Этот документ описывает движки хранения, поддерживаемые MatrixDB, и инструмент диагностики хранилища datainspect. В нём рассматриваются следующие темы:
Движок хранения является основой уровня хранения данных в системе баз данных. База данных выполняет операции создания, запроса, обновления и удаления на основе нижележащего движка хранения. Разные движки хранения обеспечивают различные механизмы хранения данных, разработанные по различным измерениям, включая физическую организацию, типы индексов и детализацию блокировок.
В настоящее время MatrixDB поддерживает следующие движки хранения:
Таблица HEAP использует традиционный кучный движок хранения PostgreSQL, также известный как heap-таблица. Он поддерживает высокую параллельность операций чтения/записи, транзакции, индексы и другие функции.
Таблица MARS2 повышает производительность запросов за счёт уменьшения операций позиционирования I/O благодаря физическому объединению данных в упорядоченном виде. Поддерживает сжатие, колоночное хранение, автоматическое архивирование, предварительную агрегацию и отлично подходит для временных рядов.
Примечание: В настоящее время MARS2 не поддерживает операции UPDATE или DELETE.
Исходя из характеристик каждого движка хранения, вы можете гибко выбирать подходящий движок в зависимости от конкретного случая использования. Ниже приведены примеры создания таблиц с использованием различных движков.
HEAP — это движок хранения по умолчанию в MatrixDB. Если при создании таблицы движок хранения явно не указан, по умолчанию будет создана таблица типа HEAP.
=# CREATE TABLE disk(
time timestamp with time zone,
tag_id int,
read float,
write float
)
DISTRIBUTED BY (tag_id);Таблица MARS2 зависит от расширения временных рядов matrixts. Перед созданием таблицы MARS2 необходимо установить это расширение в целевой базе данных.
Примечание!
Расширениеmatrixtsимеет уровень базы данных. Его нужно создавать один раз на базу данных; повторное создание не требуется.
=# CREATE EXTENSION matrixts;При создании таблицы используйте предложение USING MARS2, чтобы указать движок хранения MARS2:
=# CREATE TABLE vehicle_basic_data_mars2(
daq_time timestamp encoding (minmax),
vin varchar(32) COLLATE "C" encoding (minmax),
lng float encoding (minmax),
lat float encoding (minmax),
speed float ,
license_template varchar(16) ,
flag integer
)
USING MARS2
WITH (compresstype=zstd, compresslevel=3)
DISTRIBUTED BY (vin)
PARTITION BY RANGE (daq_time)
( START ('2022-07-01 00:00:00') INCLUSIVE
END ('2022-08-01 00:00:00') EXCLUSIVE
EVERY (INTERVAL '1 day')
,DEFAULT PARTITION others );Ниже приведено описание ключевых параметров и предложений, используемых в операторе vehicle_basic_data_mars2:
encoding (minmax)
Эта опция повышает производительность запросов для агрегатных функций, таких как min, max, avg, sum, count, или фильтрации с помощью WHERE. Используйте эту опцию выборочно в соответствии с бизнес-потребностями. Не применяйте её ко всем столбцам без разбора, так как это может увеличить ненужные затраты CPU и I/O при записи данных.
COLLATE "C"
Применяется только к полям идентификатора устройства. Улучшает производительность сортировки и запросов для текстовых столбцов.
USING MARS2
Это обязательный синтаксис для указания движка хранения MARS2. Не изменяйте это предложение.
WITH (compresstype=zstd, compresslevel=3)
Указывает Zstandard (zstd) в качестве алгоритма сжатия. Другие поддерживаемые алгоритмы: rle_type, zlib и lz4. Рекомендуется использовать zstd с уровнем сжатия 3. Подробные параметры сжатия приведены в таблице ниже.
DISTRIBUTED BY (vin)
Определяет ключ распределения. Рекомендуется использовать 设备编码字段 в качестве ключа распределения для эффективных запросов к данным одного устройства, минимизируя стоимость перераспределения данных между узлами.
PARTITION BY RANGE (daq_time)
Определяет ключ секционирования. Рекомендуется использовать 设备采集数据的时间 в качестве ключа секционирования, поскольку большинство запросов фильтруют данные по времени сбора. Например, если вы хотите проанализировать данные за один день, добавление фильтра вида WHERE daq_time >= CURRENT_DATE - INTERVAL '1 day' позволяет базе данных быстро найти соответствующую секцию и эффективно извлечь данные.
( START ('2022-07-01 00:00:00') INCLUSIVE END ('2022-08-01 00:00:00') EXCLUSIVE EVERY (INTERVAL '1 day'), DEFAULT PARTITION others);
Это предложение создаёт подсекции, начиная с 2022-07-01 00:00:00 до 2022-08-01 00:00:00, с использованием ключевого слова START...END вместе с INCLUSIVE и EXCLUSIVE.
EVERY (INTERVAL '1 day')
Задаёт интервал времени между секциями равным 1 дней. Помимо day, можно также использовать hour, month или year, в зависимости от объема данных. Например:
1 day в качестве интервала.1 month.1 year.DEFAULT PARTITION others
Определяет секцию по умолчанию. Данные с меткой времени, не попадающей в заданный диапазон, будут сохраняться здесь.
Примечание!
Хотя мы рекомендуем следовать этим советам, не следует слепо их копировать. Сценарии использования временных рядов сильно различаются — всегда анализируйте свою конкретную ситуацию перед окончательным принятием решений.
Параметры сжатия для таблиц MARS2:
| Параметр | По умолчанию | Мин. | Макс. | Описание |
|---|---|---|---|---|
| compress_threshold | 1200 | 1 | 8000 | Порог сжатия. Контролирует количество кортежей, вызывающих операцию сжатия. Представляет максимальное число кортежей в одной единице сжатия. |
| compresstype | lz4 | — | — | Алгоритм сжатия. Поддерживаемые значения: 1. zstd 2. zlib 3. lz4 |
| compresslevel | 1 | 1 | — | Уровень сжатия. Более высокие значения дают лучшее сжатие, но медленнее. Диапазоны значений зависят от алгоритма: zstd: 1–19 zlib: 1–9 lz4: 1–20 |
Примечание!
Как правило, более высокие уровни сжатия обеспечивают лучшее сжатие, но снижают производительность. Однако это не всегда строго соблюдается.
После успешного создания таблицы MARS2 необходимо создать индекс mars2_btree, чтобы обеспечить нормальное чтение и запись данных. Цель индексирования — физически группировать данные с близкими измерениями или атрибутами, что уменьшает операции позиционирования I/O и повышает эффективность запросов. Поэтому выбирайте ключи сортировки, соответствующие основным шаблонам ваших запросов.
Например:
(vin)) в качестве ключа сортировки.(vin,daq_time)).=# CREATE INDEX idx_mars2 ON vehicle_basic_data_mars2
USING mars2_btree(vin, daq_time);Примечание!
Когда одновременно поступают несколько пакетов данных для одного и того же устройства в один момент времени, MARS2 может их объединить. Чтобы включить объединение, при создании индекса необходимо вручную указатьuniquemode=true, так как его значение по умолчанию —false. Например:
- При
uniquemode=true, если устройствоA01отправляет3записей в момент времени2022-01-01 00:00:00, сохраняется только последняя запись (предыдущие перезаписываются).- При значении по умолчанию
uniquemode=false, все3записей от устройстваA01в момент времени2022-01-01 00:00:00сохраняются без дедупликации.
datainspect — это встроенный инструмент диагностики хранилища для MARS2. Он предоставляет детальную информацию о физическом хранении, позволяя точно оптимизировать хранение данных и производительность запросов.
Оптимизация хранилища требует понимания того, как данные организованы в физических файлах. Аналогично pageinspect в PostgreSQL, datainspect позволяет легко извлекать и анализировать сегменты данных внутри хранилища MARS2. Кроме того, он интегрирует информацию об индексах и метаданных, таких как распределение NULL и значения min/max, помогая оптимизировать сканирование I/O.
Примечание!
Этот инструмент применим только к таблицам MARS2.
datainspect состоит из внутренних системных функций, входящих в состав MARS2. Как только MARS2 установлен правильно, эти функции становятся доступны. Поскольку MARS2 зависит от расширения временных рядов matrixts, необходимо сначала создать это расширение в целевой базе данных.
Примечание!
Расширениеmatrixtsимеет уровень базы данных. Создайте его один раз на базу данных; повторять не нужно.
=# CREATE EXTENSION matrixts;Сначала создадим тестовую таблицу с именем tb1, чтобы продемонстрировать три основные функции.
=# CREATE TABLE tb1(
f1 int8 encoding(minmax),
f2 int8 encoding(minmax),
f3 float8 encoding(minmax),
f4 text
) USING MARS2;Создадим индекс MARS2:
=# CREATE INDEX ON tb1 USING mars2_btree(f1);Добавим 24 000 тестовых записей:
=# INSERT INTO tb1 SELECT
generate_series(1, 24000),
mod((random()*1000000*(generate_series(1, 1200)))::int8, (random()::int8/100 + 100)),
(random() * generate_series(1, 24000))::float8,
(random() * generate_series(1, 24000))::text;Функция desc_ranges раскрывает внутренние метаданные и структуры индексов MARS2, предоставляя информацию, такую как значения min/max и распределение NULL. Она также позволяет точно контролировать использование физического хранилища.
Синтаксис
SELECT <* / column1,column2,...> FROM matrixts_internal.desc_ranges(<tablename TEXT>)Параметры
tablename: Имя таблицы. Для секционированных таблиц используйте имя родительской таблицы. (Обязательно)Возвращаемые значения
| Поле | Описание |
|---|---|
| segno | Идентификатор сегмента, начинается с 0 |
| attno | Номер атрибута (идентификатор столбца), начинается с 0 |
| forkno | Идентификатор физической ветви файла. Соответствует конкретному файлу на уровне хранилища, начинается с первой ветви |
| offno | Смещение в байтах диапазона RANGE в физическом файле. Начинается с 0. В MARS2 данные записываются пакетами. Каждый пакет формирует RANGE после достижения настроенного compress_threshold (порога сжатия) |
| nbytes | Фактический размер в байтах, занимаемый RANGE |
| nrows | Количество строк в одном RANGE, определяемое настройкой compress_threshold (по умолчанию 1200). Также называется порогом сжатия — максимальное количество кортежей, сжимаемых вместе |
| nrowsnotnull | Количество ненулевых значений в RANGE |
| mmin | Минимальное значение в RANGE для столбцов с кодированием minmax; NULL в противном случае |
| mmax | Максимальное значение в RANGE для столбцов с кодированием minmax; NULL в противном случае |
=# SELECT attno, sum(nbytes)/1024 as "Size in KB"
FROM matrixts_internal.desc_ranges('tb1') GROUP BY attno ORDER BY attno;
attno | Size in KB
-------+----------------------
0 | 94.9062500000000000
1 | 7.8203125000000000
2 | 187.3437500000000000
3 | 386.3515625000000000
(4 rows)=# SELECT * FROM matrixts_internal.desc_ranges('tb1') WHERE segno = 1;
segno | attno | forkname | forkno | offno | nbytes | nrows | nrowsnotnull | mmin | mmax
-------+-------+----------+--------+--------+--------+-------+--------------+--------------------+--------------------
1 | 0 | data1 | 304 | 0 | 4848 | 1200 | 1200 | 15 | 7240
1 | 1 | data1 | 304 | 16376 | 856 | 1200 | 199 | 0 | 99
1 | 2 | data1 | 304 | 17712 | 9072 | 1200 | 1200 | 1.4602231817218758 | 704.8010557110921
1 | 3 | data1 | 304 | 50024 | 20272 | 1200 | 1200 | NULL | NULL
1 | 0 | data1 | 304 | 4848 | 4856 | 1200 | 1200 | 7243 | 14103
1 | 1 | data1 | 304 | 17232 | 160 | 1200 | 0 | NULL | NULL
1 | 2 | data1 | 304 | 26784 | 9760 | 1200 | 1200 | 705.0931003474365 | 1372.9018354549075
1 | 3 | data1 | 304 | 70296 | 19680 | 1200 | 1200 | NULL | NULL
1 | 0 | data1 | 304 | 9704 | 4856 | 1200 | 1200 | 14125 | 21417
1 | 1 | data1 | 304 | 17392 | 160 | 1200 | 0 | NULL | NULL
1 | 2 | data1 | 304 | 36544 | 9760 | 1200 | 1200 | 1375.043496121433 | 2084.906658862494
1 | 3 | data1 | 304 | 89976 | 19792 | 1200 | 1200 | NULL | NULL
1 | 0 | data1 | 304 | 14560 | 1816 | 445 | 445 | 21429 | 23997
1 | 1 | data1 | 304 | 17552 | 160 | 445 | 0 | NULL | NULL
1 | 2 | data1 | 304 | 46304 | 3720 | 445 | 445 | 2086.0748374078717 | 2336.065046118657
1 | 3 | data1 | 304 | 109768 | 7576 | 445 | 445 | NULL | NULL
(16 rows)Функция show_range извлекает сегмент сырых физических данных из MARS2 и представляет его в удобочитаемом формате. Поддерживаемые типы данных: int2, int4, int8, float4, float8, timestamp, date, text.
Синтаксис
SELECT <* / column1,column2,...> FROM matrixts_internal.show_range(
tablename text,
attno int4,
forkno int4,
offno int4,
nbytes int4
)Параметры
tablename: Имя таблицы. Для секционированных таблиц используйте имя секционированной таблицы. (Обязательно)attno: Номер столбца, начинается с 0. (Обязательно)forkno: Идентификатор ветви физического файла. (Обязательно)offno: Смещение данных в байтах в физическом файле. (Обязательно)nbytes: Размер сегмента данных в байтах. (Обязательно)Примечание!
См. возвращаемые значения функцииdesc_rangesвыше для деталей параметров.
| Поле | Описание |
|---|---|
| rowno | Номер строки относительно RANGE (не абсолютная позиция в таблице) |
| val | Фактическое значение данных |
Примечание!
Отображаемые значения с плавающей точкой (val) могут содержать ошибки округления.
=# SELECT * FROM matrixts_internal.show_range('tb1', 1, 304, 16176, 808) LIMIT 20;
rowno | val
-------+-----
1 | 4
2 | 36
3 | 81
4 | 58
5 | 17
6 | 75
7 | 11
8 | 84
9 | 60
10 | 78
11 | 69
12 | 0
13 | 87
14 | 40
15 | 72
16 | 58
17 | 17
18 | 48
19 | 70
20 | 6
(20 rows)Функция dump_range распаковывает и экспортирует выбранные физические данные из MARS2 в двоичный файл для дальнейшего анализа.
Синтаксис
=# SELECT <* / column1,column2,...> FROM matrixts_internal.dump_ranges(
tablename text,
attno int4,
outfile text,
forkno int4,
offno int4,
limits int4
);Параметры
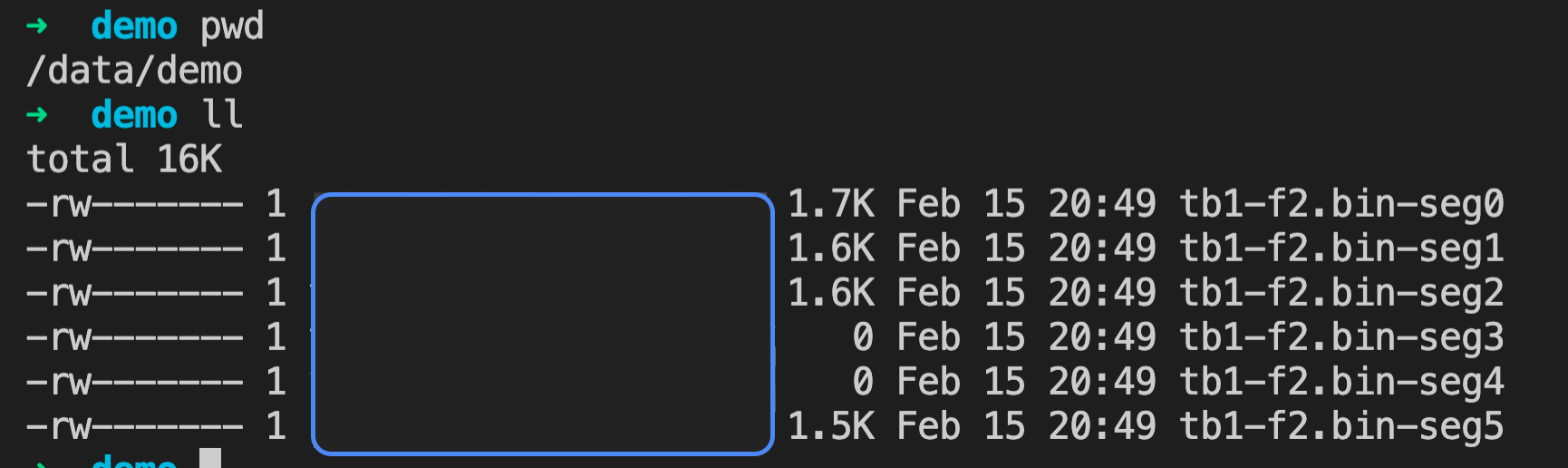
tablename: Имя таблицы. Для секционированных таблиц используйте имя дочерней секции. (Обязательно)attno: Номер столбца. (Обязательно)outfile: Путь к выходному файлу. После экспорта каждый сегмент добавляет уникальный суффикс. Например, если файл назван tb1-f2.bin, сегмент 1 сохранит его как tb1-f2.bin-seg1. (Обязательно)forkno: Идентификатор ветви. (Опционально)offno: Смещение в байтах в физическом файле. (Опционально)limits: Максимальное количество экспортируемых RANGE, начиная с указанного forkno и offno. По умолчанию — 100. (Опционально)Примечание!
Параметрlimitsограничивает количество экспортируемых RANGE на каждом сегменте.
Примечание!
См. описание возвращаемых значений функцииdesc_rangesдля контекста параметров.
Возвращаемые значения
nbytes: Объём экспортированных данных с каждого узла сегмента, в байтах.Пример
=# SELECT * FROM matrixts_internal.dump_ranges('tb1', 1, '/data/demo/tb1-f2.bin', 304, 16176, 1) LIMIT 20;
nbytes
--------
0
0
1480
1632
1704
1592
(6 rows)В этом примере возвращается шесть результатов, потому что экспорт выполняется независимо на каждом сегменте. Каждая строка представляет вывод одного сегмента. Два элемента показывают nbytes =0``, потому что эти сегменты не содержат данных, соответствующих критериям фильтрации.
После выполнения на каждом хосте сегмента создаётся двоичный файл с уникальным суффиксом (.-seg<no>).