С 21 по 23 апреля 2026 года в Сан-Хосе, Кремниевая долина, успешно прошла Postgres Conference 2026 — крупнейшая мировая конференция по экосистеме PostgreSQL. Основная тема мероприятия — «Energizing People with Data and Creativity», что собрала ведущих разработчиков и практиков со всего мира для обсуждения эволюции PostgreSQL как ядра данных в эпоху AGI. Компания YMatrix, специализирующаяся на инновациях на уровне ядра, была приглашена выступить с двумя ключевыми техническими докладами, демонстрируя свои последние достижения в рамках гиперконвергентной архитектуры.

Как ежегодный «ориентир» мировых технологий PostgreSQL, программа конференции ясно демонстрировала путь трансформации баз данных от «традиционно универсальных» к «всеобъемлюще специализированным». В течение трёхдневных выступлений обсуждения концентрировались на трёх ключевых направлениях:
Нативная интеграция баз данных с AI-агентами: в отличие от прошлых лет, когда обсуждалось преимущественно хранение данных, в этом году несколько глубоких сессий были посвящены использованию PostgreSQL в качестве базы «долговременной и краткосрочной памяти» для AI-агентов. Особенно внимание разработчиков привлекло сочетание обработки векторных данных (Vector Processing) и протоколов больших моделей (MCP).
Максимизация производительности и оптимизация ядра: на мероприятии обсуждались методы изменения ядра, использования SIMD-инструкций и других низкоуровневых подходов для преодоления традиционных ограничений PostgreSQL. Стремление к минимальной задержке (millisecond-level latency) и высокой пропускной способности отражает строгие требования эпохи AGI к инфраструктуре данных.
От «статического хранения» к «динамическим вычислениям»: ещё одной заметной тенденцией стало обсуждение потоковых вычислений внутри базы (In-Database Streaming). Разработчики стремятся, чтобы база данных не просто выступала как «склад», а эволюционировала в «фабрику» реального времени, выполняя анализ и реакцию сразу при поступлении данных.
На конференции YMatrix представила решения для устранения узких мест в аналитической производительности PostgreSQL и проблем традиционной потоковой архитектуры, предложив лёгкие и нативно интегрированные подходы для масштабного анализа данных и вычислений в реальном времени.
YMatrix Vector High-Performance Pluggable Vectorized Executor
Для стандартного исполнительного механизма PostgreSQL в OLAP-сценариях, где итерация «по одному кортежу за раз» приводит к избыточной нагрузке CPU, эксперт YMatrix CC Xiong подробно разобрал векторизованный движок mxvector.
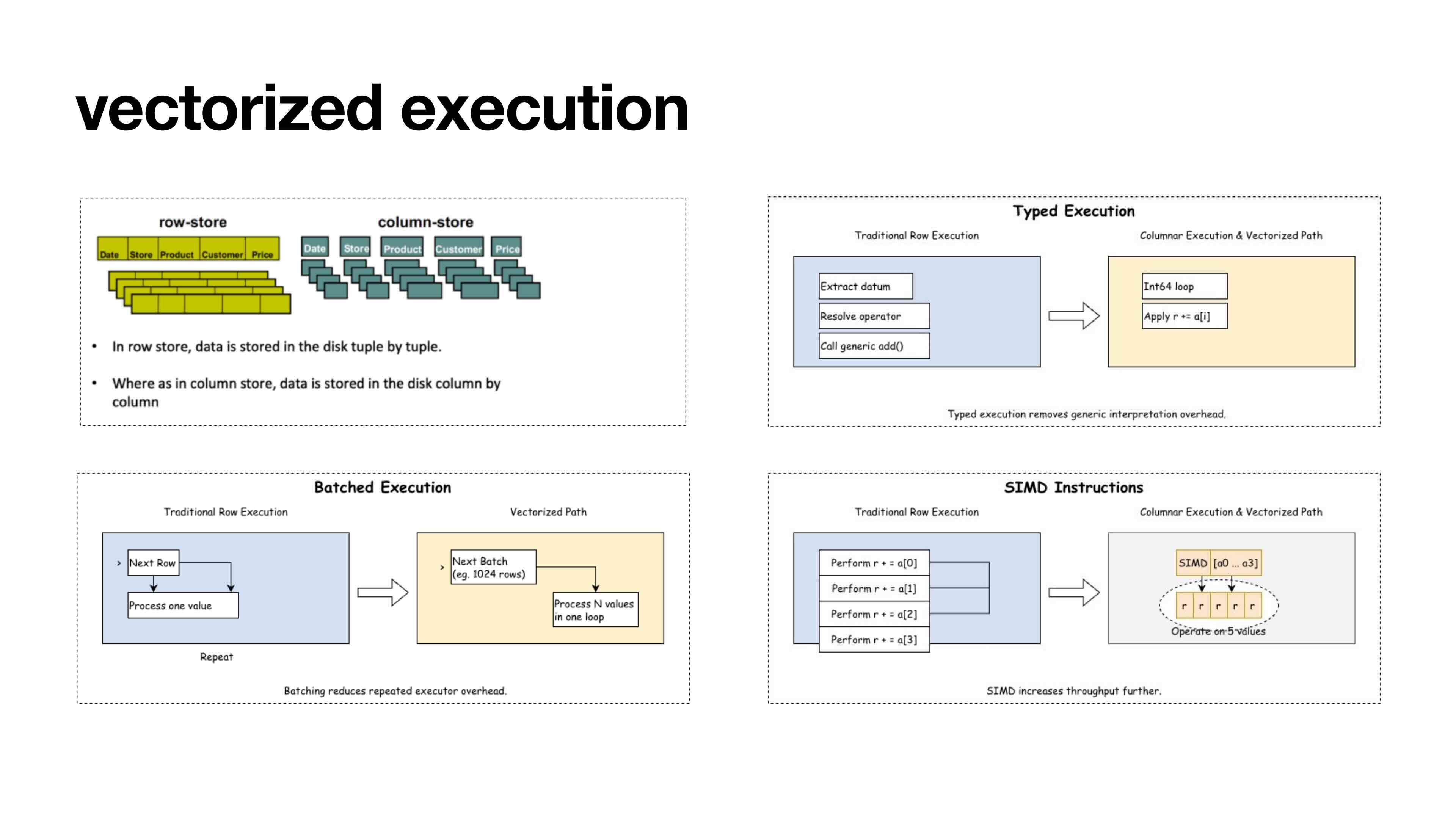
Основной принцип движка — экстремальная модульность: используя нативные расширения PostgreSQL, такие как Hook, Custom Scan и Table Access Method, mxvector обеспечивает плавное сосуществование со стандартным исполнительным путём без изменения кода ядра. Введение технологии VSlot с нулевым копированием превращает скалярные вычисления в пакетную векторизованную обработку и глубоко оптимизируется под SIMD-инструкции, значительно снижая накладные расходы на вызовы функций и ветвления. Это позволяет PostgreSQL сохранять высокую OLTP-производительность, одновременно обеспечивая промышленный уровень анализа в реальном времени.
PostgreSQL Streaming Model: From Implicit to Explicit How Domino Enables Continuous Computing
В презентации по потоковым вычислениям CC Xiong подробно раскрыл движок потоковых вычислений Domino.
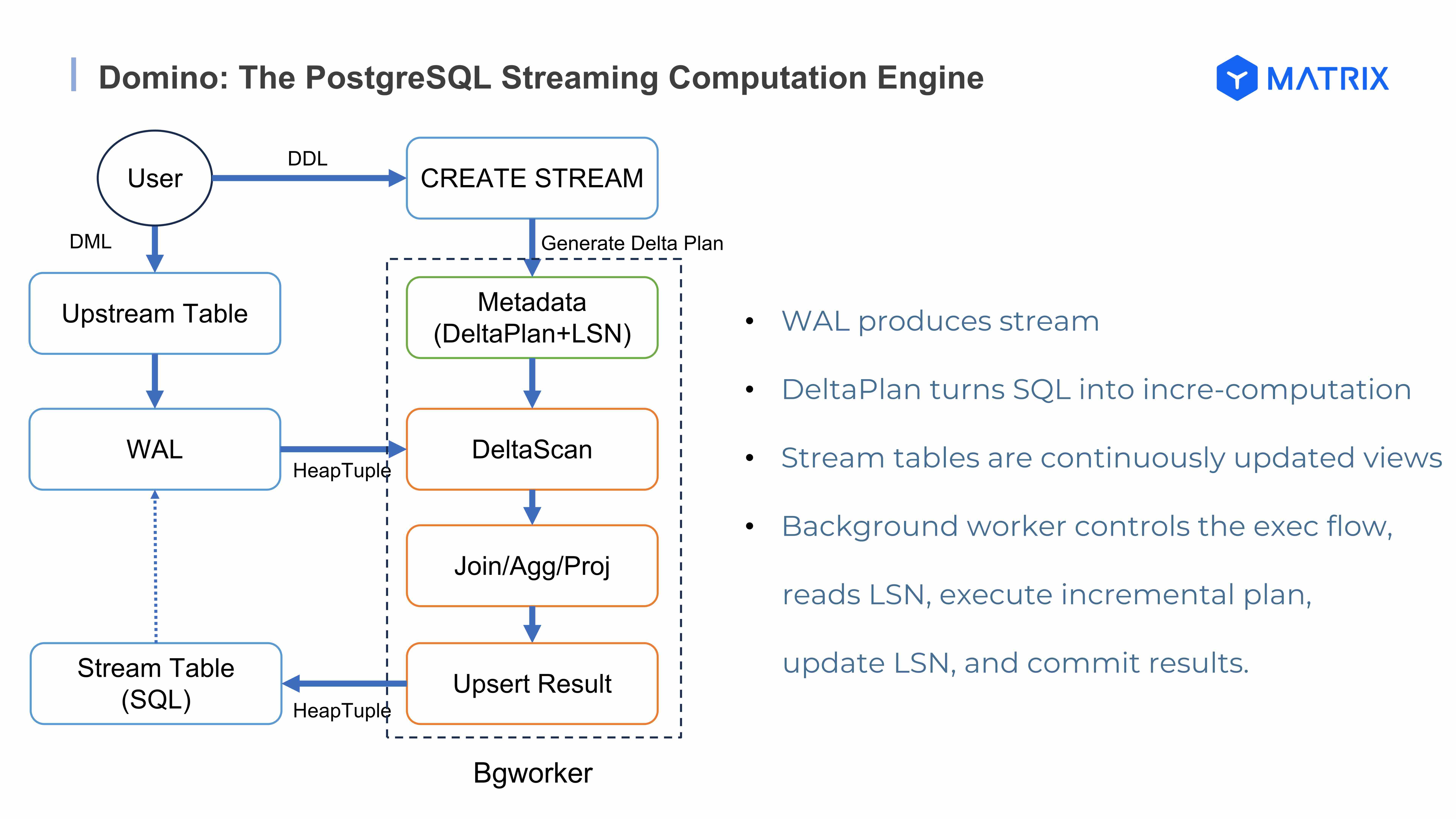
Традиционные цепочки потоковой обработки (например, Kafka + Flink + БД) отличаются громоздкостью, избыточной передачей данных и высокими затратами на поддержку. Инновационный движок Domino полностью использует возможности ядра PostgreSQL, обеспечивая переход от batch processing к модели «streaming reaction». Domino глубоко интегрирует логику потоковой обработки в ядро базы, нативно поддерживает расширения стандартного SQL и, при строгом соблюдении семантики Exactly-Once, достигает минимальной задержки на всем пути обработки. В тестах на сложных нагрузках с сотнями миллионов строк полная задержка по цепочке составила менее 20 секунд, что значительно превосходит традиционные решения.
Презентация в Кремниевой долине стала не только витриной гиперконвергентной концепции YMatrix, но и глубоким взаимодействием китайских инноваций в области баз данных с глобальной открытой экосистемой. С дальнейшей эволюцией гиперконвергентной архитектуры PostgreSQL превращается из традиционной реляционной базы в универсальную AI-платформу данных.
В будущем YMatrix продолжит инновации, продвигая технологии баз данных к более простым, эффективным и интеллектуальным решениям. В дальнейшем будут опубликованы более подробные технические разборы движков mxvector и Domino, следите за официальными обновлениями YMatrix.