Документ описывает настройку пользовательского мониторинга в YMatrix. Эта функция поддерживается начиная с версии v4.8.2.
Прежде чем приступить, убедитесь, что вы понимаете, как развернуть мониторинг Grafana или мониторинг Prometheus.
В качестве примера рассмотрим локальный мониторинг Grafana (matrixdb@mxagent).
Через одну-две минуты после завершения развертывания мониторинга вы можете запросить данные мониторинга из таблицы local.system в базе данных matrixmgr.

Эти данные собираются telegraf и вставляются в таблицу через mxgate. Процессы telegraf и mxgate развертываются как фоновые службы с помощью функции matrixdb, как показано в выводе команды supervisorctl status:
$ supervisorctl status
Status:
1. pc_id:{group:"mxui_collector" name:"mxui_collector"} describe:"pid 8223, uptime 2:27:36" now:1682517012 state:"Running" log_file:"/var/log/matrixdb/mxui_collector_5432.log" stdout_log_file:"/var/log/matrixdb/mxui_collector_5432.log" pid:8223
2. pc_id:{group:"mxmgr_gate_ctrl" name:"mxmgr_gate_ctrl"} describe:"pid 10295, uptime 2:25:28" now:1682517012 state:"Running" log_file:"/var/log/matrixdb/mxmgr_gate_ctrl_5432.log" stdout_log_file:"/var/log/matrixdb/mxmgr_gate_ctrl_5432.log" pid:10295
3. pc_id:{group:"mxmgr_telegraf_ctrl" name:"mxmgr_telegraf_ctrl"} describe:"pid 10350, uptime 2:25:26" now:1682517012 state:"Running" log_file:"/var/log/matrixdb/mxmgr_telegraf_ctrl_5432.log" stdout_log_file:"/var/log/matrixdb/mxmgr_telegraf_ctrl_5432.log" pid:10350
4. pc_id:{group:"cylinder" name:"cylinder"} describe:"pid 6038, uptime 2:33:30" now:1682517012 state:"Running" log_file:"/var/log/matrixdb/cylinder.log" stdout_log_file:"/var/log/matrixdb/cylinder.log" pid:6038
5. pc_id:{group:"mxui" name:"mxui"} describe:"pid 6041, uptime 2:33:30" now:1682517012 state:"Running" log_file:"/var/log/matrixdb/mxui.log" stdout_log_file:"/var/log/matrixdb/mxui.log" pid:6041Данные, хранящиеся в таблице local.system, используются в основном для отображения диаграмм мониторинга кластера на дашбордах Grafana.
Системная информация, собираемая в таблице local.system, включает 24 категории метрик выполнения. При наличии опыта эксплуатации вы можете изучить их содержимое:
matrixmgr=# select distinct category from local.system order by 1;
category
---------------
cpu
disk
diskio
kernel
mem
net
netstat
postgresql
processes
sar_cpu
sar_cpu_util
sar_disk
sar_hugepages
sar_inode
sar_io
sar_mem
sar_network
sar_paging
sar_queue
sar_swap
sar_swap_util
sar_task
swap
system
(24 rows)Начиная с версии v4.8.2, YMatrix поддерживает пользовательский мониторинг. Вы можете определить собственные скрипты мониторинга, которые могут либо вставляться в таблицу local.system, либо отправляться в Prometheus. После успешной настройки вы сможете создавать пользовательские панели и оповещения на Grafana.
После развертывания компонентов мониторинга пользовательские скрипты мониторинга находятся в следующей директории: /etc/matrixdb/scripts.
В этой директории содержатся:
monitor_bootstrap.sh
Это точка входа для пользовательского мониторинга. Содержимое предварительно задано и не должно изменяться пользователями. Процесс telegraf периодически вызывает этот скрипт для сбора данных пользовательского мониторинга.
monitor_plugins/
Эта директория предназначена для пользовательских скриптов. По соображениям безопасности только пользователь root имеет права на запись в эту директорию.
Ниже приведены два примера пользовательских скриптов мониторинга, размещённых в директории monitor_plugins/:
nic.sh для отображения статистики сетевых интерфейсов (NIC):#!/bin/bash
style=grafana
#######################################################################
# NIC statistics
#######################################################################
nic_stats_output() {
METRIC="net_dev";
for NIC in $(ls /sys/class/net/ | grep -E 'eth|enp|ens|bond')
do
VAL=""
for f in $(ls /sys/class/net/$NIC/statistics/); do
v=$(cat /sys/class/net/$NIC/statistics/$f);
if [ "#$style" == "#prometheus" ];then
echo "matrixdb,device=$NIC,metric=$f $METRIC=$v"
continue
fi
if [ ! -z $VAL ];then
VAL+=","
fi
VAL+="$f=$v";
done
if [ "#$style" == "#grafana" ];then
echo "$METRIC,device=$NIC $VAL"
fi
done
}
nic_stats_outputЭтот скрипт выводит статистику из /sys/class/net/<NIC>/statistics/ на локальном хосте. При запуске вручную он выдаёт вывод вида:
net_dev,device=eth0 collisions=0,multicast=0,rx_bytes=54701811772,rx_compressed=0,rx_crc_errors=0,rx_dropped=0,rx_errors=0,rx_fifo_errors=0,rx_frame_errors=0,rx_length_errors=0,rx_missed_errors=0,rx_nohandler=0,rx_over_errors=0,rx_packets=328974378,tx_aborted_errors=0,tx_bytes=89613462060,tx_carrier_errors=0,tx_compressed=0,tx_dropped=0,tx_errors=0,tx_fifo_errors=0,tx_heartbeat_errors=0,tx_packets=283871697,tx_window_errors=0Правила формата вывода скрипта: каждая строка данных должна иметь следующую структуру:
net_dev.key=value тегов до первого пробела. Это метки метрики, например device=eth0.key=value, представляющих фактические значения метрик.interrupts.sh для отображения статистики аппаратных прерываний:#!/bin/bash
style=grafana
#######################################################################
# Hardware Interrupts
#######################################################################
interrupts_output() {
PATTERN=$(awk -F ':' '{i++; if(i>2){print $1}}' /proc/net/dev | sed 's/ //g' | tr '\n' '|' | sed 's/|$//')
egrep "$PATTERN" /proc/interrupts | awk -v style="#$style" \
'{ for (i=2;i<=NF-2;i++) sum[i]+=$i;}
END {
for (i=2;i<=NF-2; i++)
{
if(style=="#prometheus"){
print("matrixdb,device=cpu" i-2 " net_interrupts_by_cpu="sum[i]);
continue;
}
val=sprintf(val "cpu" i-2 "=" sum[i]);
if(i!=NF-2 )
val=sprintf(val ",");
}
if(style=="#grafana")
print("net_interrupts_by_cpu,device=all " val)
}'
egrep "$PATTERN" /proc/interrupts | awk -v style="#$style" \
'{ for (i=2;i<=NF-2; i++)
sum+=$i;
tags=sprintf("%s", $NF);
if (NR!=1)
val=sprintf(val ",");
val=sprintf(val tags "=" sum);
if(style=="#prometheus"){
print("matrixdb,device=" $NF " net_interrupts_by_queue=" sum)
}
sum=0;
} END{ if(style=="#grafana") print("net_interrupts_by_queue,device=all " val) }'
}
interrupts_outputПри однократном выполнении вывод будет следующим:
net_interrupts_by_cpu,device=all cpu0=284551104,cpu1=308556439
net_interrupts_by_queue,device=all eth0-Tx-Rx-0=298072844,eth0-Tx-Rx-1=295034700Примечание: Скрипты, размещённые в директории monitor_plugins/, должны иметь права на выполнение:
$ ls -l /etc/matrixdb/scripts/monitor_plugins/
-rwxr-xr-x 1 root root 1491 Apr 26 12:51 interrupts.sh
-rwxr-xr-x 1 root root 855 Apr 26 12:45 nic.shЕсли права на выполнение будут удалены, скрипт будет деактивирован и не будет запускаться во время периодического сбора.
После размещения пользовательских скриптов мониторинга и проверки формата вывода вы можете протестировать их с помощью telegraf --test.
Сначала найдите файл конфигурации telegraf в директории /tmp:
$ ls -l /tmp | grep telegraf
-rw-r--r-- 1 root root 12676 Apr 26 11:24 telegraf_5432.confЗапустите telegraf в тестовом режиме:
$ sudo /usr/local/matrixdb/bin/telegraf --config /tmp/telegraf_5432.conf --testВывод будет содержать результаты из ваших пользовательских скриптов, подтверждая их корректную загрузку:

После размещения скриптов они будут автоматически запускаться в каждом цикле сбора данных мониторинга системы. Подождите 1–2 минуты, затем выполните запрос к таблице local.system, чтобы убедиться, что данные пользовательского мониторинга были вставлены.
local.system, чтобы убедиться, что появились новые категории net_dev, net_interrupts_by_cpu и net_interrupts_by_queue:matrixmgr=# SELECT distinct category FROM local.system ORDER BY 1;
category
-------------------------
cpu
disk
diskio
kernel
mem
net
net_dev
net_interrupts_by_cpu
net_interrupts_by_queue
netstat
postgresql
processes
sar_cpu
sar_cpu_util
sar_disk
sar_hugepages
sar_inode
sar_io
sar_mem
sar_network
sar_paging
sar_queue
sar_swap
sar_swap_util
sar_task
swap
system
(27 rows)Запросите фактические собранные данные:
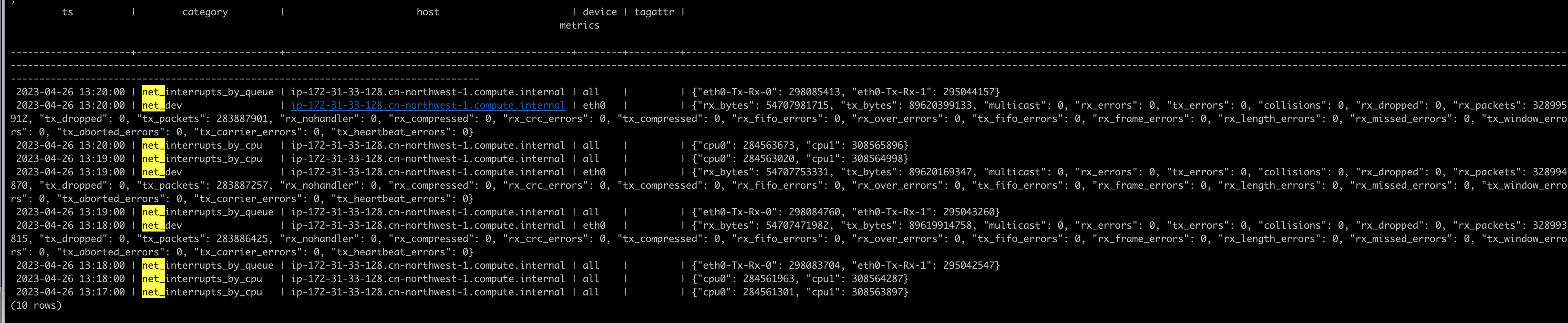
matrixmgr=# SELECT * FROM local.system
WHERE category IN ('net_interrupts_by_cpu', 'net_interrupts_by_queue', 'net_dev')
ORDER BY ts DESC LIMIT 10;Вывод показывает, что данные пользовательского скрипта сохранены в виде структурированных записей, готовых для анализа:
Для пользователей Prometheus перейдите по адресу http://<prometheus-server>:9090, чтобы убедиться, что пользовательские метрики присутствуют.
После того как данные попали в базу данных или Prometheus, вы можете создавать пользовательские панели на дашбордах Grafana и настраивать визуализации по своему усмотрению.
Это не является основной целью данного документа, поэтому приведены только базовые шаги.
В качестве примера для пользователей, не использующих Prometheus, напишите SQL-запрос для извлечения данных мониторинга:

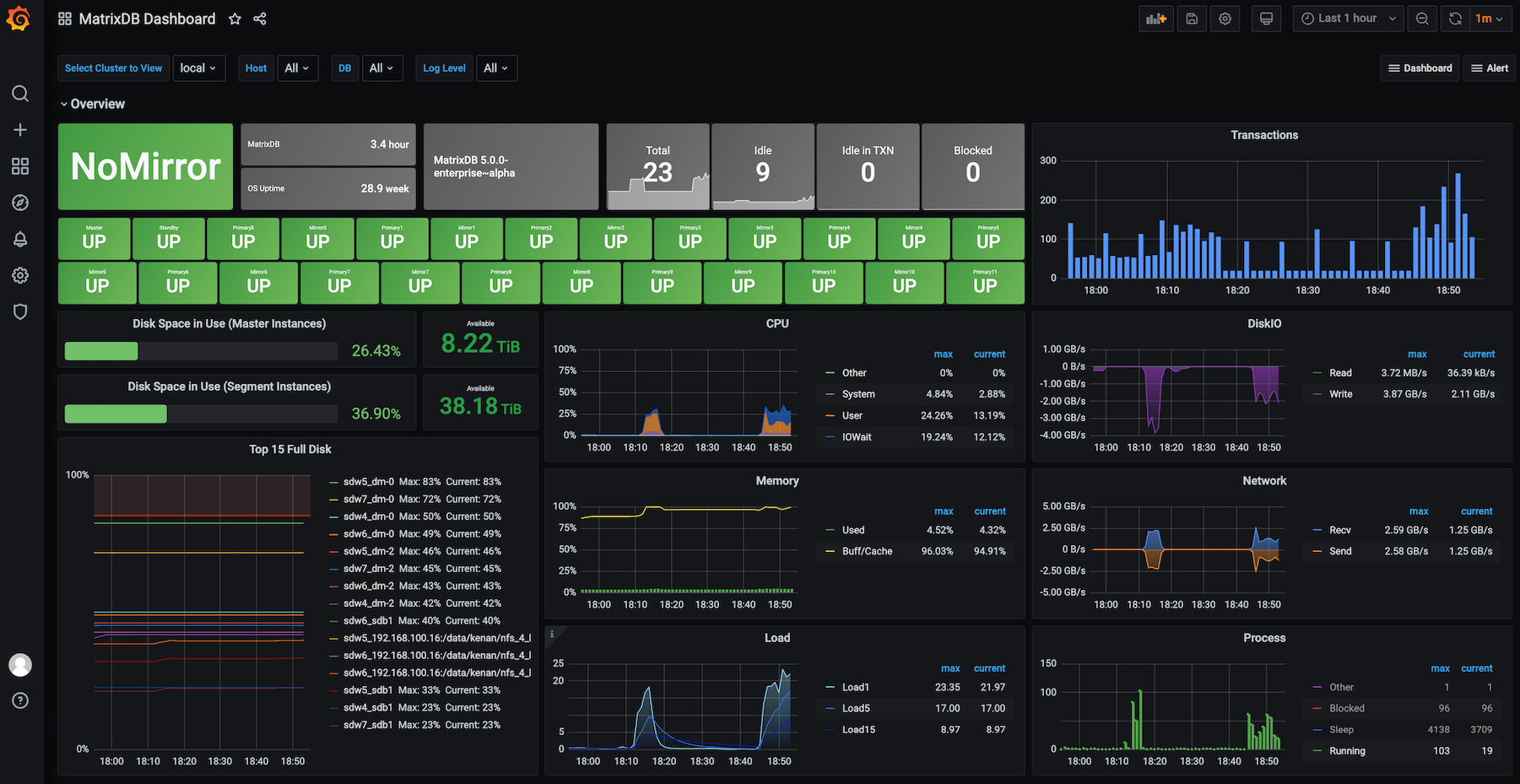
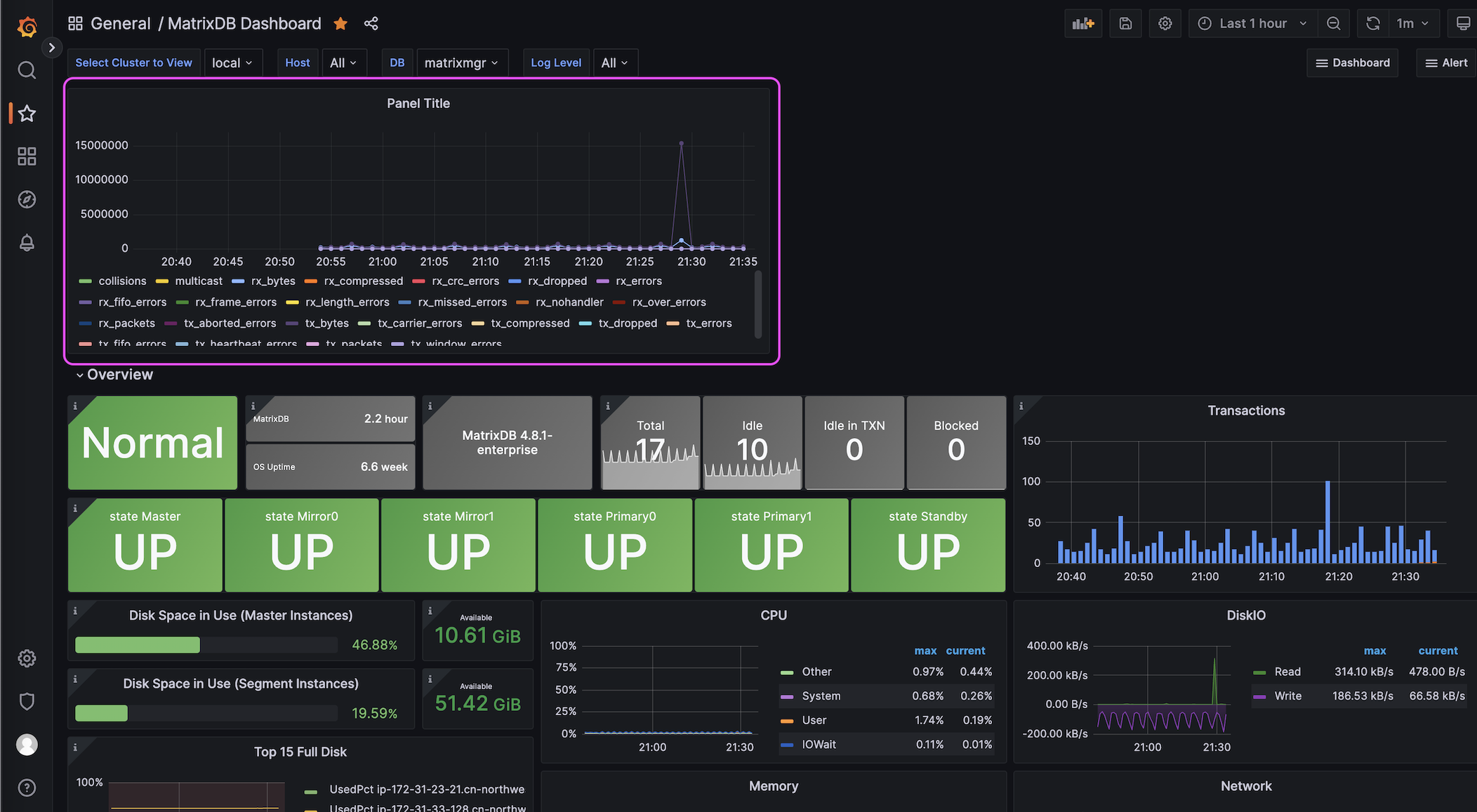
После добавления панели данные пользовательского мониторинга будут визуализированы, например, в виде линейного графика:
Щёлкните значок шестерёнки для настройки оповещений: