | p | p | n | u | 5432 | mdw | mdw | /mxdata/master/mxseg-1
6 | -1 | m | m | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | p | p | s | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | m | m | s | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)The column description is as follows:
| Column Name | Description |
|---|---|
| dbid | node ID, incremented from 1 |
| content | Master and slave node pair number, master and standby are -1 Segment node pair increments from 0 |
| role | node role, p is the main and m is the slave |
| preferred_role | Node initial role |
| mode | Synchronous situation |
| status | Node status, u is survival, d is downtime |
| port | port |
| hostname | hostname |
| address | Host address |
| datadir | Data directory |
From the deployment situation, you can see:
The above deployment method is to avoid the system unavailability caused by single host failure and disperse the pressure on the cluster.
When FTS finds that the mirror node is down, the node status will be marked as d in the gp_segment_configuration table.
Because the mirror downtime will not cause the cluster to be unavailable, FTS will not do other operations. Reactivate the mirror requires the
gprecoversegcommand, which will be explained later.
From the following query, we can see that when the mirror node with dbid=4 goes down, its status becomes d.
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
-----+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | -1 | p | p | n | u | 5432 | mdw | mdw | /mxdata/master/mxseg-1
6 | -1 | m | m | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | p | p | n | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | m | m | n | d | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)When FTS finds that the primary node is down, the mirror node corresponding to the promote will be primary. By querying the gp_segment_configuration table, we can see that the role of the node has changed and the state has also changed.
From the following query, we can see that after the primary node with dbid=2 goes down, the mirror node with dbid=4 is promote to primary. The role and preferred_role are no longer equal to segment pairs with content=0, which means that the role is no longer the initial role and the node state has undergone corresponding changes.
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
-----+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | -1 | p | p | n | u | 5432 | mdw | mdw | /mxdata/master/mxseg-1
6 | -1 | m | m | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | m | p | n | d | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | p | m | n | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)FTS will diagnose the segment node status and make a master-preparatory switch when primary downtime. However, after the main and standby switch, only primary will exist for the corresponding segment node pair. If there is another failure, it cannot be restored. Therefore, mirror nodes need to be generated again for the new primary. At this time, the gprecoverseg tool needs to be used.
The gprecoverseg tool has the following functions:
Directly execute gprecoverseg to activate the downtime mirror:
[mxadmin@mdw ~]$ gprecoverseg
20210908:14:40:18:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Starting gprecoverseg with args:
20210908:14:40:18:012136 gprecoverseg:mdw:mxadmin-[INFO]:-local Greenplum Version: 'postgres (MatrixDB) 4.2.0-community (Greenplum Database) 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d'
20210908:14:40:18:012136 gprecoverseg:mdw:mxadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 12 (MatrixDB 4.2.0-community) (Greenplum Database 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180303 (Red Hat 7.3.1-5), 64-bit compiled on Sep 1 2021 03:15:53'
20210908:14:40:18:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Obtaining Segment details from master...
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Heap checksum setting is consistent between master and the segments that are candidates for recoverseg
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Greenplum instance recovery parameters
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Recovery type = Standard
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Recovery 1 of 1
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Synchronization mode = Incremental
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance host = sdw2
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance address = sdw2
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance directory = /mxdata/mirror/mxseg0
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance port = 6001
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance host = sdw1
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance address = sdw1
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance directory = /mxdata/primary/mxseg0
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance port = 6000
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Target = in-place
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
Continue with segment recovery procedure Yy|Nn (default=N):
> y
20210908:14:40:20:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Starting to modify pg_hba.conf on primary segments to allow replication connections
20210908:14:40:23:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Successfully modified pg_hba.conf on primary segments to allow replication connections
20210908:14:40:23:012136 gprecoverseg:mdw:mxadmin-[INFO]:-1 segment(s) to recover
20210908:14:40:23:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Ensuring 1 failed segment(s) are stopped
20210908:14:40:24:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Updating configuration with new mirrors
20210908:14:40:24:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Updating mirrors
20210908:14:40:24:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Running pg_rewind on required mirrors
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Starting mirrors
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-era is 494476b1be478047_210908141632
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Commencing parallel segment instance startup, please wait...
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Process results...
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Triggering FTS probe
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Updating segments for streaming is completed.
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-For segments updated successfully, streaming will continue in the background.
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Use gpstate -s to check the streaming progress.
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************After the primary node is down and FTS completes the mirror's promote, executing gprecoverseg can generate the corresponding mirror for the new primary. At this time, query the gp_segment_configuration table:
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
-----+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | -1 | p | p | n | u | 5432 | mdw | mdw | /mxdata/master/mxseg-1
6 | -1 | m | m | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | m | p | s | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | p | m | s | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)It can be seen that for segment node pairs with content=0, primary and mirror are active. However, the current role and the initial role have been swapped. That's because after the mirror is converted into a primary node and then performing gprecoverseg, the new mirror node reuses the original downtime primary node.
Although gprecoverseg regenerates mirror for the new primary node, it also brings a new problem. The distribution relationship of primary nodes has changed, and both primary nodes are distributed on sdw2. This will lead to:
Therefore, the main and slave redistribution must be done, which also reflects the role of the preferred_role column to record the initial role.
The redistribution command is as follows:
[mxadmin@mdw ~]$ gprecoverseg -r
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Starting gprecoverseg with args: -r
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-local Greenplum Version: 'postgres (MatrixDB) 4.2.0-community (Greenplum Database) 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d'
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 12 (MatrixDB 4.2.0-community) (Greenplum Database 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180303 (Red Hat 7.3.1-5), 64-bit compiled on Sep 1 2021 03:15:53'
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Obtaining Segment details from master...
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Greenplum instance recovery parameters
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Recovery type = Rebalance
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Unbalanced segment 1 of 2
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance host = sdw2
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance address = sdw2
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance directory = /mxdata/mirror/mxseg0
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance port = 6001
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Balanced role = Mirror
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Current role = Primary
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Unbalanced segment 2 of 2
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance host = sdw1
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance address = sdw1
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance directory = /mxdata/primary/mxseg0
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance port = 6000
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Balanced role = Primary
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Current role = Mirror
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[WARNING]:-This operation will cancel queries that are currently executing.
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[WARNING]:-Connections to the database however will not be interrupted.
Continue with segment rebalance procedure Yy|Nn (default=N):
> y
20210908:15:24:05:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Getting unbalanced segments
20210908:15:24:05:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Stopping unbalanced primary segments...
20210908:15:24:06:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Triggering segment reconfiguration
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Starting segment synchronization
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-=============================START ANOTHER RECOVER=========================================
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-local Greenplum Version: 'postgres (MatrixDB) 4.2.0-community (Greenplum Database) 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d'
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 12 (MatrixDB 4.2.0-community) (Greenplum Database 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180303 (Red Hat 7.3.1-5), 64-bit compiled on Sep 1 2021 03:15:53'
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Obtaining Segment details from master...
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Heap checksum setting is consistent between master and the segments that are candidates for recoverseg
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Greenplum instance recovery parameters
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Recovery type = Standard
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Recovery 1 of 1
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Synchronization mode = Incremental
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance host = sdw2
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance address = sdw2
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance directory = /mxdata/mirror/mxseg0
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance port = 6001
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance host = sdw1
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance address = sdw1
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance directory = /mxdata/primary/mxseg0
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance port = 6000
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Target = in-place
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Starting to modify pg_hba.conf on primary segments to allow replication connections
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Successfully modified pg_hba.conf on primary segments to allow replication connections
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-1 segment(s) to recover
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Ensuring 1 failed segment(s) are stopped
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Updating configuration with new mirrors
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Updating mirrors
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Running pg_rewind on required mirrors
20210908:15:24:17:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Starting mirrors
20210908:15:24:17:012918 gprecoverseg:mdw:mxadmin-[INFO]:-era is 494476b1be478047_210908141632
20210908:15:24:17:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Commencing parallel segment instance startup, please wait...
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Process results...
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Triggering FTS probe
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Updating segments for streaming is completed.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-For segments updated successfully, streaming will continue in the background.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Use gpstate -s to check the streaming progress.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-==============================END ANOTHER RECOVER==========================================
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-The rebalance operation has completed successfully.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-There is a resynchronization running in the background to bring all
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-segments in sync.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Use gpstate -e to check the resynchronization progress.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************After executing gprecoverseg -r, query the database:
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
-----+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | -1 | p | p | n | u | 5432 | mdw | mdw | /mxdata/master/mxseg-1
6 | -1 | m | m | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | p | p | n | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | m | m | n | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)It can be seen that the role of the segment node pair with content=0 has returned to its initial state.
For detailed usage of gprecoverseg, please refer to Document
If the master node fails, the database will not be able to establish connections and use, and can only activate the standby node as the new master node.
The activation method is as follows:
[mxadmin@smdw ~]$ export PGPORT=5432
[mxadmin@smdw ~]$ export MASTER_DATA_DIRECTORY=/mxdata/standby/mxseg-1
[mxadmin@smdw ~]$ gpactivatestandby -d /mxdata/standby/mxseg-1
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Running Command: ps -ef | grep 'postgres -D /mxdata/standby/mxseg-1' | grep -v grep
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:------------------------------------------------------
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Standby data directory = /mxdata/standby/mxseg-1
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Standby port = 5432
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Standby running = yes
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Force standby activation = no
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:------------------------------------------------------
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Running Command: cat /tmp/.s.PGSQL.5432.lock
Do you want to continue with standby master activation? Yy|Nn (default=N):
> y
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Running Command: ps -ef | grep 'postgres -D /mxdata/standby/mxseg-1' | grep -v grep
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-found standby postmaster process
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Promoting standby...
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Running Command: pg_ctl promote -D /mxdata/standby/mxseg-1
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Waiting for connection...
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Standby master is promoted
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Reading current configuration...
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Connecting to db template1 on host localhost
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:------------------------------------------------------
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-The activation of the standby master has completed successfully.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-smdw is now the new primary master.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-You will need to update your user access mechanism to reflect
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-the change of master hostname.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Do not re-start the failed master while the fail-over master is
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-operational, this could result in database corruption!
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-MASTER_DATA_DIRECTORY is now /mxdata/standby/mxseg-1 if
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-this has changed as a result of the standby master activation, remember
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-to change this in any startup scripts etc, that may be configured
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-to set this value.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-MASTER_PORT is now 5432, if this has changed, you
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-may need to make additional configuration changes to allow access
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-to the Greenplum instance.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Refer to the Administrator Guide for instructions on how to re-activate
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-the master to its previous state once it becomes available.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Query planner statistics must be updated on all databases
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-following standby master activation.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-When convenient, run ANALYZE against all user databases.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:------------------------------------------------------After activate standby, query the database and you can see that the original standby node has become a master and there is no new standby node:
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
-----+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
6 | -1 | p | p | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | p | p | s | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | m | m | s | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(5 rows)After standby is activated as master, the corresponding standby backup needs to be generated for the new master node to prevent the downtime again.
Initializing standby requires the gpinitstandby command.
The following command initializes a standby node with running port 5432 in the /home/mxadmin/standby directory on mdw:
[mxadmin@smdw ~]$ gpinitstandby -s mdw -S /home/mxadmin/standby -P 5432
20210908:15:38:54:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Validating environment and parameters for standby initialization...
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Checking for data directory /home/mxadmin/standby on mdw
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:------------------------------------------------------
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum standby master initialization parameters
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:------------------------------------------------------
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum master hostname = smdw
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum master data directory = /mxdata/standby/mxseg-1
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum master port = 5432
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum standby master hostname = mdw
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum standby master port = 5432
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum standby master data directory = /home/mxadmin/standby
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum update system catalog = On
Do you want to continue with standby master initialization? Yy|Nn (default=N):
> y
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Syncing Greenplum Database extensions to standby
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[WARNING]:-Syncing of Greenplum Database extensions has failed.
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[WARNING]:-Please run gppkg --clean after successful standby initialization.
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Adding standby master to catalog...
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Database catalog updated successfully.
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Updating pg_hba.conf file...
20210908:15:38:58:004367 gpinitstandby:smdw:mxadmin-[INFO]:-pg_hba.conf files updated successfully.
20210908:15:38:59:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Starting standby master
20210908:15:38:59:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Checking if standby master is running on host: mdw in directory: /home/mxadmin/standby
20210908:15:39:00:004367 gpinitstandby:smdw:mxadmin-[INFO]:-MasterStart pg_ctl cmd is env GPSESSID=0000000000 GPERA=None $GPHOME/bin/pg_ctl -D /home/mxadmin/standby -l /home/mxadmin/standby/log/startup.log -t 600 -o " -p 5432 -c gp_role=dispatch " start
20210908:15:39:01:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Cleaning up pg_hba.conf backup files...
20210908:15:39:02:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Backup files of pg_hba.conf cleaned up successfully.
20210908:15:39:02:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Successfully created standby master on mdwAfter initialization, query the database and you can see that the new standby node has been generated:
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
-----+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
6 | -1 | p | p | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
7 | -1 | m | m | s | u | 5432 | mdw | mdw | /home/mxadmin/standby
2 | 0 | p | p | s | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | m | m | s | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)For details of gpinitstandby, please refer to Document
For detailed usage methods of gpactivatestandby, please refer to Document