In recent years, rapid advances in AI have led to a clear shift: database workloads are becoming increasingly heavy. More and more scenarios are no longer limited to a few fixed reports, but instead involve wider fact tables, longer time windows, and higher-dimensional feature data. Examples include feature engineering, user behavior analysis, secondary analysis of model outputs, and even joining vector retrieval results with business attributes, time windows, and transactional details. When performing SQL performance analysis, we usually start by checking familiar areas:
These are all important. However, in MPP architectures, the actual factor that slows queries down is often something less noticeable: data transfer.
In YMatrix, a single SQL statement is executed in parallel across multiple machines and finally aggregated at a coordinator node. During this process, scan, filter, aggregation, sorting, and join operators are responsible for “computing”, while Interconnect is responsible for “delivering data” to the target nodes.
If the database execution engine is the “engine”, Interconnect is the “data highway”. If the highway is too narrow, toll gates too frequent, or congestion too severe, even a powerful engine cannot deliver high query performance.
To address this, YMatrix introduced a full upgrade of this data highway, implementing a new generation ic-tunnel transport protocol. In this mode, data can be delivered more stably and reliably, ensuring better query performance.
In a real-world financial shared-service scenario of a large enterprise group, users frequently perform detailed analysis across ledgers, fiscal years, and accounting subjects. Sometimes they query a single ledger; sometimes all ledgers; sometimes a single account; and sometimes full-year, full-subject detailed data.
Under tunnel mode, compared with TCP mode, performance improvements are observed:
These results show that ic-tunnel significantly reduces waiting time caused by data transmission paths. The heavier the data exchange workload, the more visible the improvement becomes.
In a single-node database, SQL performance is mainly constrained by CPU capacity, memory availability, and disk I/O throughput.
In MPP databases, the situation becomes more complex. Data is not only processed locally, but also redistributed, aggregated, and exchanged across multiple compute nodes. For example, in multi-table joins, data may need to be redistributed by join keys; in GROUP BY operations, intermediate results may need to be aggregated across nodes.
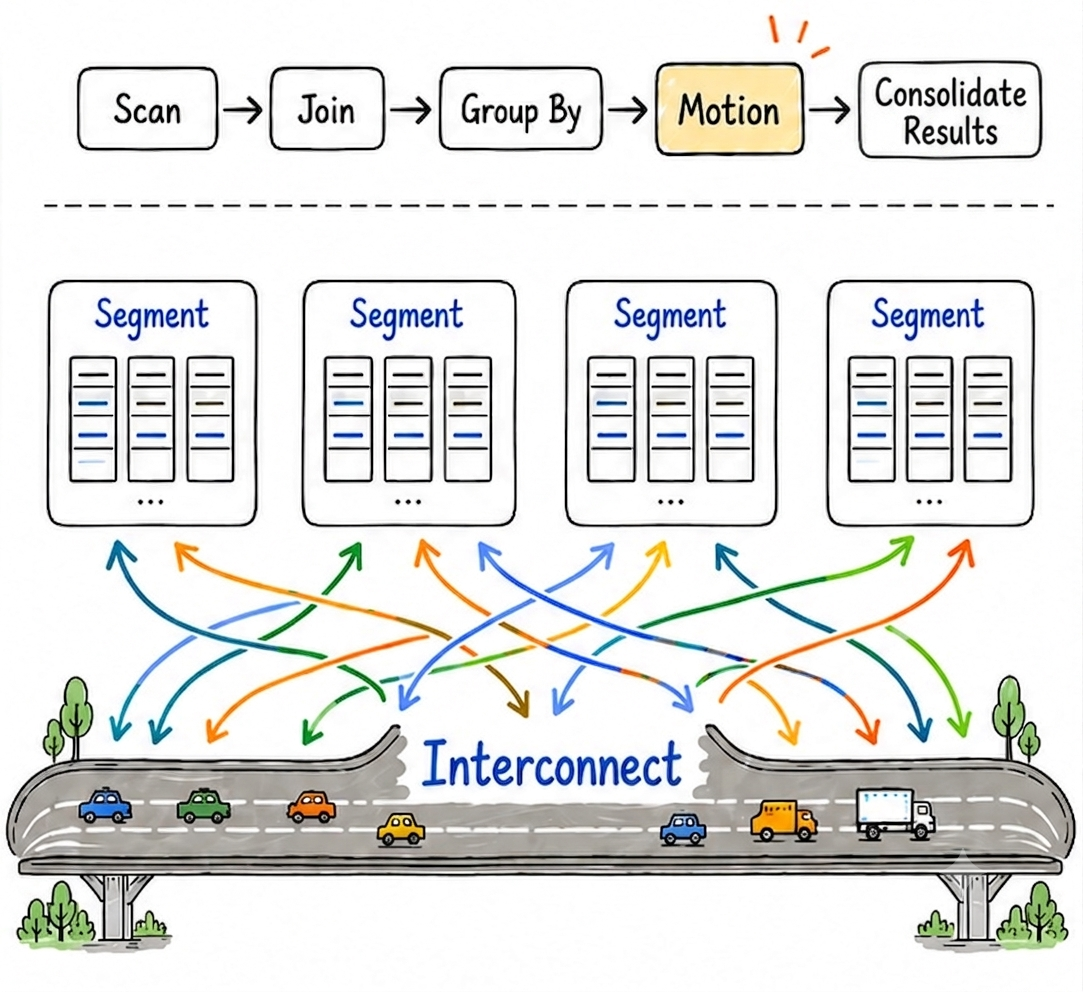
These data movements appear in execution plans as Motion operators.
Although Motion looks like just another node in the plan, it actually involves how nodes establish connections, how packets are split and transmitted, how retransmission behaves under network jitter, and whether communication paths remain valid under topology changes.
All of these responsibilities eventually fall under Interconnect.
Therefore, in MPP databases, network communication is not an auxiliary step outside query execution—it is part of execution itself, and it directly determines whether a query can complete efficiently and stably.
Traditional MPP systems typically implement Interconnect in two ways: TCP and UDP.
TCP is mature and stable, and it offers a high performance ceiling. However, its scalability is limited. As cluster size grows, connection overhead becomes difficult to control. For example, in a 100-node cluster, a single data redistribution may require 100² = 10,000 TCP connections. If ten queries run concurrently, this becomes (100 × 10)² = 1,000,000 TCP connections. This is similar to building a dedicated ramp for every vehicle. Once traffic increases, congestion becomes inevitable, significantly limiting cluster throughput.
UDP, on the other hand, can effectively reduce connection overhead and is better suited for large-scale clusters. However, it does not provide full reliability guarantees. Databases must implement ACK, retransmission, ordering, and flow control themselves. Under conditions such as high latency, small MTU, bandwidth constraints, or heavy detail data transfers, performance can fluctuate significantly.
In summary, traditional Interconnect approaches each have trade-offs: TCP is stable but does not scale well, while UDP scales well but is sensitive to network conditions.
YMatrix is not a traditional MPP database; it continues to evolve toward vectorized execution.
The core idea of vectorized execution is to process data in batches rather than row by row, making better use of CPU cache, SIMD instructions, and batch processing capabilities. This significantly improves the efficiency of scan, filter, aggregation, and join operators.
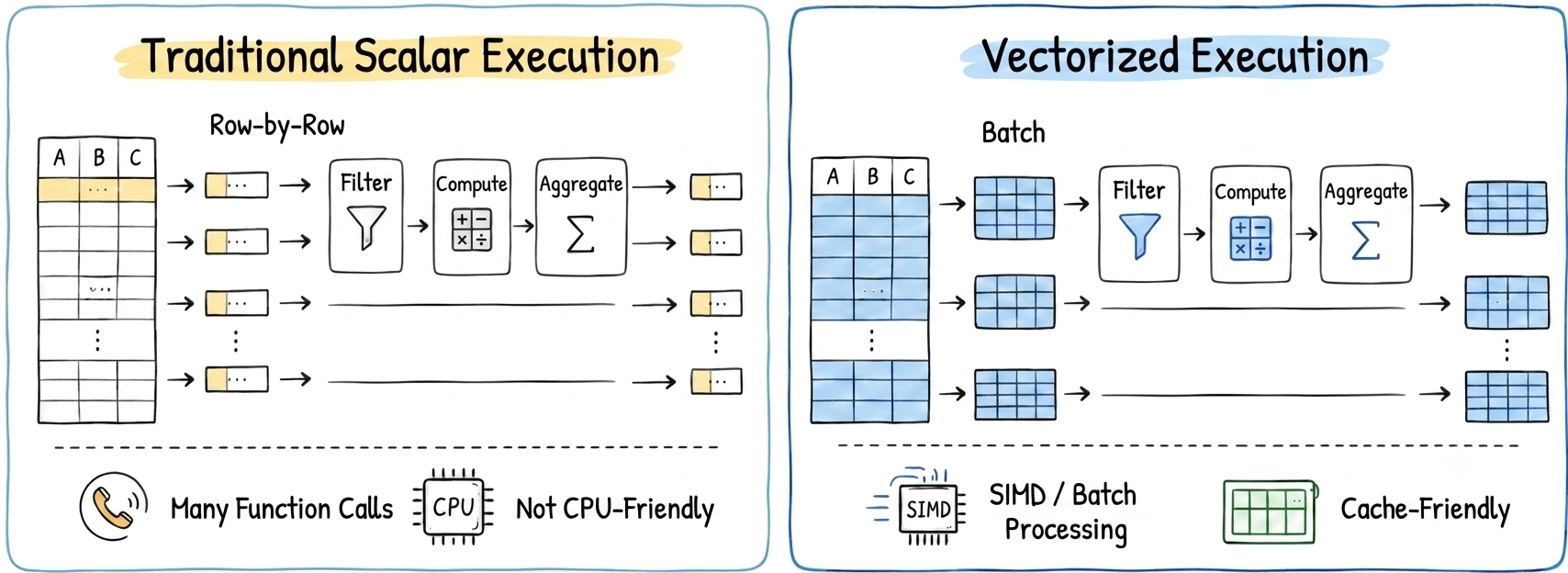
However, there is an often overlooked issue: while operators have become batch-oriented, data transfer must also evolve accordingly. Otherwise, even if the execution engine has entered the “batch processing era”, Interconnect may still remain in a mode of small-packet fragmentation, reassembly, and repeated copying, which significantly reduces the benefits of vectorization.
This is one of the core motivations behind ic-tunnel: as the execution engine of YMatrix becomes faster, should the underlying data exchange mechanism also evolve? The answer is clearly yes.
Vectorized execution requires not only faster operators, but also a communication foundation that is better suited for large-scale data movement. Only when computation and communication evolve together can the full performance of distributed queries be realized.
In simple terms, ic-tunnel is the next-generation Interconnect implementation of YMatrix.
As mentioned above, in traditional modes, nodes may need to establish a large number of direct connections. As cluster size, concurrency, and query complexity increase, connection management becomes increasingly difficult.
ic-tunnel adopts a proxy-based architecture. Each segment runs a dedicated tunnel server process. Query processes no longer establish connections with all remote nodes directly. Instead, they first connect to a local tunnel server, and then the tunnel server handles forwarding to remote tunnel servers.
The difference can be summarized as:
From the perspective of upper-layer execution logic, Motion still defines the direction of data flow. However, connection management, topology awareness, flow control, transmission granularity, and compression are all handled by the tunnel layer.
In other words, the tunnel layer consolidates previously scattered connections and forwarding paths, allowing the execution layer to continue working with Motion semantics while the lower layer manages communication complexity.
The advantages of ic-tunnel can be summarized into three aspects: topology awareness on demand, active flow control, and adaptive transmission granularity.
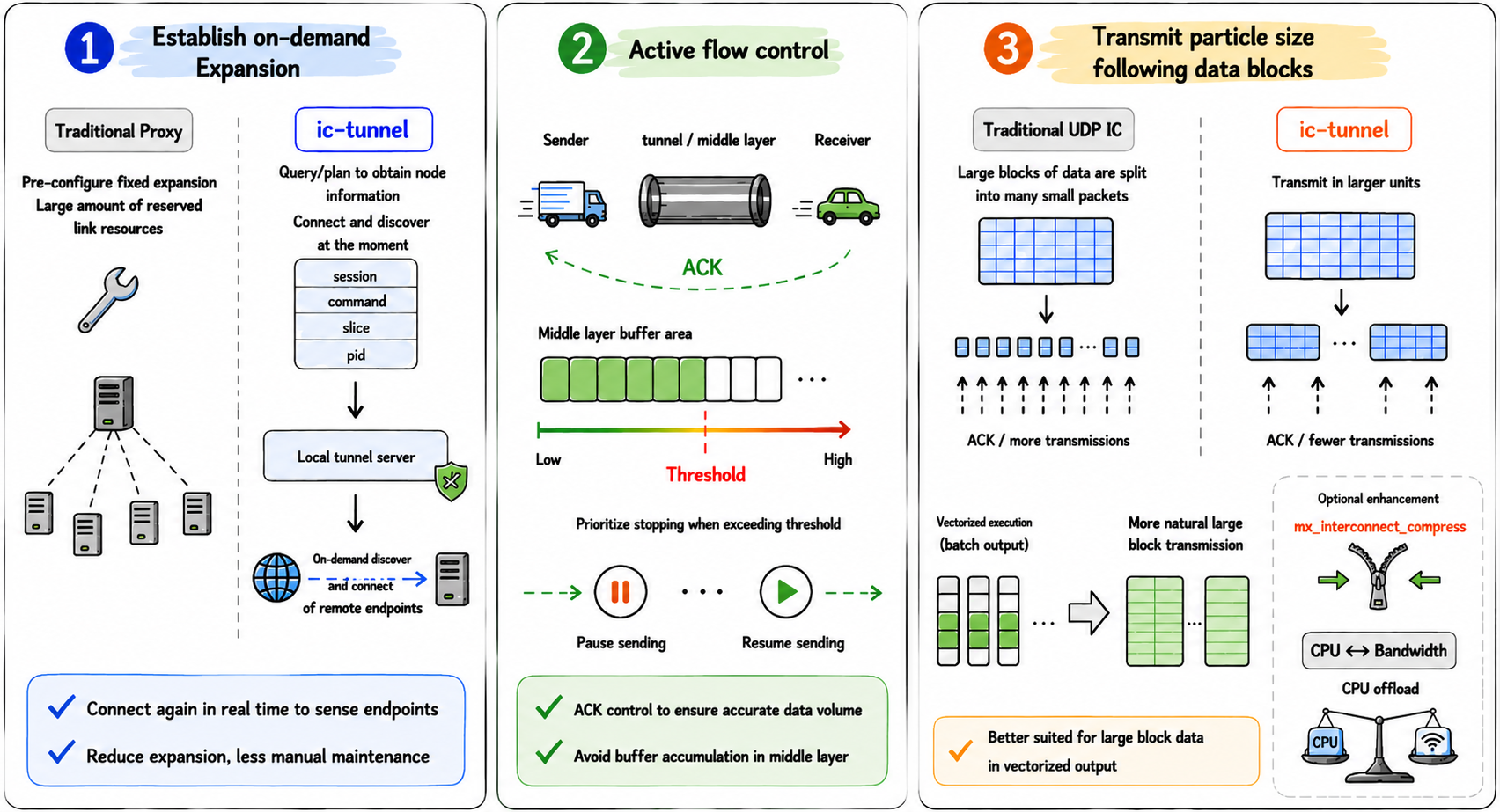
In MPP systems, cluster scaling, failover, or role changes can lead to topology changes. The design philosophy of ic-tunnel is that connections are driven by actual query execution.
When the master node distributes an execution plan, it also includes slices, node mappings, and connection information. Compute nodes then pass this information to their local tunnel server, which establishes connections accordingly.
In this way:
In short, ic-tunnel does not pre-build all network paths; instead, it discovers them dynamically based on actual query execution requirements.
A common risk in proxy-based architectures is that the sender is faster than the receiver. If the intermediate layer continuously receives and forwards data without proper flow control, data may accumulate in the middle layer. Small accumulation may only increase memory usage, but excessive buildup can affect system stability.
ic-tunnel implements active flow control, which can be divided into sender-side and receiver-side control.
Sender-side control occurs in the sending tunnel server: if it cannot forward data to the receiver in time, it will throttle upstream transmission. Receiver-side control occurs in the receiving tunnel server: if it cannot deliver data to the client in time, it will notify the sender to pause transmission.
For a proxy-based model, this is critical because once the tunnel server becomes a middle layer, it must not only forward data, but also control how much data stays in the pipeline.
Traditional UDP-based interconnect systems are heavily constrained by packet size and MTU. Large data blocks must be split into many small packets. In detail-heavy queries or large data transfer scenarios, ACK and retransmission overhead becomes increasingly significant.
ic-tunnel allows flexible control of transmission granularity and is no longer constrained by legacy parameters such as gp_max_packet_size. This is important for vectorized execution, which is inherently batch-oriented.
When interconnect can naturally handle large data blocks, it reduces fragmentation, reassembly, and extra copying overhead in intermediate layers. In addition, when bandwidth becomes a bottleneck, mx_interconnect_compress can be enabled to compress network traffic, which is particularly useful in bandwidth-constrained environments.
ic-tunnel upgrades the Interconnect layer of YMatrix from a traditional TCP/UDP connection model to a more modern communication architecture:
As data volume continues to grow and clusters become increasingly complex, the real limit of database capability is no longer a single operator, but whether the system can continuously, stably, and efficiently move data under real-world conditions.
ic-tunnel is precisely the next-generation high-speed communication corridor built by YMatrix for this era of data movement.
AI Era Database Infrastructure: Exploring Vectorized Execution in PostgreSQL
How MARS3 Works: Hybrid Row/Column Storage for High-Frequency Writes and Fast Analytics
Dahshenlin: Achieving Real-Time Finance-Operations Integration with a Modernized Data Foundation
The PostgreSQL Streaming Model
From Greenplum to YMatrix: Migrating Core Business Data for a Leading Power-Battery Manufacturer
Smart Manufacturing at Scale with YMatrix HTAP: Real-Time Ingestion & Unified Analytics