In any database, the data follows a certain model, such as relational model, KV model, etc. The hyper-converged timing database MatrixDB, based on the relational model, adds extensible data types, making it convenient for relationship operations, and is not limited by the fixed relationship model, which is both efficient and flexible.
Please refer to [MatrixDB Data Modeling and Spatial Distribution Model] for the teaching video of this course (https://www.bilibili.com/video/BV133411r7WH?share_source=copy_web)
To access timing data, you must first know that the timing data contains the following information:
Therefore, when doing data access, MatrixDB needs the following data table:
Among them, the device information table includes device ID and other attributes, such as name, location, etc.
The indicator table is used to store the device ID and all indicators.
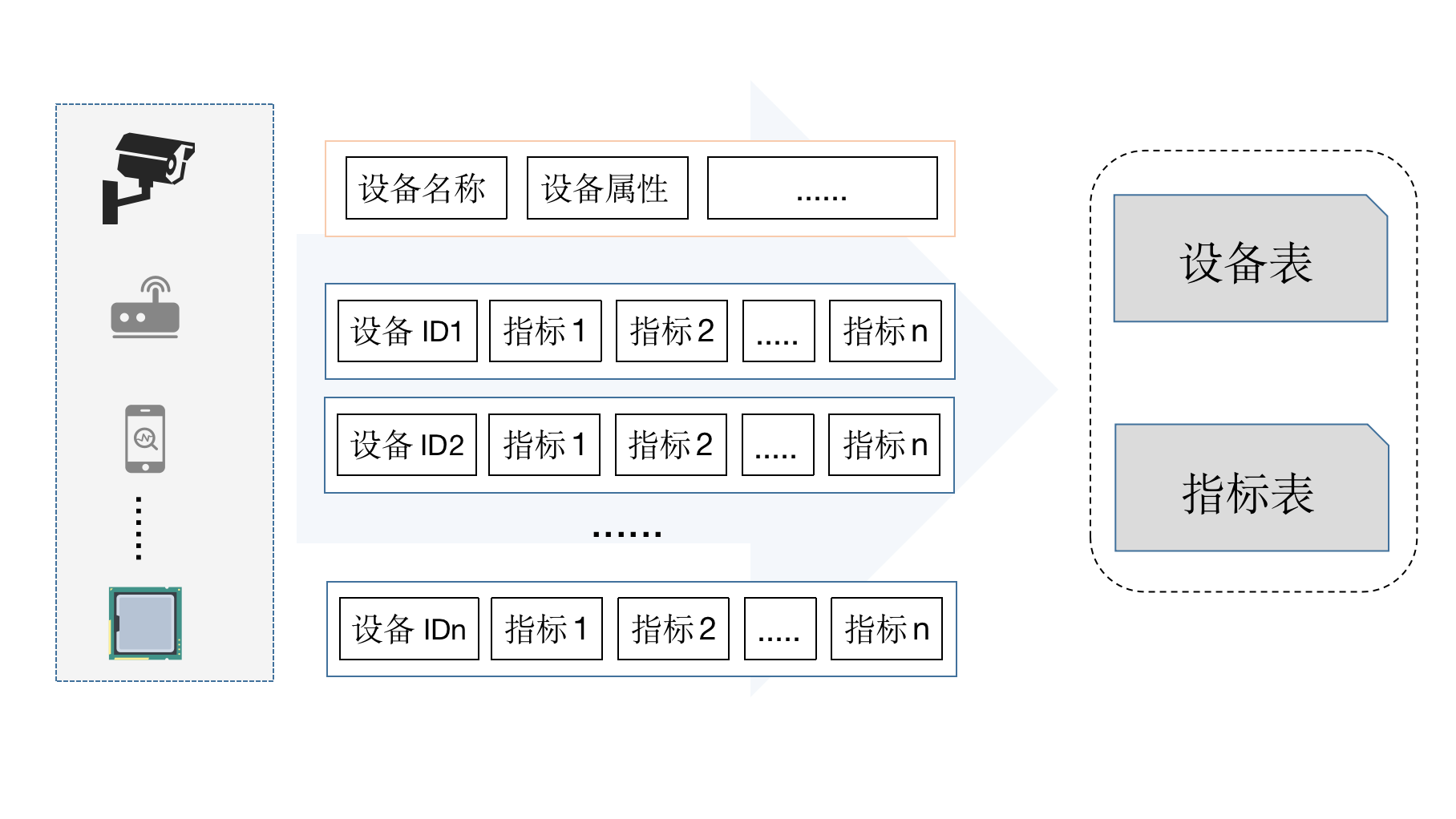
The main reason why two tables need to be separated rather than exist together is:
This design conforms to the relationship model design paradigm, but introduces a new question: how to generate device IDs. The following two methods are usually used:
The following is an example of how to access timing data. Suppose the speed, temperature and humidity of the fan are to be collected. Fan equipment includes attributes such as name, number, area, coordinates, etc.
According to the above method, you need to prepare the following two tables:
| Field | Type | Description |
|---|---|---|
| tag_id | int | tag_id is the only id of the fan, and use the auto-increment primary key (SERIAL type) |
| name | text | fan name |
| serial_number | text | fan serial number |
| region | text | Flower belongs to the area |
| longitude | float4 | fan longitude |
| latitude | float4 | fan latitude |
| Field | Type | Description |
|---|---|---|
| tag_id | int | fan id |
| time | timestamp | timestamp of time series data |
| speed | float4 | fan speed |
| temperature | float4 | fan temperature |
| humidity | float4 | fan humidity |
Like other databases, in MatrixDB, data tables are organized by libraries, so first create the database stats.
You can connect to the default database postgres and then create it using CREATE DATABASE:
[mxadmin@mdw ~]$ psql postgres
psql (12)
Type "help" for help.
postgres=# CREATE DATABASE stats;
CREATE DATABASEYou can also directly create using MatrixDB's command line tool createb:
[mxadmin@mdw ~]$ createdb statsAfter creating the database, you have to connect it to use it. In MatrixDB, each connection can only belong to one fixed library.
You can connect to the database parameters by executing the psql command:
[mxadmin@mdw ~]$ psql stats
psql (12)
Type "help" for help.
stats=#You can also switch to the connection to the new database from other database connections using the \c meta command:
postgres=# \c stats
You are now connected to database "stats" as user "mxadmin".After connecting to the database, start creating data tables:
CREATE TABLE tags(
tag_id serial,
name text,
serial_number text,
region text,
longitude float4,
latitude float4
)
Distributed replicated;CREATE TABLE metrics(
time timestamp with time zone,
tag_id int,
speed float4,
temperature float4,
humidity float4
)
Distributed by (tag_id);From the above table creation statement, you will find that the distribution methods of the two tables are different.
tags table is used as Distributed replicatedmetrics is used as Distributed by (tag_id)because:
For a more detailed introduction to data distribution, please refer to [Data Distribution Model] (/doc/latest/datamodel/data_distribute)
Because the device information in the tag table must be unique, it is necessary to establish a unique index for the information identifying the unique attributes of the device to facilitate the application to maintain the device information. Here it is assumed that the device number is used to mark the uniqueness of the device, so a unique index is established as follows:
CREATE UNIQUE INDEX ON tags(serial_number);When the application party is accessing the indicator data, it needs to follow the following steps:
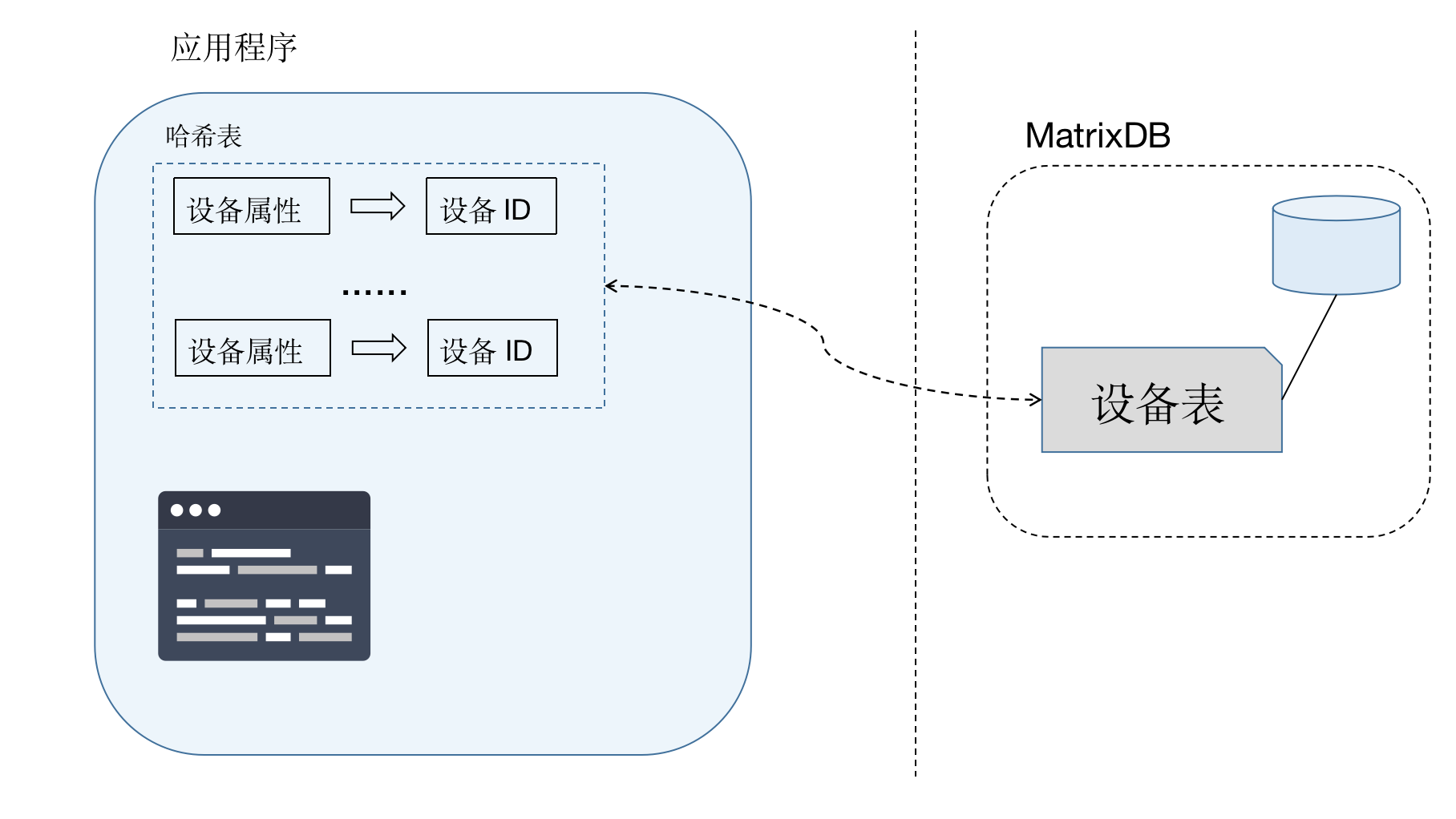
So how do you convert the device ID into an ID? The device ID is not an attribute of the device itself and will not be sent with the indicator data. It needs to be converted by the application party.
The easiest way is to check the library according to the device number every time, and read it directly if it exists; insert a new device and generate an ID if it does not exist.
This method requires that each metric be checked before inserting it, greatly increasing the database load and affecting throughput. Therefore, the recommended method is to maintain a memory hash table on the application side. When each piece of data arrives, query the device ID from the memory hash table. If it exists, it will be used directly; if it does not exist, it will be inserted into the library to obtain the device ID and update the hash table.
Since the device information and indicator data are stored separately in two tables. When doing query, if you want to obtain both indicator statistics and device information, you need to make connections based on the device ID.
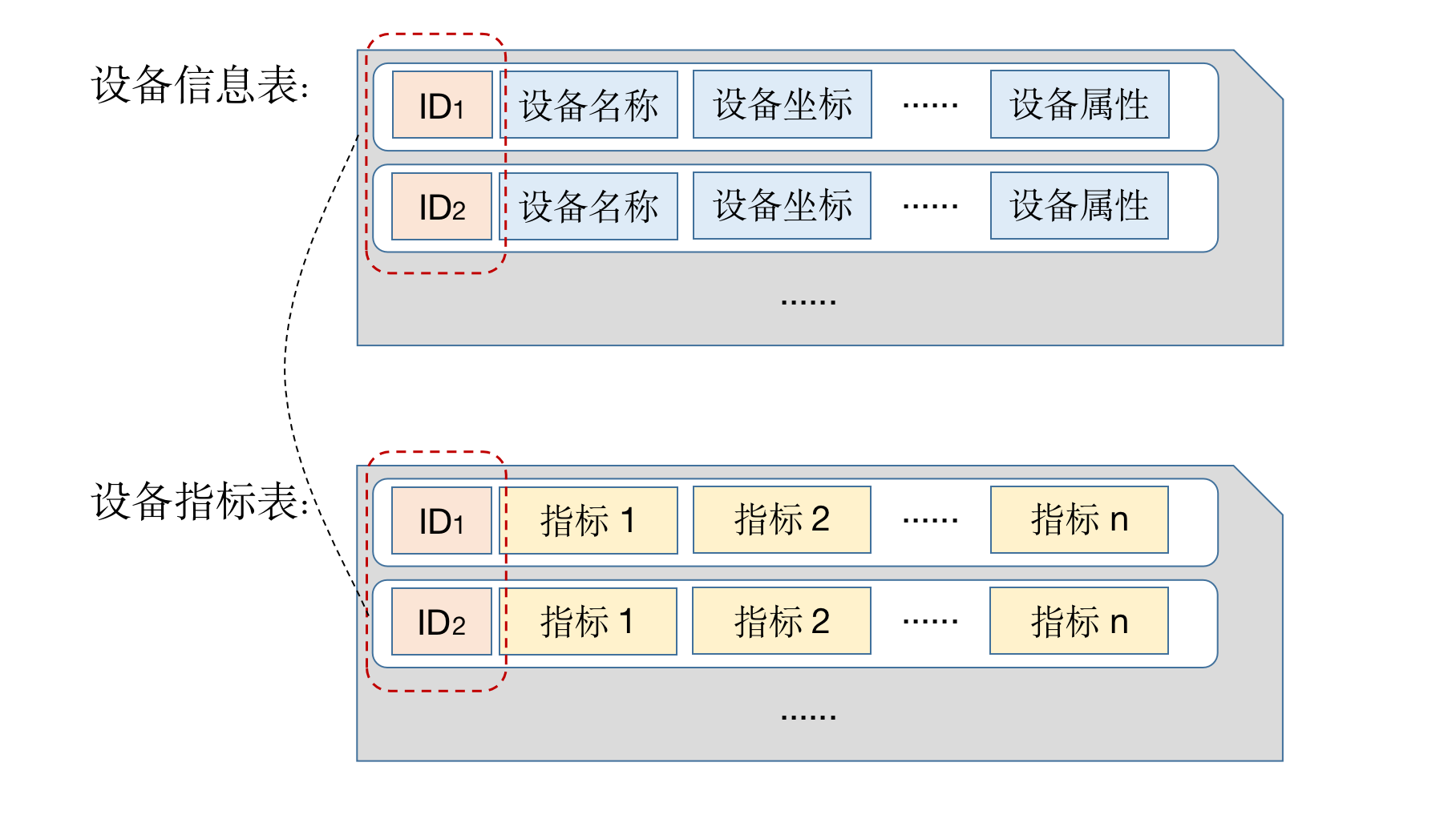
The following SQL statistics on the average temperature, average humidity and maximum speed of each fan on '2021-07-01':
SELECT tags.name,
AVG(metrics.temperature),
AVG(metrics.humidity),
MAX(metrics.speed)
FROM tags JOIN metrics USING (tag_id)
WHERE metrics.time >= '2021-07-01'
AND metrics.time < '2021-07-02'
GROUP BY tags.tag_id, tags.name;From the above introduction, we can see that MatrixDB is a relational database and uses the paradigm of relational databases when modeling data. Although the relationship model is easy to use, it also faces some challenges when doing timing acquisition. Consider the following scenarios:
In response to the above problem, the MatrixDB technical team developed mxkv custom data type and provided a kv key-value storage structure, which perfectly solved the problem in the above scenario.
As shown in the figure below, mxkv is a key-value type, and any number of key-values can be stored internally. There is no limit on the number of keys, and new keys can be added arbitrarily. For uncertain indicators, just store them in the mxkv field. The actual storage space overhead depends on the number and size of the key value.
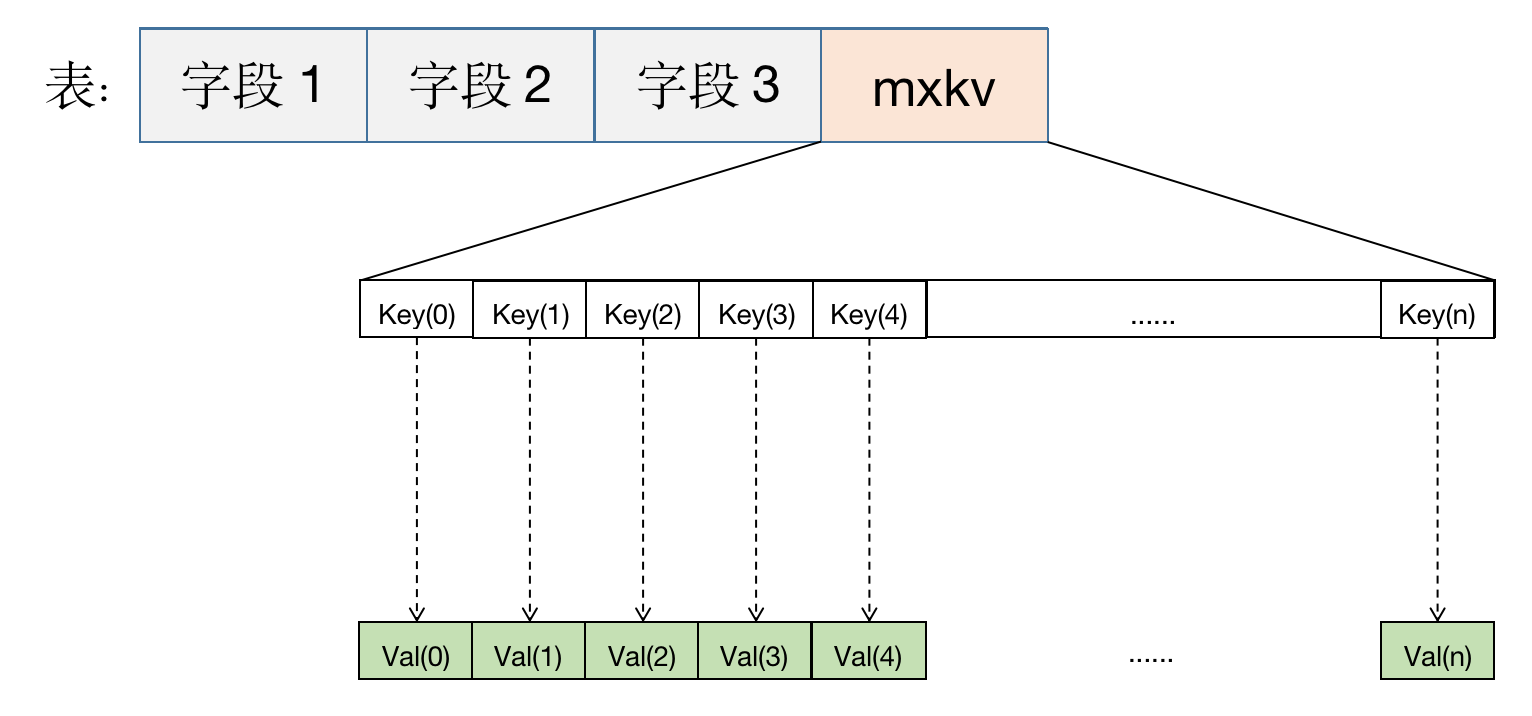
For use of mxkv, please refer to mxkv