The previous section describes how MatrixDB models timing data. MatrixDB is a distributed database that is different from a stand-alone database in data storage. This section will introduce the distributed architecture of MatrixDB and how data tables should be distributed based on existing distributed architectures.
Please refer to [MatrixDB Data Modeling and Spatial Distribution Model] for the teaching video of this course (https://www.bilibili.com/video/BV133411r7WH?share_source=copy_web)
MatrixDB is a centralized distributed database, including two types of nodes: master and segment.
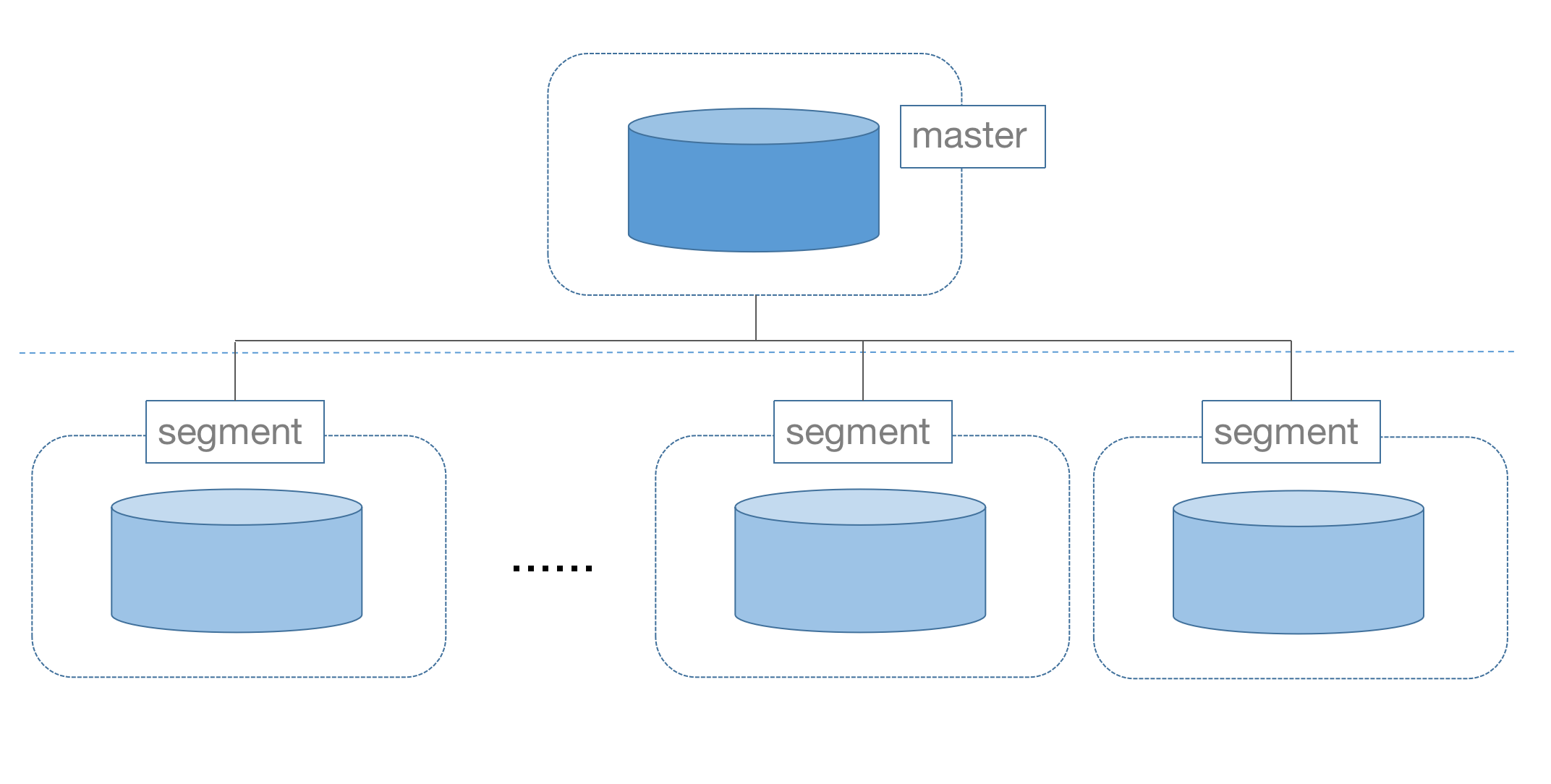 The master is a central control node that receives user requests and generates query plans. The master node does not store data, and the data is stored on the segment node.
The master is a central control node that receives user requests and generates query plans. The master node does not store data, and the data is stored on the segment node.
There is only one master node, and at least one segment node, which can be more, dozens or even hundreds. The more segment nodes, the more data the cluster can store and the stronger the computing power.
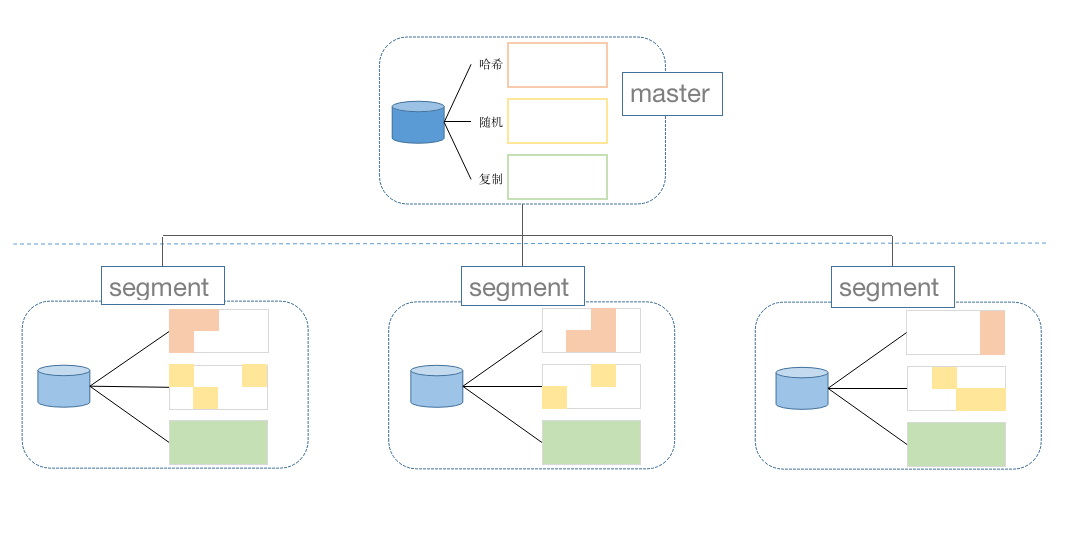
MatrixDB data table has two distribution strategies on segment, sharding and redundancy; sharding is divided into two types of hashing and random sharding:
The shard distribution is to split the data horizontally, and a piece of data is stored on only one of the nodes. Hash shards need to define hash keys, which can be one or more. The database calculates the key value for the hash key to determine which node to store on. Random sharding randomly allocates data to a node.
The redundant distribution stores data redundancy on each data node, that is, each data node contains all the data in the table. This method will occupy a lot of storage space, so only small tables that often require connection operations use redundant distribution.
In summary, there are 3 strategies for data distribution, and different distribution strategies. When creating tables, you can set them through the Distributed by keyword:
MatrixDB under a distributed architecture, most data tables are stored in shards, but can support all relationship queries. From the user's perspective, it is PostgreSQL with infinite space.
So, how to do data connections across nodes? This is thanks to MatrixDB's Motion operation, when the data that meets the connection conditions are not on the same node, they will be moved to the same node for connection.
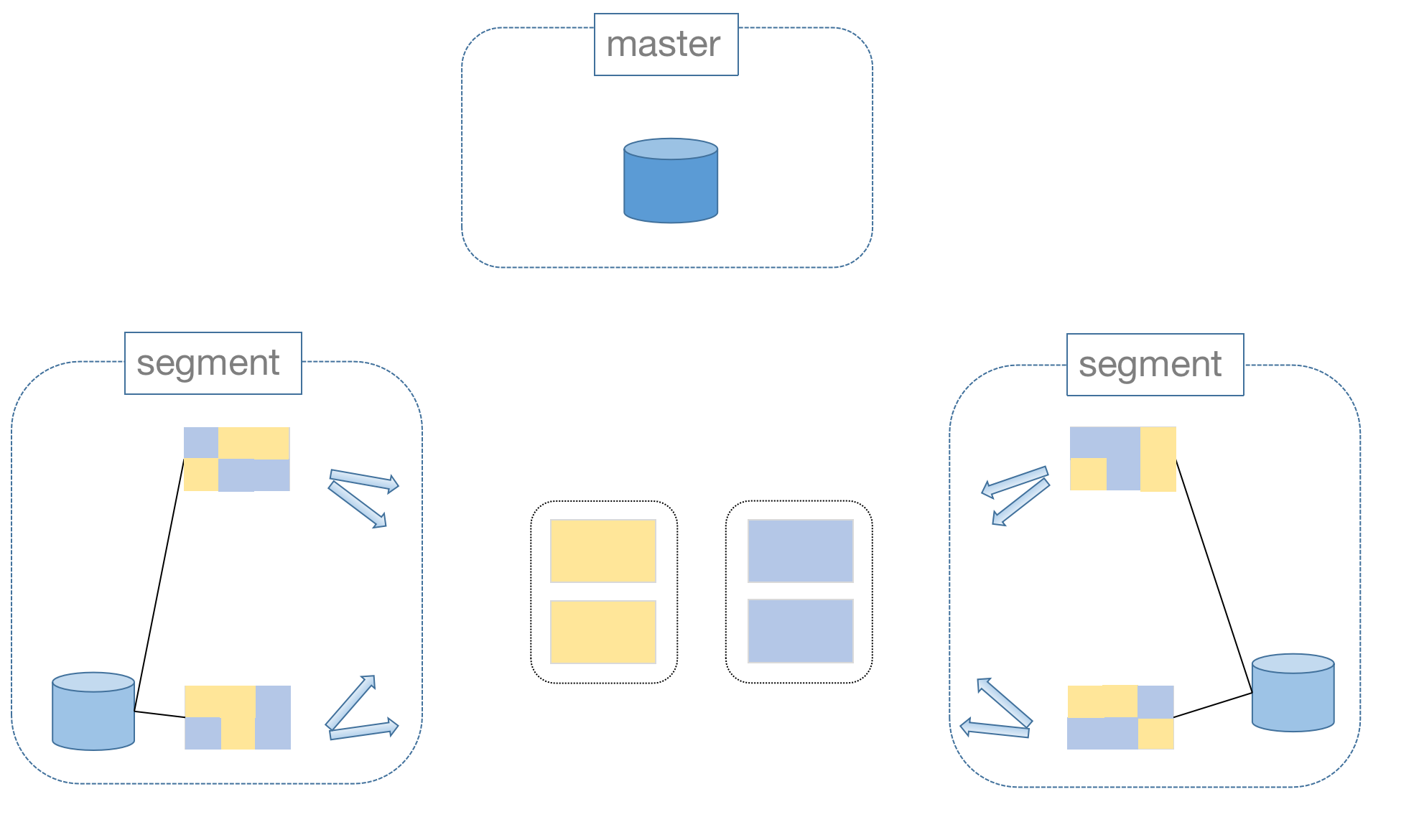
Of course, there is a cost to do mobile operations. Therefore, when designing a table, we must fully consider the data distribution characteristics and the query types to be conducted later to comprehensively determine the distribution strategy.
Movement operations can only be avoided if the data that meets the connection conditions are completely distributed on the same node. Therefore, it is often necessary to do large tables for joining operations, and it is best to set the joining key to the distribution key.
After understanding the distribution method and pros and cons of MatrixDB data, let’s discuss which distribution strategy should be adopted in the timing data table.
First, let’s consider the indicator table. The amount of indicator data is very large, and it is impossible to adopt a redundant distribution method. There is no pattern in the random distribution, which is not conducive to the subsequent statistical analysis, so hash distribution is the first choice. Then how to determine the distribution bond?
The timing table data contains 3 dimensions:
The subsequent statistical analysis basically uses other attributes of the device and connected to the device table as grouping keys, so the device ID is used as the distribution key.
The scale of the device table data is relatively fixed and will not grow infinitely like the index data, so the redundant distribution method is generally adopted. In this way, there is no need to move data across nodes when connecting to the indicator table.