Для распределённых баз данных с огромным объёмом хранения, по мере роста объёма данных, нехватка ёмкости и вычислительных ресурсов кластера неизбежна, поэтому операции масштабирования являются обязательными. В MatrixDB вы можете свободно выбрать использование графического интерфейса для выполнения масштабирования или командной строки для онлайн-масштабирования.
Примечание!
При масштабировании емкости необходимо заранее установить на добавляемый узел ту же версию MatrixDB, что и в текущем кластере базы данных.
При нажатии кнопки масштабирования в правом верхнем углу страницы «Управление кластером» вы попадёте на страницу описания масштабирования, где подробно описаны этапы, временные рамки и подготовительные действия перед масштабированием. Это позволит вам детально понять, что такое масштабирование и как оно влияет на систему.
Нажмите «Далее» на странице описания, чтобы перейти на страницу добавления узлов. После входа система сначала соберёт информацию о всех узлах, уже существующих в текущем кластере.
После сбора информации об узлах вы увидите, что в кластере уже существует 3 узла:
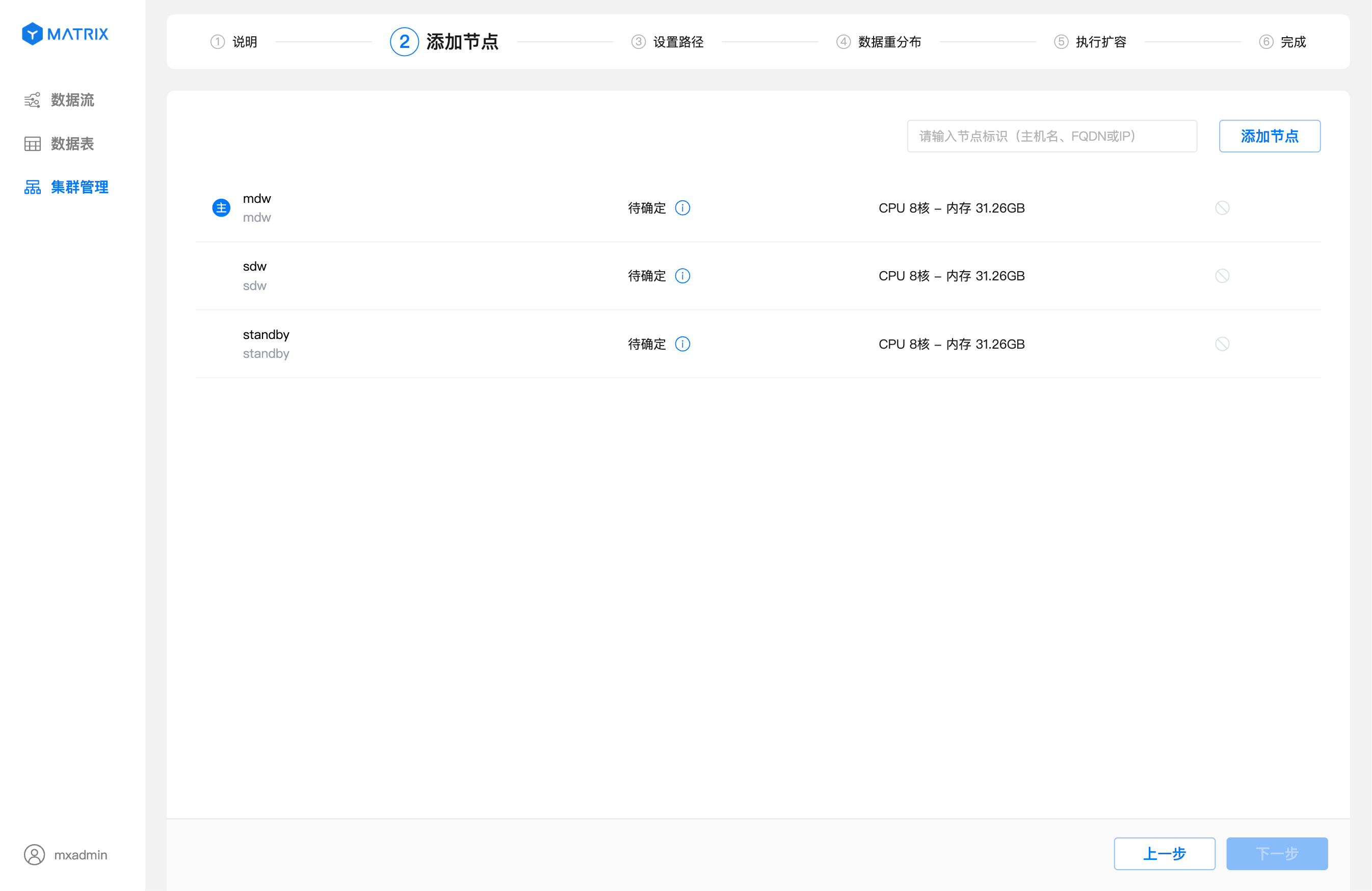
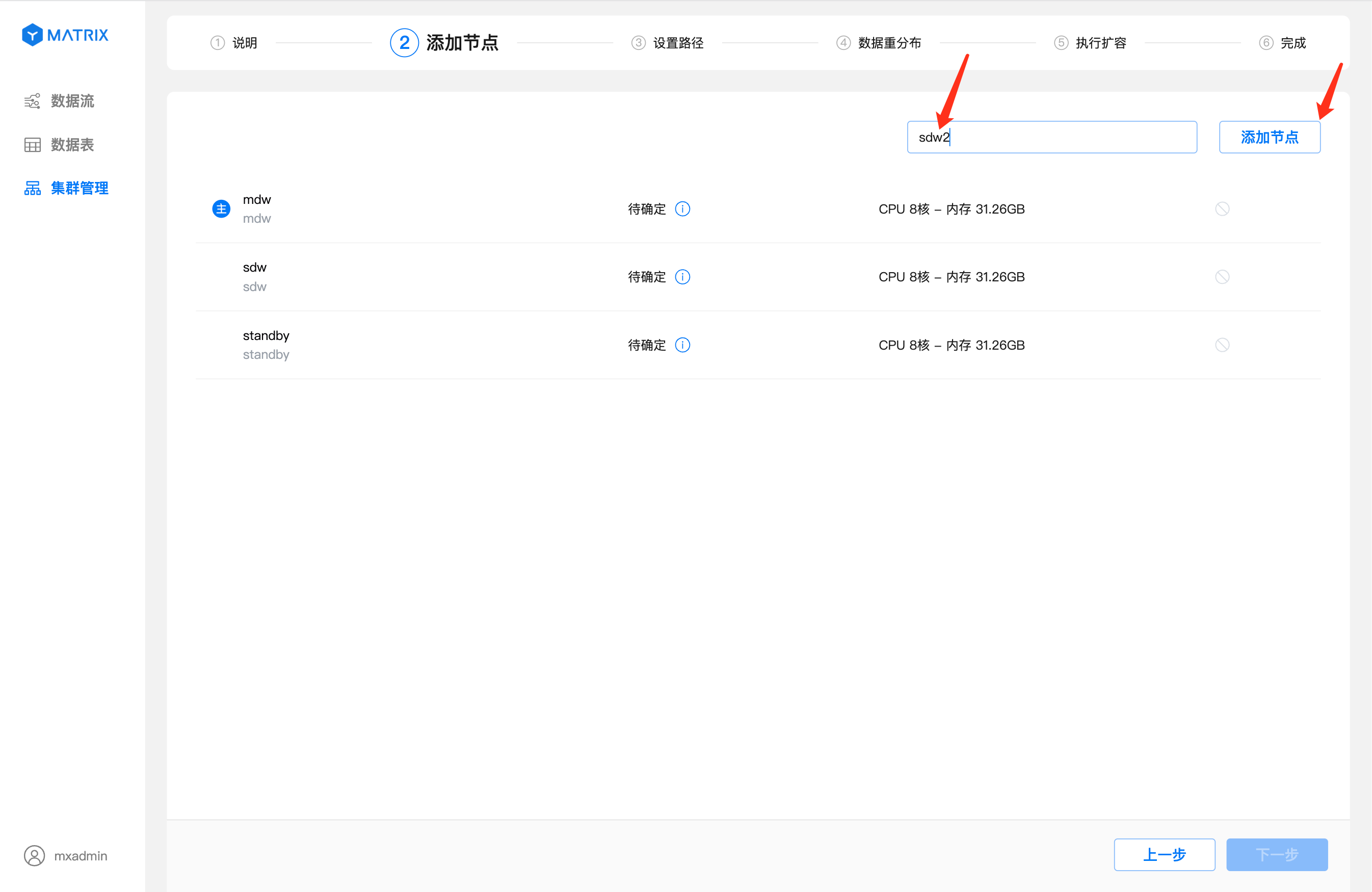
Введите идентификатор подготовленного узла (может быть хостнейм, FQDN или IP-адрес) в поле ввода в правом верхнем углу и нажмите кнопку «Добавить узел».
Как показано на рисунке, операция добавления узлов выполнена успешно, и новые узлы будут расположены ниже главного узла по порядку. Если вы хотите удалить узел, нажмите значок справа от добавленного узла.
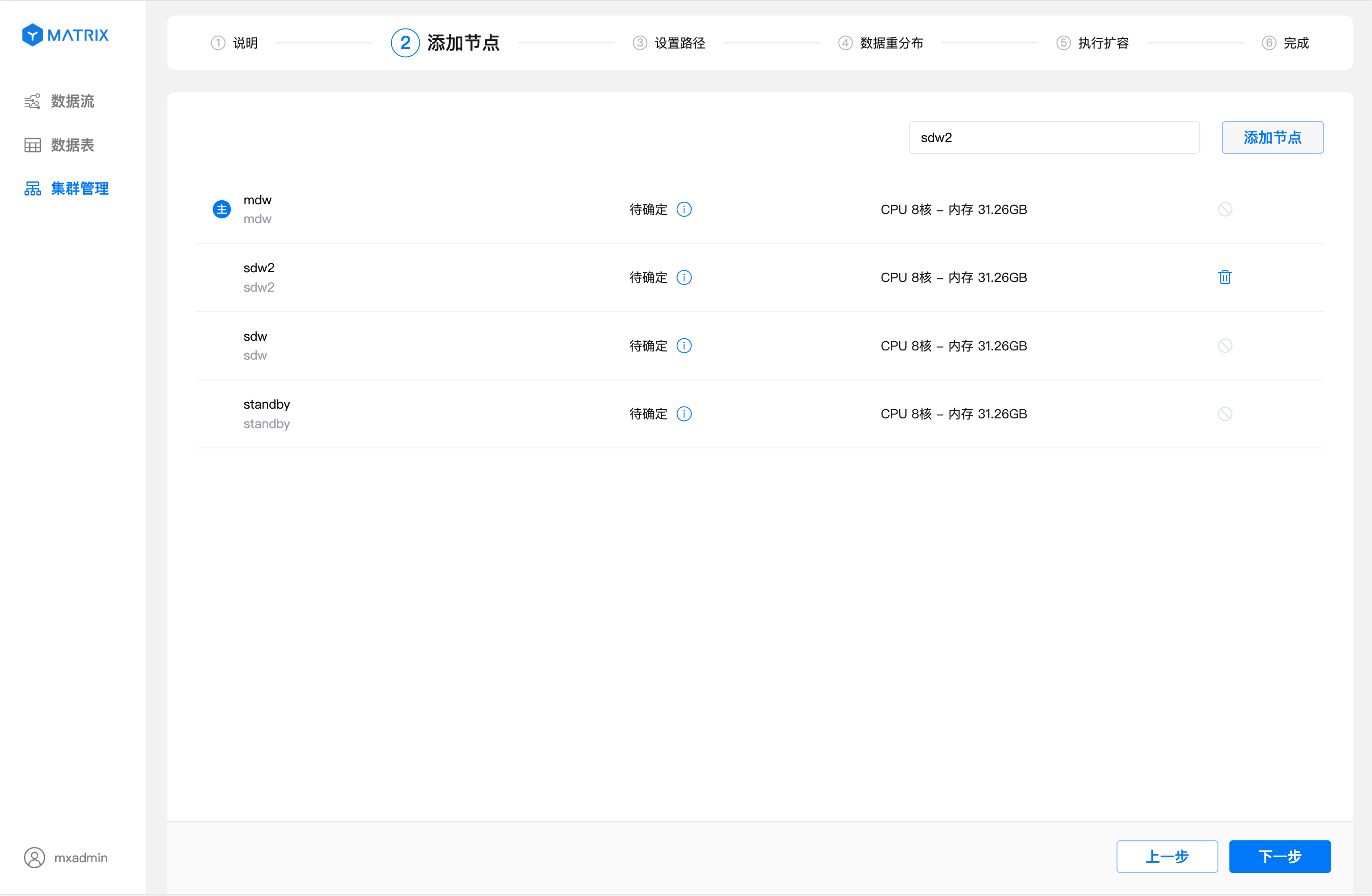
После успешного добавления узла нажмите «Далее», чтобы перейти на страницу настройки путей. На этой странице вы можете задать пути хранения для новых узлов.
Примечание!
Новые узлы, добавляемые через графический интерфейс, являются узлами данных, поэтому для каждого из них можно задать несколько путей хранения.
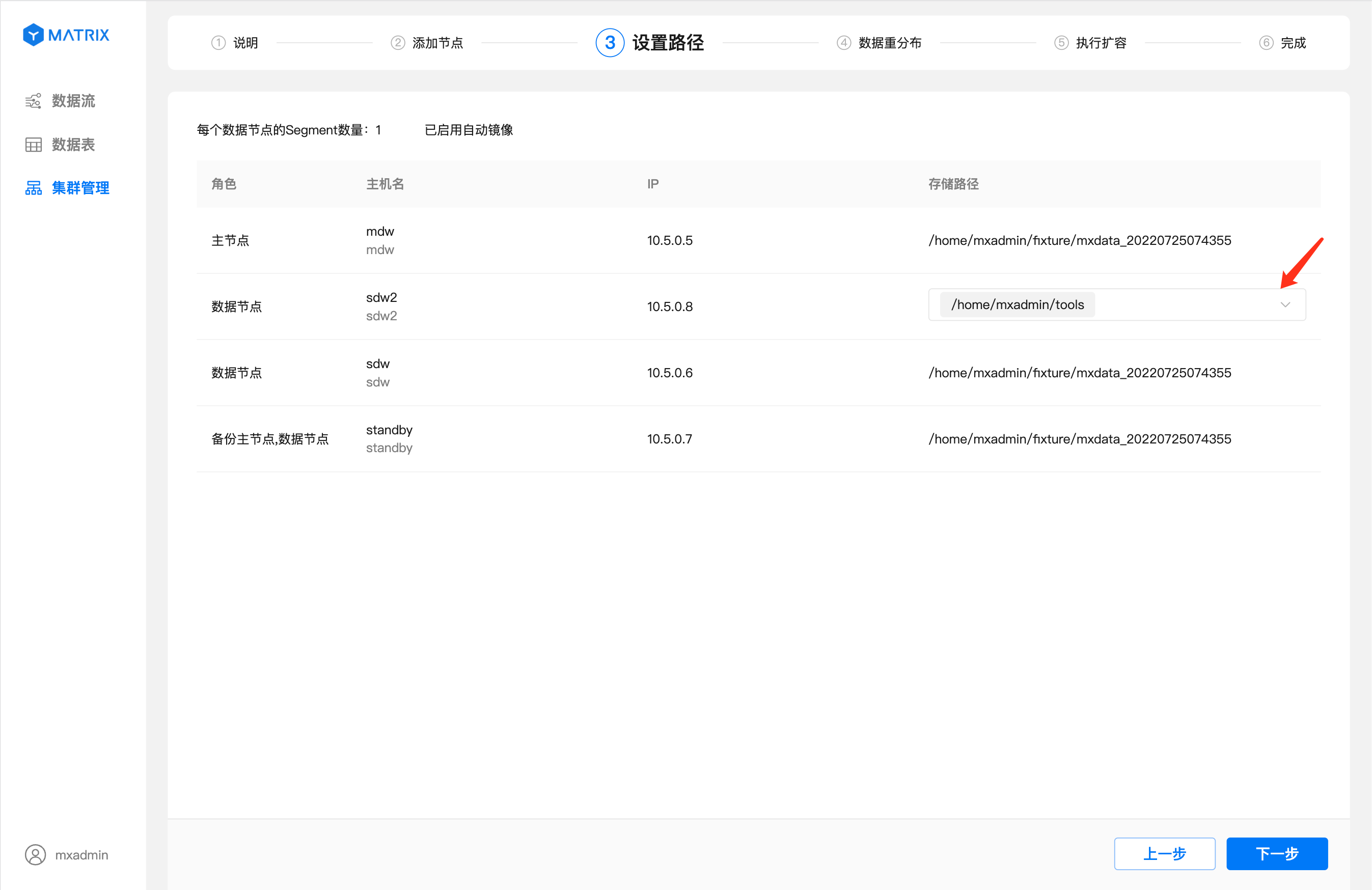
После настройки путей нажмите «Далее», чтобы перейти на страницу перераспределения данных. На этой странице вы можете выбрать время для перераспределения данных: доступны два варианта — «Выполнить сейчас» и «Задать время».
Выполнить сейчас: после выполнения плана добавления узлов на странице «Выполнить масштабирование» перераспределение данных начнётся немедленно.
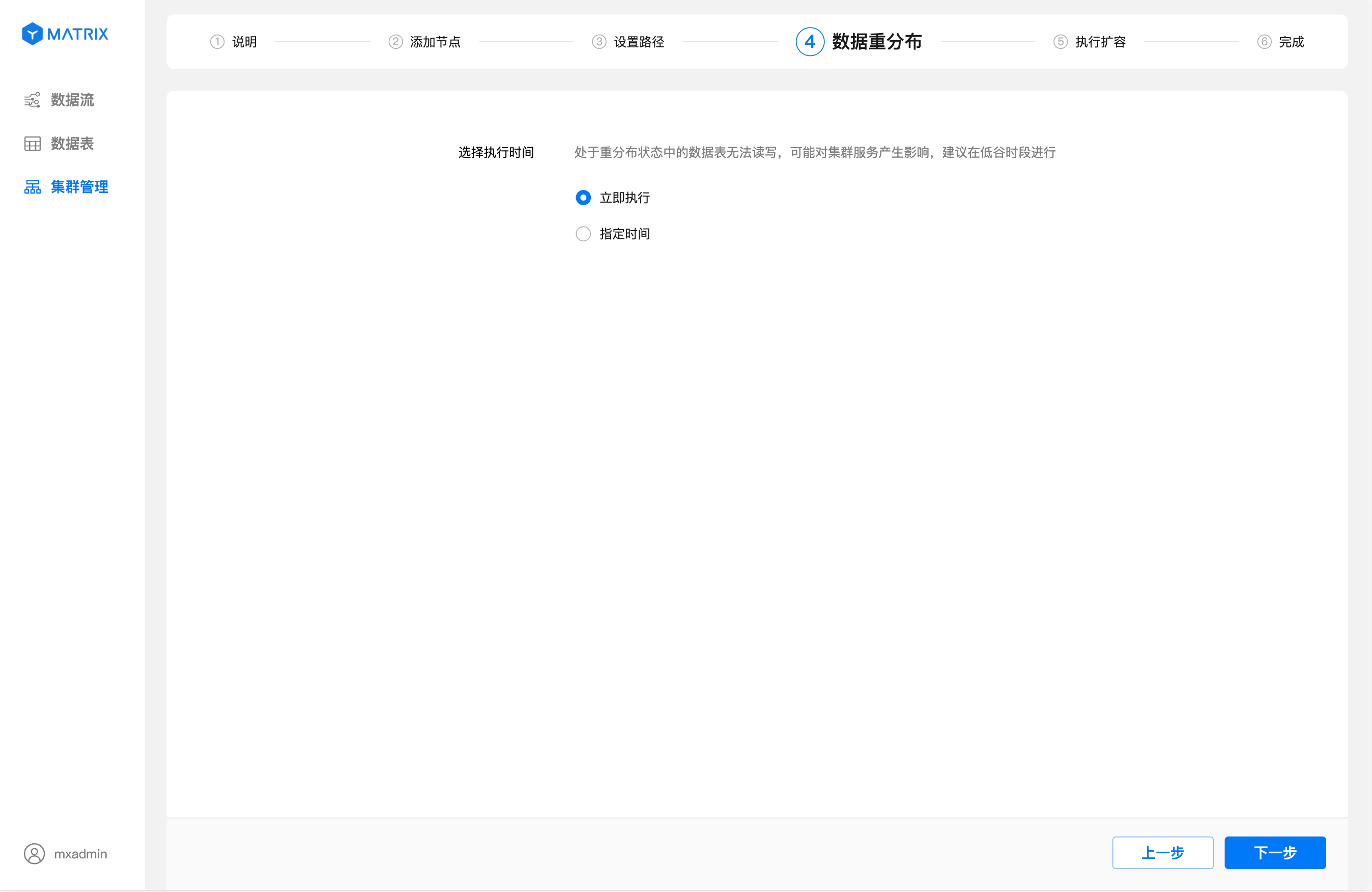
Задать время: вы можете самостоятельно выбрать будущее время для начала перераспределения данных.
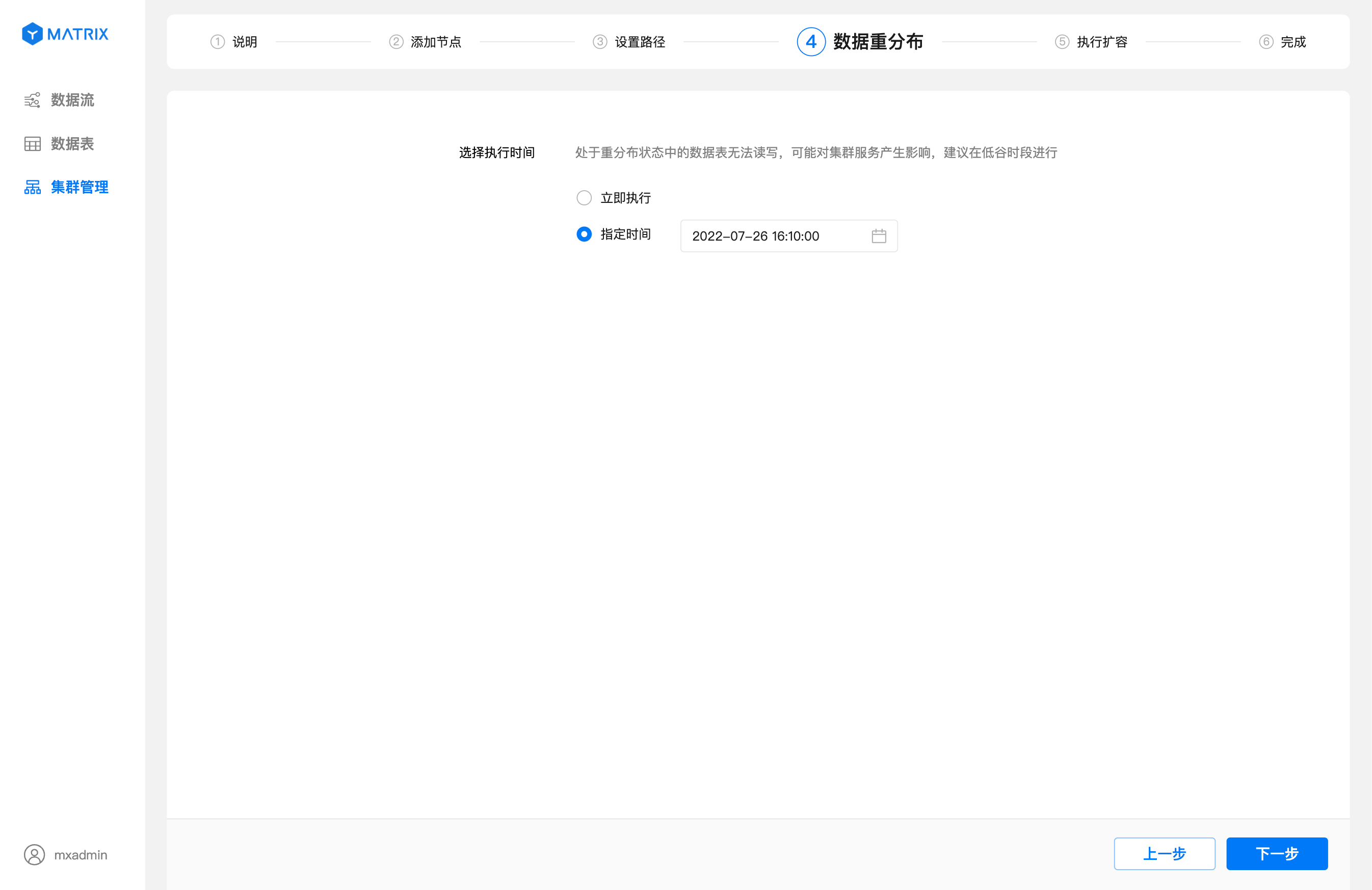
После установки времени перераспределения нажмите «Далее», чтобы перейти на страницу выполнения масштабирования. На этой странице вы можете просмотреть информацию о добавленных узлах и заданное время выполнения перераспределения.
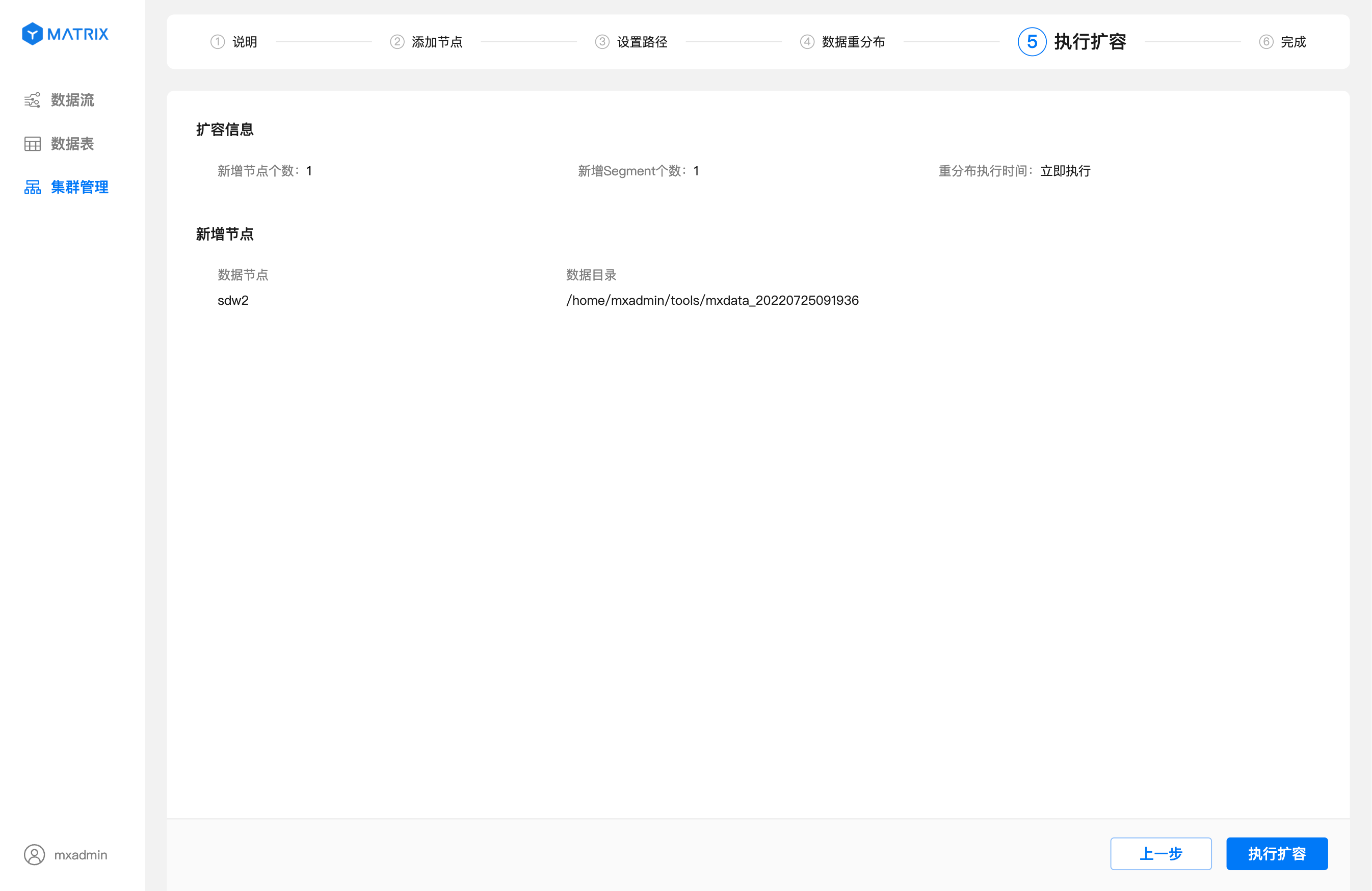
Укажите время перераспределения.
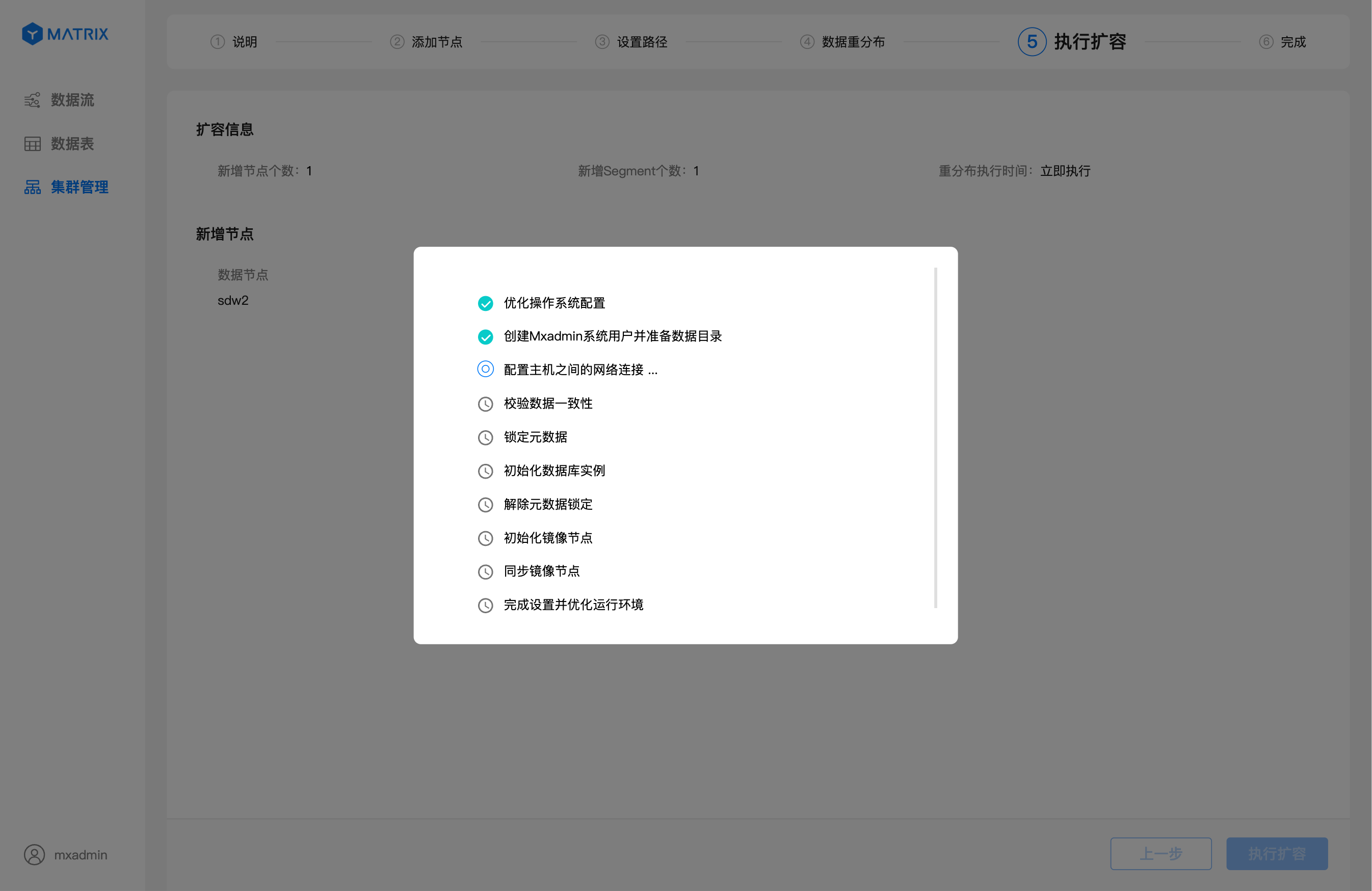
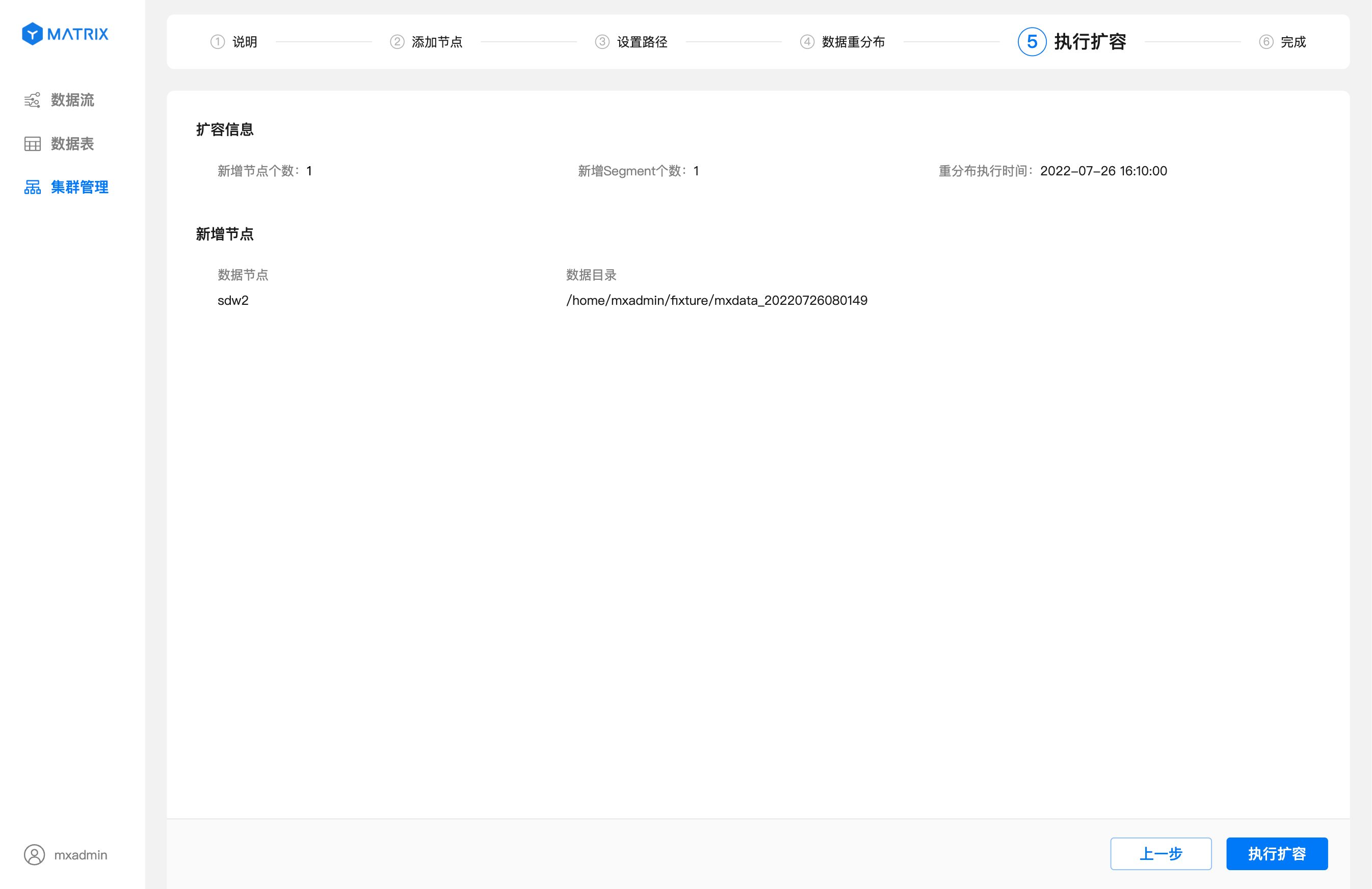 При нажатии кнопки «Выполнить масштабирование» в правом нижнем углу система официально запустит план добавления узлов.
При нажатии кнопки «Выполнить масштабирование» в правом нижнем углу система официально запустит план добавления узлов.
После успешного выполнения добавления узлов система перейдёт на страницу «Завершено», где отображается время выполнения задачи перераспределения данных.
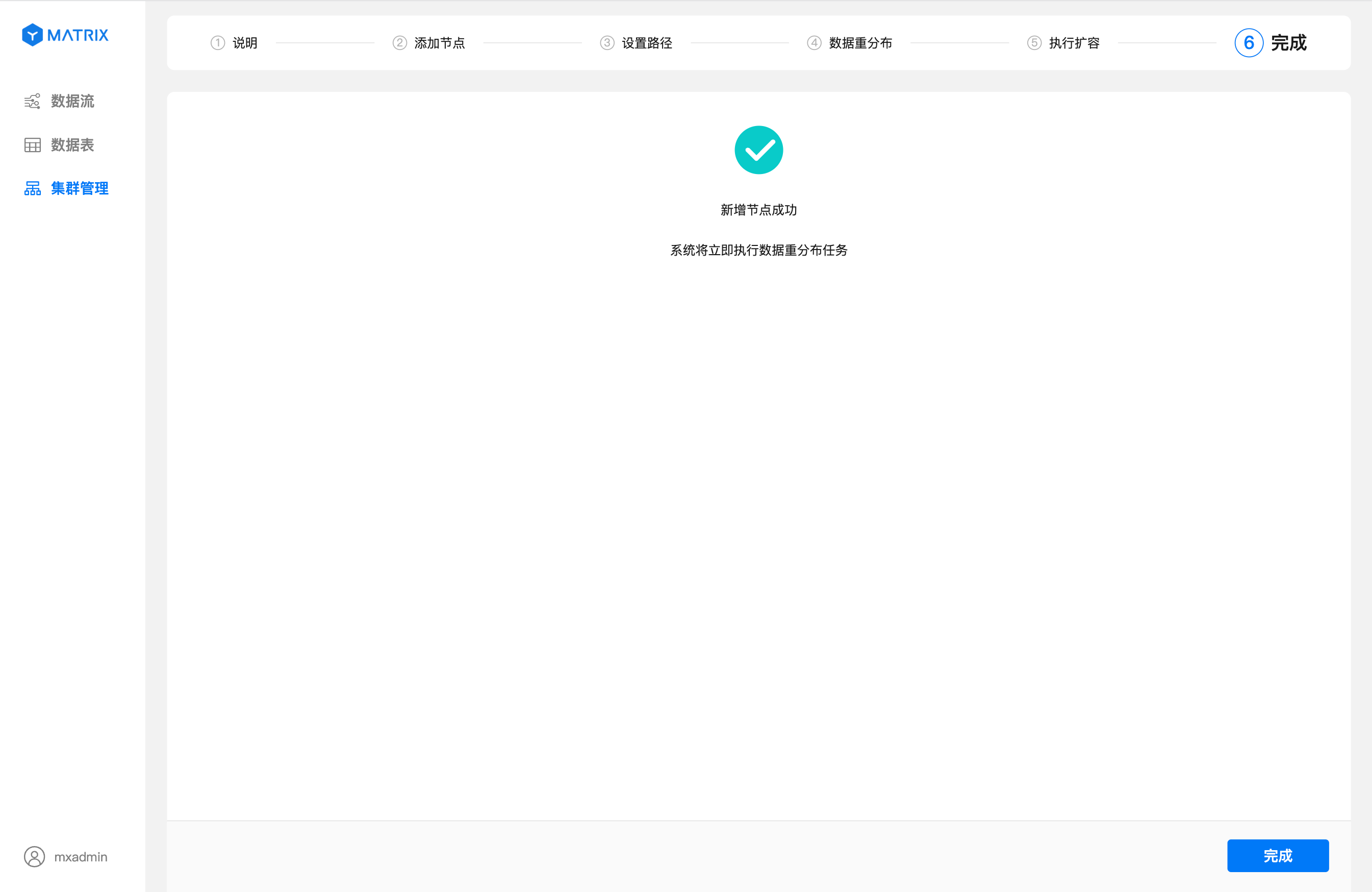
Отображение страницы завершения с указанием времени перераспределения.
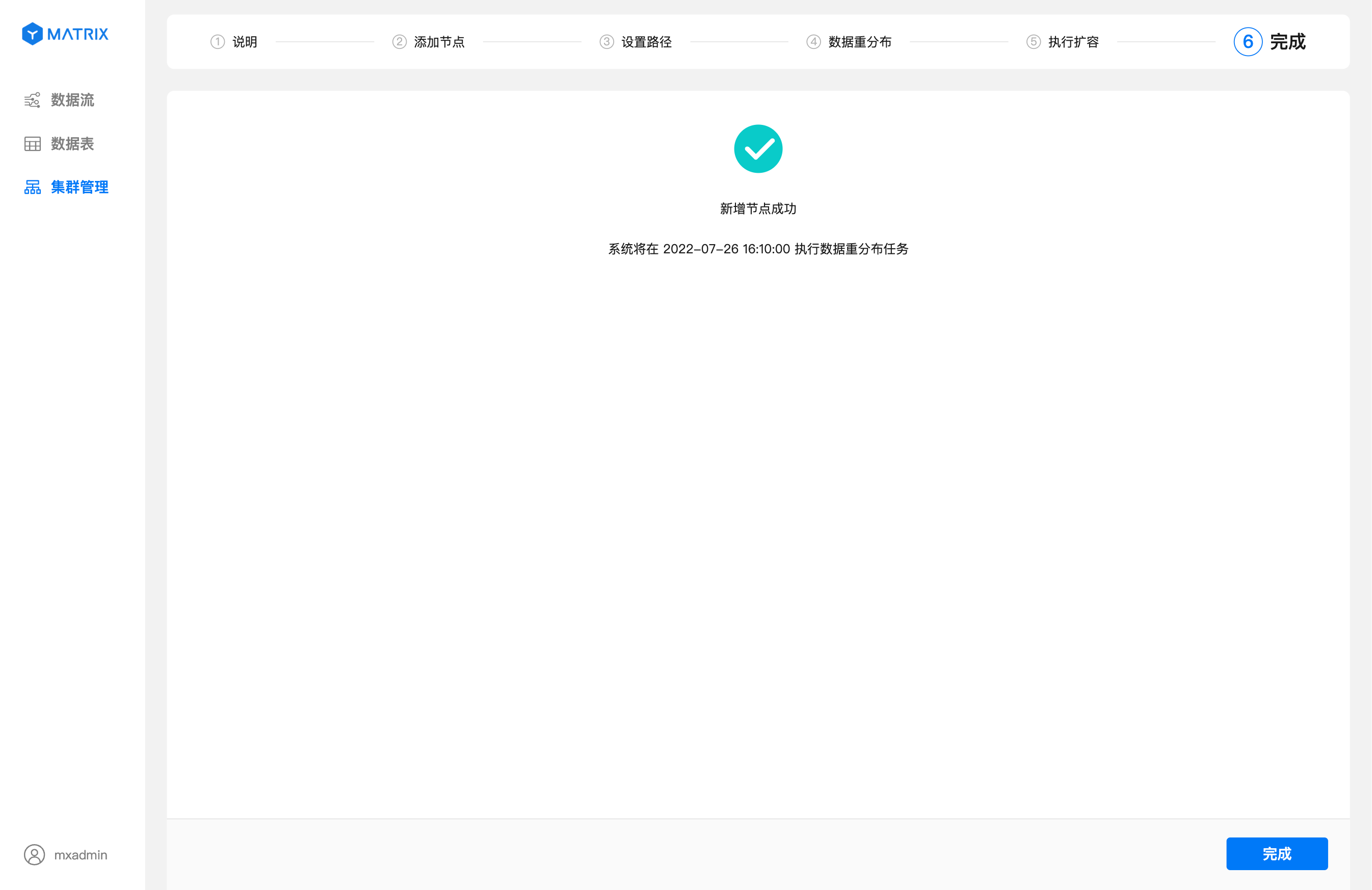
Нажмите кнопку «Завершить» в правом нижнем углу, чтобы вернуться на страницу «Управление кластером». Теперь вы сможете видеть информацию о прогрессе перераспределения данных и данные о новых узлах.
Примечание!
Пока выполняется задача масштабирования, кнопка масштабирования на странице управления кластером не может быть нажата повторно.
Если вы выбрали опцию «Задать время» для перераспределения, то после нажатия кнопки «Завершить» и перехода на страницу управления кластером вы увидите, что в верхней части страницы отображается текущая задача системы. Нажмите «Подробности», чтобы просмотреть детали задачи.
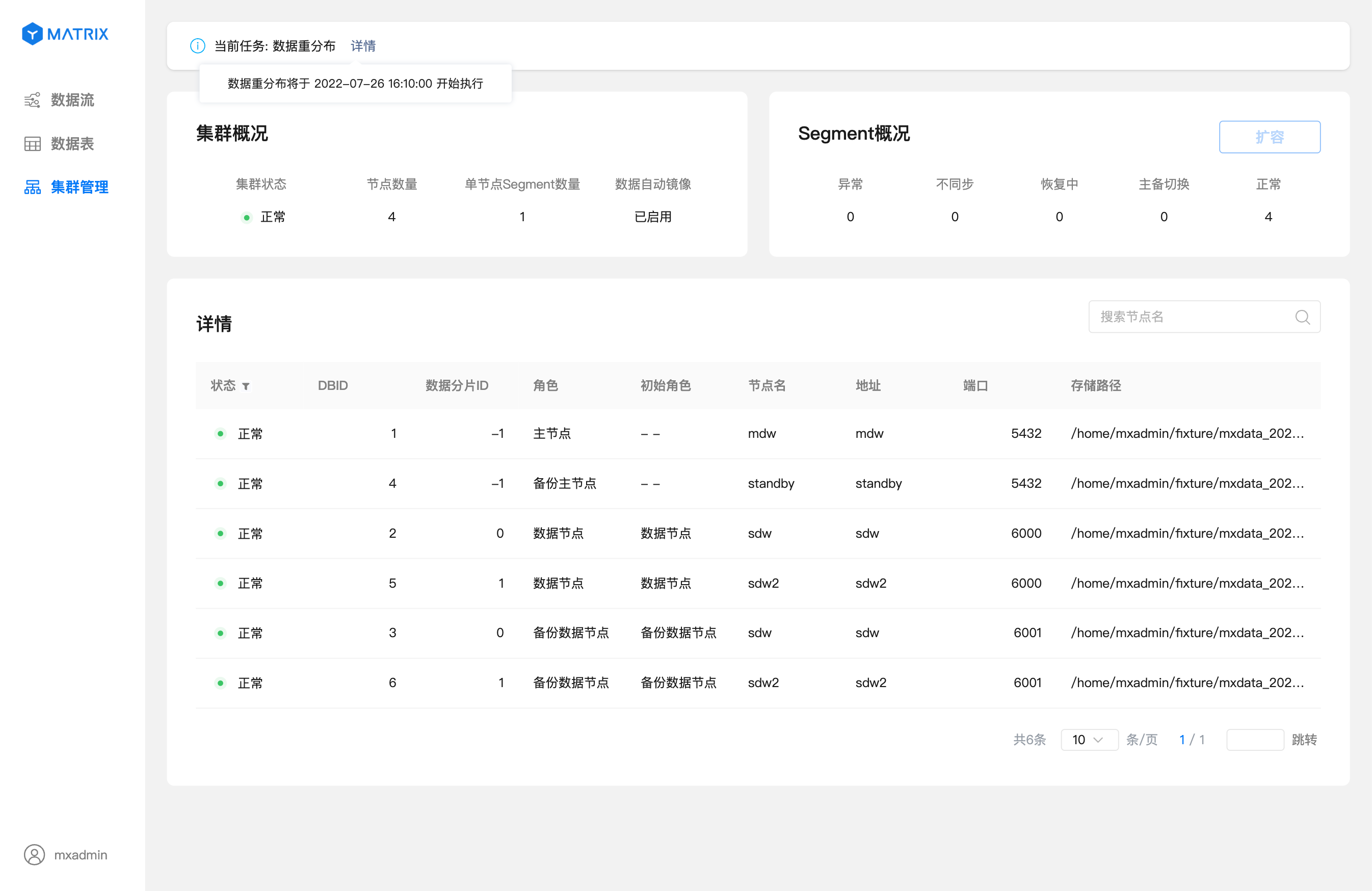
Когда перераспределение данных начнётся в указанное время, нажмите «Подробности» в правом верхнем углу, чтобы просмотреть информацию о прогрессе перераспределения:
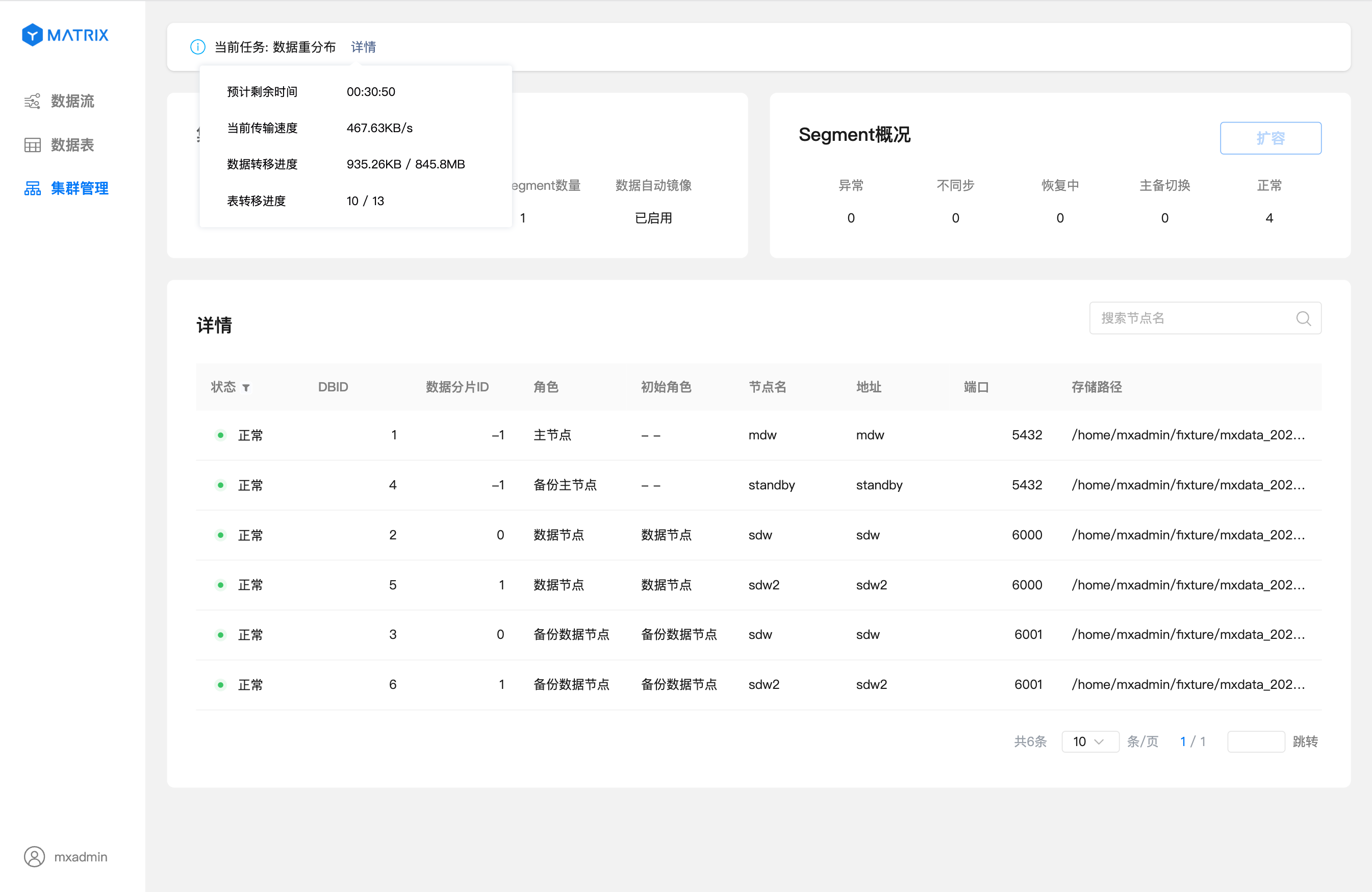
После завершения перераспределения глобальная панель задач изменится на:

Примечание!
Глобальная панель задач в верхней части страницы отображается на всех графических страницах, кроме случаев, когда вы нажимаете кнопку «Закрыть» на панели задач.
Основные компоненты:
Онлайн-масштабирование через командную строку состоит из двух этапов:
Этот этап добавляет новый узел данных (сегмент) в кластер и запускает его использование, однако исходные данные таблиц остаются на старых узлах.
Чтобы добавить новый узел, необходимо предоставить файл конфигурации развертывания. Его можно написать вручную или автоматически сгенерировать с помощью инструмента gpexpand. Рекомендуется использовать автоматический способ генерации.
Выполните gpexpand:
[mxadmin@mdw ~]$ gpexpand
......
Please refer to the Admin Guide for more information.
Would you like to initiate a new System Expansion Yy|Nn (default=N):Введите y, чтобы перейти в режим:
> yЗатем система запросит ввести имена новых хостов, разделённые запятыми:
Enter a comma separated list of new hosts you want
to add to your array. Do not include interface hostnames.
**Enter a blank line to only add segments to existing hosts**[]:
> sdw3,sdw4Убедитесь, что новые хосты подключены к сети и установлено взаимное доверие с существующими узлами. Также убедитесь, что
rsyncустановлен.
Сколько дополнительных машин добавляется на каждый узел? Значение, которое вы вводите, определяет количество сегментов, добавляемых на основе количества сегментов, развернутых на исходном узле. Если количество узлов на каждом хосте совпадает с исходным, просто введите 0.
How many new primary segments per host do you want to add? (default=0):
> 0
Generating configuration file...
20211102:14:36:24:024562 gpexpand:mdw:mxadmin-[INFO]:-Generating input file...
Input configuration file was written to 'gpexpand_inputfile_20211102_143624'.
Please review the file and make sure that it is correct then re-run
with: gpexpand -i gpexpand_inputfile_20211102_143624
20211102:14:36:24:024562 gpexpand:mdw:mxadmin-[INFO]:-Exiting...После выполнения в текущей директории будет создан файл конфигурации gpexpand_inputfile_20211102_143624:
[mxadmin@mdw ~]$ cat gpexpand_inputfile_20211102_143624
sdw3|sdw3|7002|/home/mxadmin/gpdemo/datadirs/dbfast1/demoDataDir3|5|3|p
sdw3|sdw3|7003|/home/mxadmin/gpdemo/datadirs/dbfast2/demoDataDir4|6|4|p
sdw3|sdw3|7004|/home/mxadmin/gpdemo/datadirs/dbfast3/demoDataDir5|7|5|p
sdw4|sdw4|7002|/home/mxadmin/gpdemo/datadirs/dbfast1/demoDataDir6|8|6|p
sdw4|sdw4|7003|/home/mxadmin/gpdemo/datadirs/dbfast2/demoDataDir7|9|7|p
sdw4|sdw4|7004|/home/mxadmin/gpdemo/datadirs/dbfast3/demoDataDir8|10|8|pФайл конфигурации содержит информацию о новых хостах, а также новые номера портов сегментов, каталоги данных, dbid, роли и другие параметры. Эта информация соответствует таблице gp_segment_configuration. Файл конфигурации также можно создать вручную в этом формате.
После подготовки файла конфигурации выполните следующую команду для добавления нового узла:
[mxadmin@mdw ~]$ gpexpand -i gpexpand_inputfile_20211102_143624
......
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Unlocking catalog
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Unlocked catalog
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Creating expansion schema
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Populating gpexpand.status_detail with data from database postgres
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Populating gpexpand.status_detail with data from database template1
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Populating gpexpand.status_detail with data from database mxadmin
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-************************************************
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Initialization of the system expansion complete.
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-To begin table expansion onto the new segments
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-rerun gpexpand
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-************************************************
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Exiting...После успешного выполнения запросите таблицу gp_segment_configuration — вы увидите, что новый узел был успешно добавлен.
Второй этап онлайн-масштабирования — перераспределение данных таблиц на новые узлы, поскольку на добавленных сегментах пока нет данных.
MatrixDB поддерживает три метода распределения: случайное, хеширование и репликация. Все данные должны быть синхронизированы с новыми сегментами в соответствии с правилами. При этом:
После завершения первого этапа в базе данных postgres будет создана схема gpexpand, содержащая информацию о статусе масштабирования:
postgres=# \d
List of relations
Schema | Name | Type | Owner | Storage
----------+-----------------------------------------------------------------------------------------------------------------------
gpexpand | expansion_progress | view | mxadmin |
gpexpand | status | table | mxadmin | heap
gpexpand | status_detail | table | mxadmin | heap
(3 rows)Таблица status_detail содержит список всех таблиц, требующих перераспределения, и их статус:
postgres=# select * from gpexpand.status_detail ;
dbname | fq_name | table_oid | root_partition_name | rank | external_writable | status | expansion_started | expansion_finished | source_bytes
---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
mxadmin | public.t2 | 16388 | | 2 | f | NOT STARTED | | | 8192
mxadmin | public.t1 | 16385 | | 2 | f | NOT STARTED | | | 16384
mxadmin | public.disk | 16391 | public.disk | 2 | f | NOT STARTED | | | 0
(3 rows)Запустите gpexpand для выполнения перераспределения таблиц:
[mxadmin@mdw ~]$ gpexpand
......
gpexpand:mdw:mxadmin-[INFO]:-Querying gpexpand schema for current expansion state
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Expanding mxadmin.public.t2
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Finished expanding mxadmin.public.t2
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Expanding mxadmin.public.t1
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Finished expanding mxadmin.public.t1
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Expanding mxadmin.public.disk
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Finished expanding mxadmin.public.disk
20211102:15:18:32:026291 gpexpand:mdw:mxadmin-[INFO]:-EXPANSION COMPLETED SUCCESSFULLY
20211102:15:18:32:026291 gpexpand:mdw:mxadmin-[INFO]:-Exiting...После завершения перераспределения запросите таблицу status_detail — вы увидите, что статус изменился на COMPLETED:
postgres=# select * from gpexpand.status_detail ;
dbname | fq_name | table_oid | root_partition_name | rank | external_writable | status | expansion_started | expansion_finished | source_bytes
---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
mxadmin | public.t2 | 16388 | | 2 | f | COMPLETED | 2021-11-02 15:18:27.326247 | 2021-11-02 15:18:27.408379 | 8192
mxadmin | public.t1 | 16385 | | 2 | f | COMPLETED | 2021-11-02 15:18:27.431481 | 2021-11-02 15:18:27.507591 | 16384
mxadmin | public.disk | 16391 | public.disk | 2 | f | COMPLETED | 2021-11-02 15:18:27.531727 | 2021-11-02 15:18:27.570559 | 0
(3 rows)Если вы хотите увеличить параллелизм перераспределения, добавьте параметр -B при выполнении команды gpexpand. Значение по умолчанию — 16, максимальное — 128, например:
[mxadmin@mdw ~]$ gpexpand -B 32После завершения перераспределения выполните gpexpand -c, чтобы очистить промежуточные таблицы процесса масштабирования:
[mxadmin@mdw ~]$ gpexpand -c
20211102:15:24:41:026524 gpexpand:mdw:mxadmin-[INFO]:-local Greenplum Version: 'postgres (MatrixDB) 5.0.0-enterprise~alpha (Greenplum Database) 7.0.0 build dev'
20211102:15:24:41:026524 gpexpand:mdw:mxadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 12 (MatrixDB 5.0.0-enterprise~alpha) (Greenplum Database 7.0.0 build dev) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180303 (Red Hat 7.3.1-5), 64-bit compiled on Oct 25 2021 15:24:16'
20211102:15:24:41:026524 gpexpand:mdw:mxadmin-[INFO]:-Querying gpexpand schema for current expansion state
Do you want to dump the gpexpand.status_detail table to file? Yy|Nn (default=Y):
> n
20211102:15:24:46:026524 gpexpand:mdw:mxadmin-[INFO]:-Removing gpexpand schema
20211102:15:24:46:026524 gpexpand:mdw:mxadmin-[INFO]:-Cleanup Finished. exiting...На этом масштабирование завершено успешно.
После выполнения перераспределения система автоматически создаст следующие системные каталоги (включая системные таблицы, представления и т.д.) и сохранит их в режиме matrixmgr_internal базы данных matrixmgr:
Эта таблица записывает временные метки состояний каждого этапа перераспределения данных. Содержит следующие поля:
| Имя поля | Тип | Описание |
|---|---|---|
| status | text | Отслеживает статус операции масштабирования. Допустимые значения: SCHEDULED START — время начала планируемого перераспределения; SETUP — время начала сбора информации о таблицах базы данных; SETUP DONE — время завершения сбора информации о таблицах; EXPANSION STARTED — время начала фактического перераспределения данных; COMPLETED — время завершения всех задач перераспределения; LAST SCHEDULED START — сохранённое значение SCHEDULED START после завершения всех задач, затем SCHEDULED START очищается |
| updated_at | timestamp with time zone | Временная метка последнего изменения состояния |
Эта таблица содержит информацию о статусе таблиц, участвующих в масштабировании. Вы можете запросить её, чтобы определить статус перераспределения конкретной таблицы или просмотреть временные метки начала и окончания завершённых задач. Отсутствие записи в этой таблице означает, что перераспределение не требуется.
Таблица также хранит информацию о таблицах, включая OID.
| Имя поля | Тип | Описание |
|---|---|---|
| dbname | text | Имя базы данных, к которой принадлежит таблица |
| db_oid | oid | OID базы данных, к которой принадлежит таблица |
| fq_name | text | Полное имя таблицы |
| table_oid | oid | OID таблицы |
| root_partition_name | text | Для партиционированных таблиц — имя корневой партиции; в противном случае — None |
| rank | int | Уровень определяет порядок масштабирования таблиц. Инструмент масштабирования сортирует таблицы по rank, обрабатывая сначала таблицы с меньшим значением |
| external_writable | boolean | Указывает, является ли таблица внешней записываемой таблицей (для них требуется особый синтаксис масштабирования) |
| status | text | Текущий статус масштабирования таблицы. Допустимые значения: NOT STARTED IN PROGRESS PENDING RETRYING COMPLETED FAILED |
| expansion_started_at | timestamp with time zone | Временная метка начала масштабирования этой таблицы |
| expansion_finished_at | timestamp with time zone | Временная метка завершения масштабирования этой таблицы. Также обновляется при сбое масштабирования |
| source_bytes | numeric | Объём данных, ещё не перераспределённых. Размер таблицы после масштабирования может отличаться от исходной из-за особенностей HEAP-таблиц и количества сегментов. Эта таблица предоставляет информацию о прогрессе и оценивает продолжительность процесса |
| failed_times | integer | Количество попыток повтора, значение по умолчанию — 5 |
Этот системный каталог — представление, содержащее общую информацию о состоянии масштабирования, включая оценку скорости перераспределения таблиц и оставшегося времени до завершения всех задач перераспределения.
| Имя поля | Тип | Описание |
|---|---|---|
| name | text | Имя метрики, описывающей процесс масштабирования, включает: Bytes Pending Bytes in Progress Bytes Done Bytes Failed Estimated Expansion Rate Estimated Remaining Time Done Tables Number Pending Tables Number In Progress Tables Number Failed Tables Number |
| value | text | Значение указанной метрики. Например, Bytes Pending: 100023434 |
Совпадают ли каталоги старых и новых узлов во время масштабирования?
Влияние на другие запросы во время масштабирования:
Подробные методы использования gpexpand см. в документации