Начало работы
Подключение
Тесты производительности
Развёртывание
Использование данных
Управление кластерами
Обновление
Глобальное обслуживание
Масштабирование
Мониторинг
Безопасность
Лучшие практики
Технические принципы
Типы данных
Хранилище
Исполняющий движок
Потоковая обработка (Domino)
MARS3 Индексы
Расширения
Расширенные функции
Расширенный запрос
Федеративные запросы
Grafana
Резервное копирование и восстановление
Аварийное восстановление
Графовая база данных
Введение
Предложения
Функции
Расширенные темы
Руководство
Настройка производительности
Устранение неполадок
Инструменты
Параметры конфигурации
SQL-команда
Часто задаваемые вопросы
MatrixDB поддерживает функцию бесшовного подключения к Kafka, которая позволяет непрерывно и автоматически импортировать данные из Kafka в таблицы MatrixDB, а также поддерживает графические операции.
Поддерживаемые форматы данных включают CSV и JSON. В этом разделе с помощью простейшего примера будет показано, как использовать платформу управления MatrixDB для доступа к данным Kafka.
Предположим, что сервис Kafka запущен на локальном порту 9092. Создадим тестовый топик с помощью следующей команды:
bin/kafka-topics.sh --create --topic csv_test --bootstrap-server localhost:9092Затем запишем несколько тестовых данных:
bin/kafka-console-producer.sh --topic csv_test --bootstrap-server localhost:9092
>1,1,1.0,abc
>2,2,2.0,bcd
>1,1,1.0,abc
>2,2,2.0,bcd
>^CС помощью указанной выше команды в только что созданный топик csv_test было записано 4 записи — 4 строки в формате CSV, разделённые запятыми.
Подключимся к базе данных test:
[mxadmin@mdw ~]$ psql test
psql (12)
Type "help" for help.
test=#Создадим тестовую таблицу:
CREATE TABLE dest (
c1 INT,
c2 FLOAT8,
c3 TEXT
) DISTRIBUTED BY(c1);После завершения подготовительных работ далее показано, как использовать графический интерфейс для настройки доступа.
Введите в браузере IP-адрес машины, где установлен MatrixGate (по умолчанию — IP-адрес mdw), порт и суффикс datastream:
http://<IP>:8240/datastreamОткроется следующая страница, нажмите «Далее»:
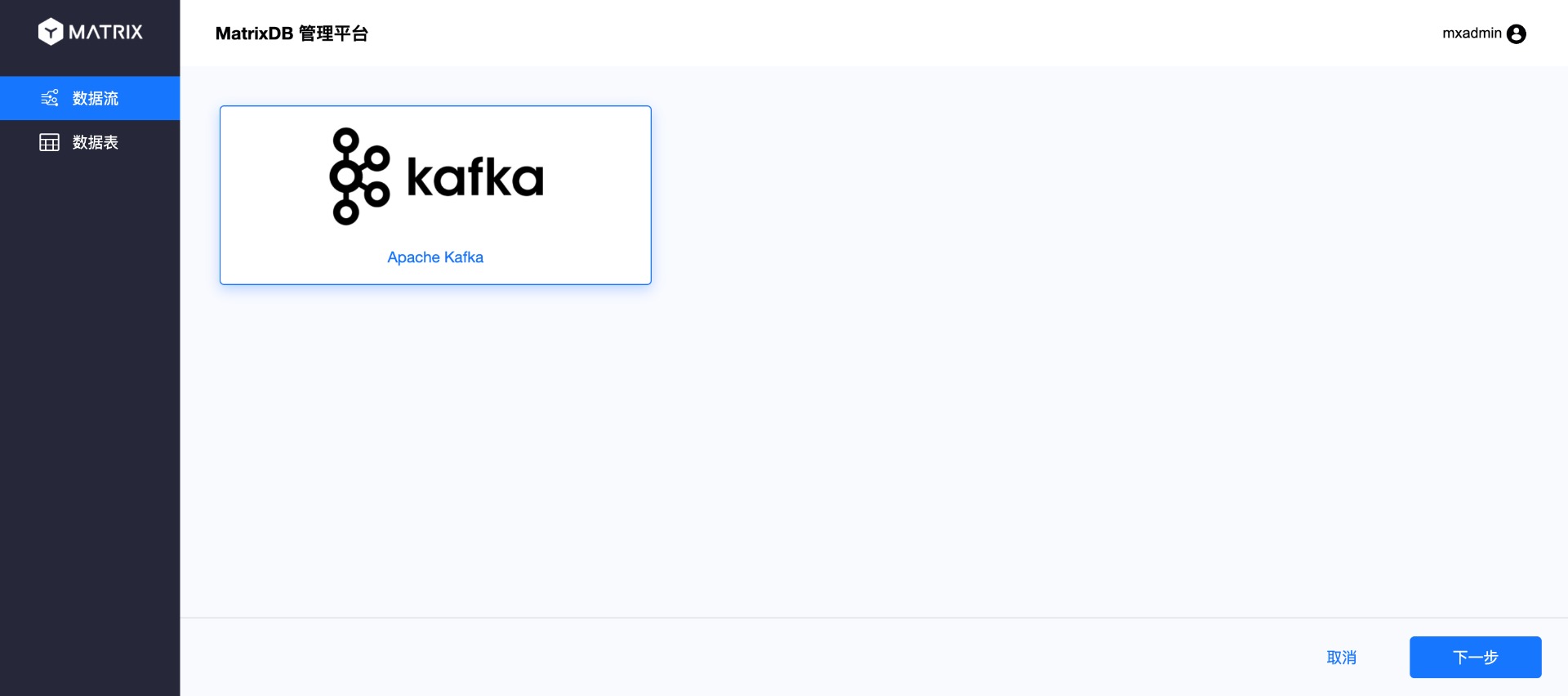
Из панели навигации в верхней части страницы видно, что весь процесс разделён на 6 шагов: подключение, выбор, анализ, конфигурация, сопоставление и отправка.
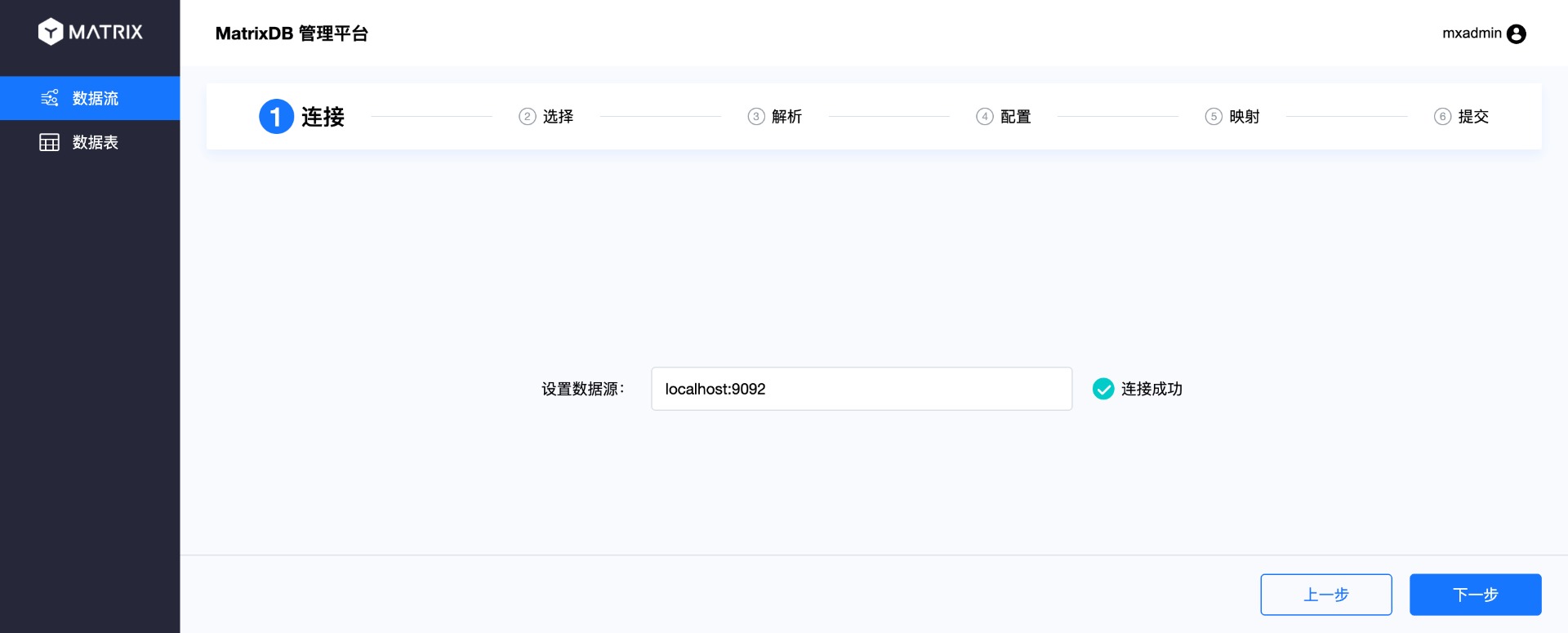
Выполняется первый шаг: подключение. Введите адрес сервера Kafka в источнике данных и нажмите «Далее».
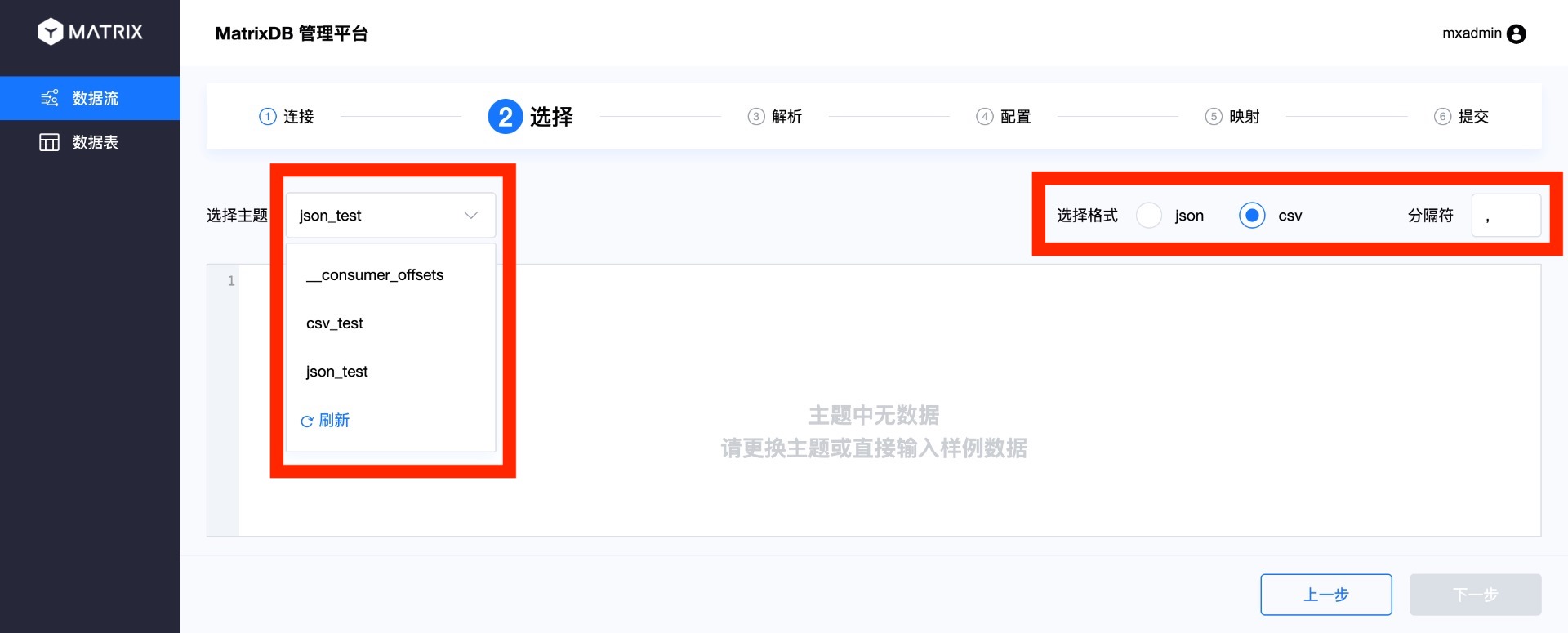
На странице выбора выберите топик Kafka, в данном случае — созданный ранее топик csv_test. Одновременно выберите соответствующий формат топика справа, для формата CSV также необходимо указать разделитель.
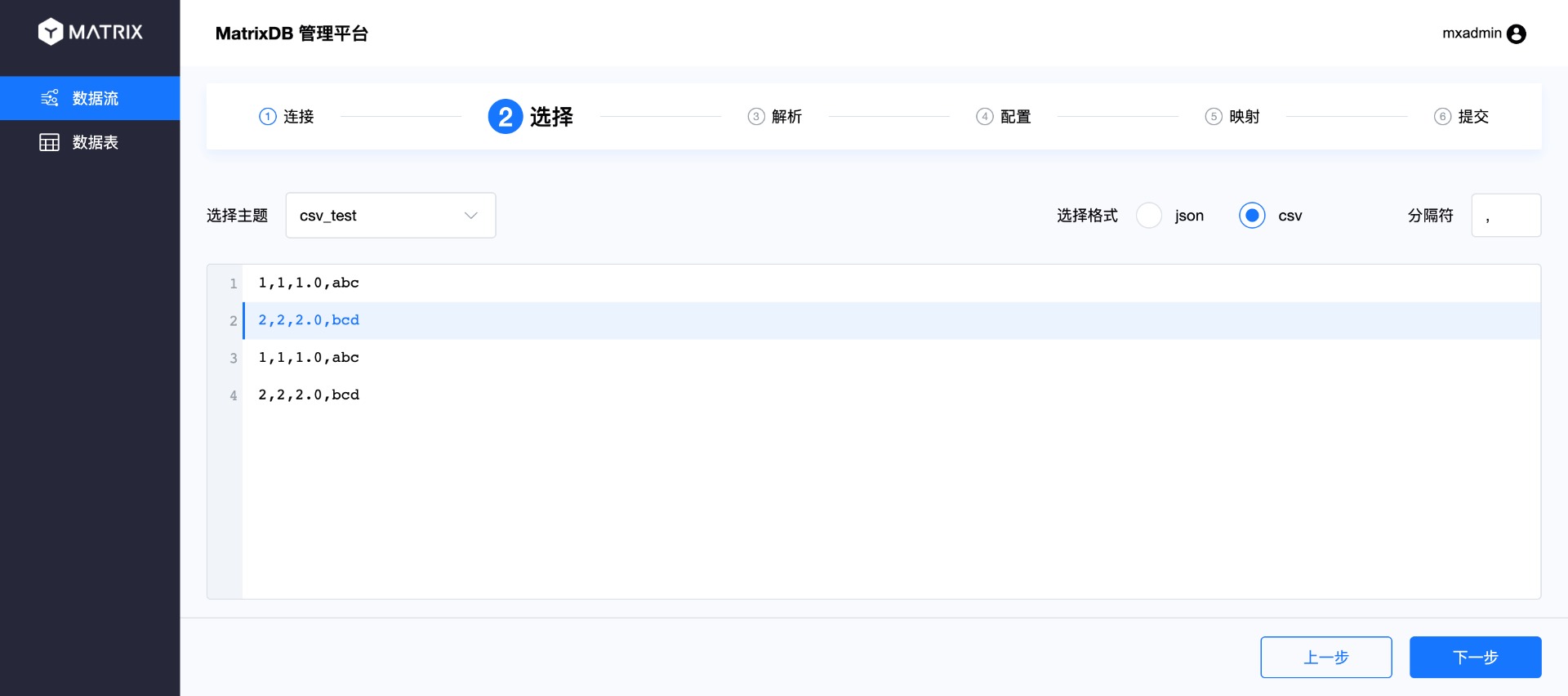
После выбора топика вы увидите данные из него. По умолчанию выбираются первые 10 элементов в качестве примера. Поскольку мы записали только 4 элемента в топик, здесь можно увидеть все 4 записи. Выберите одну из них для последующего разбора и сопоставления.
На странице анализа будет выполнен разбор выбранных ранее примеров данных. Справа отобразятся номера индексов и соответствующие значения, разделённые указанным разделителем. После проверки нажмите «Далее»:
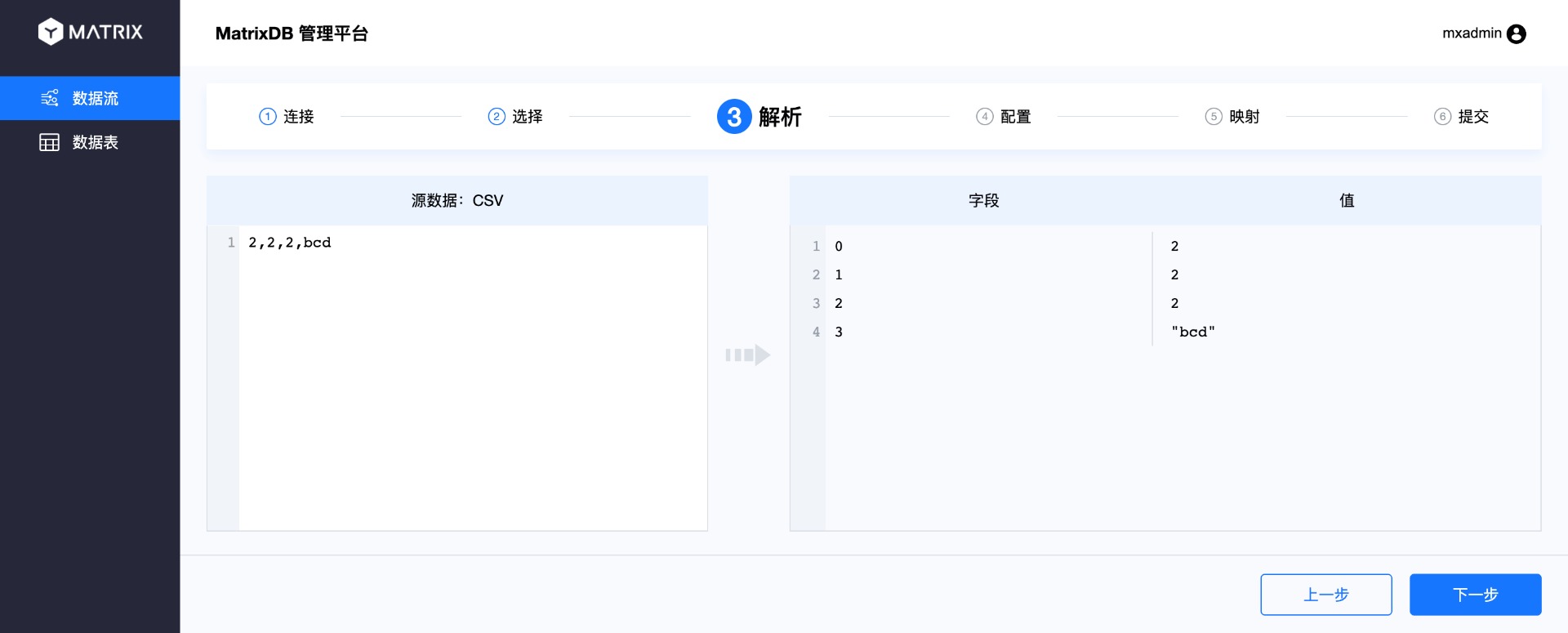
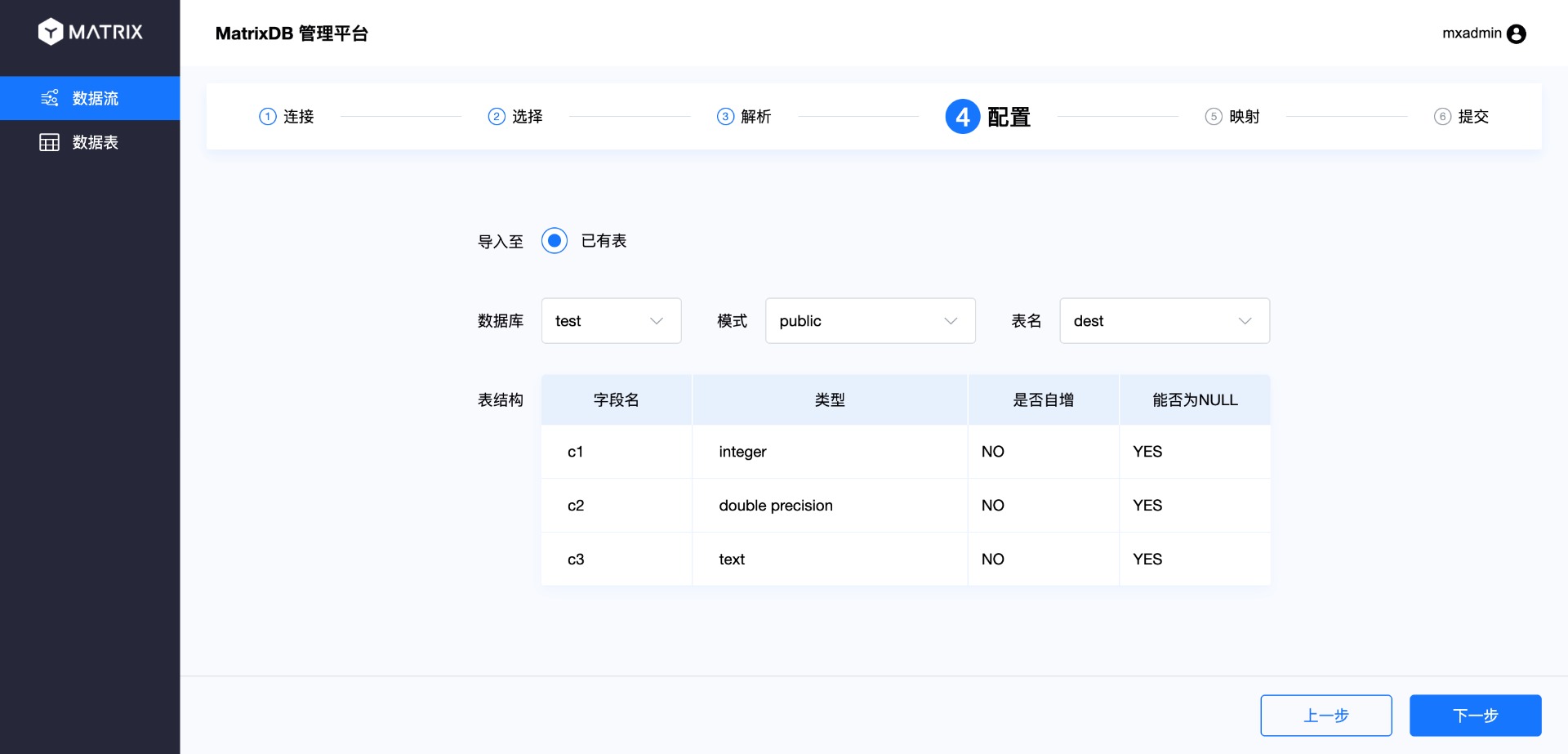
На странице конфигурации выберите, к какой целевой таблице будут подключаться данные топика. После самостоятельного выбора базы данных, схемы и таблицы отобразится структура таблицы.
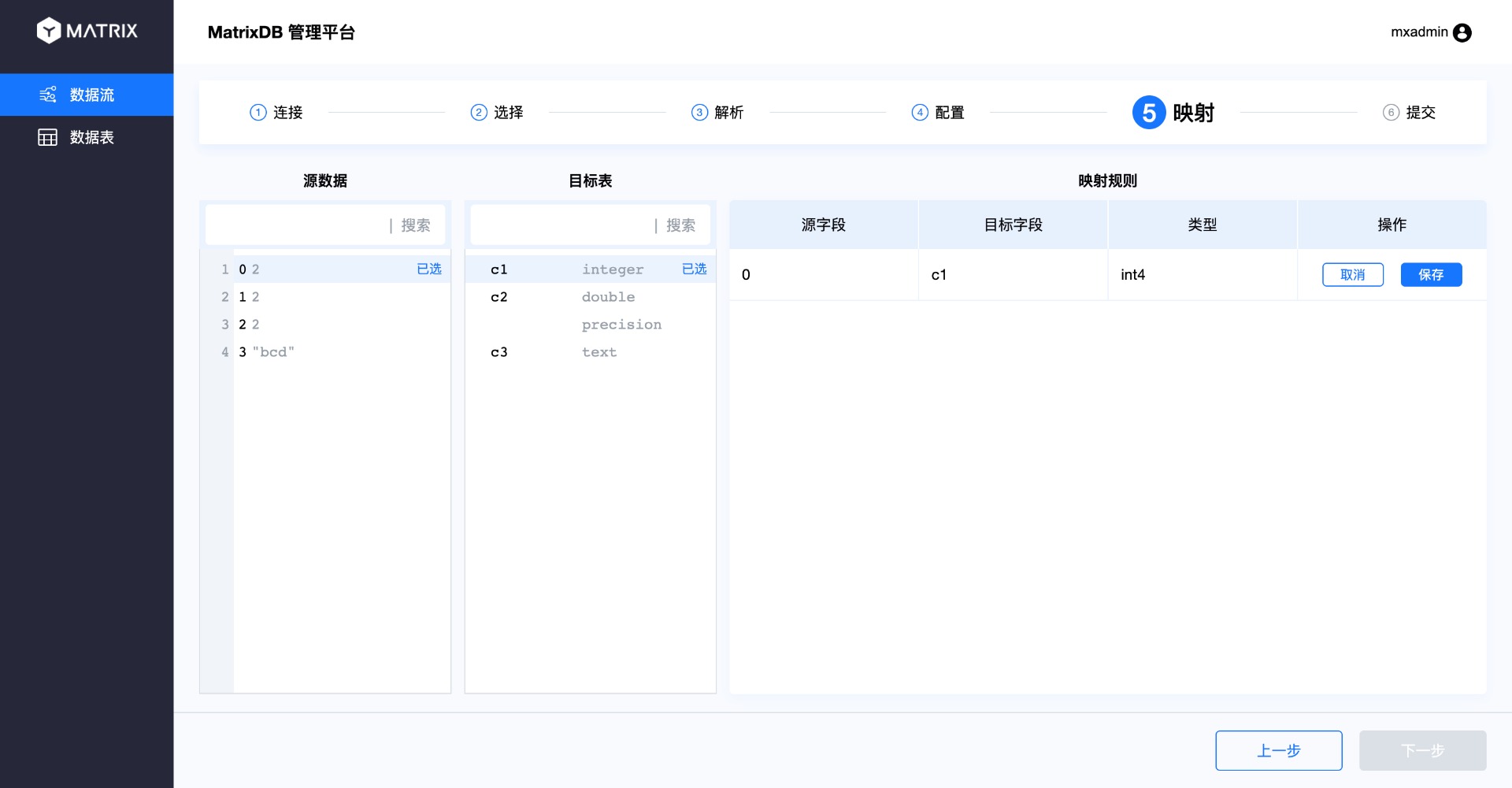
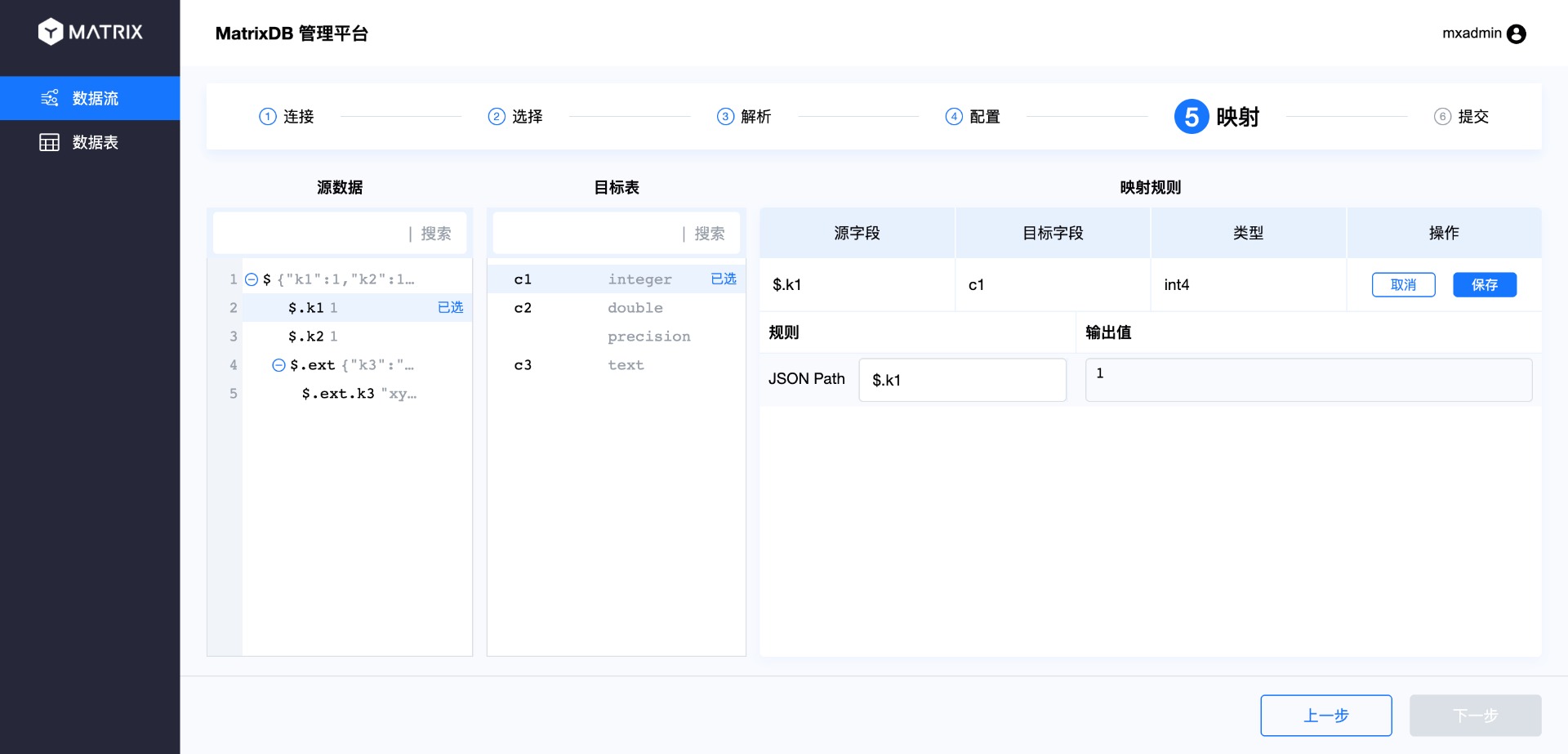
На странице сопоставления выполняется привязка исходных данных к целевой таблице, то есть сопоставление столбцов CSV со столбцами таблицы базы данных. Операция заключается в выборе столбца из исходных данных, а затем — соответствующего столбца в целевой таблице. Таким образом, новое правило сопоставления появится в списке правил справа. После завершения нажмите «Сохранить».
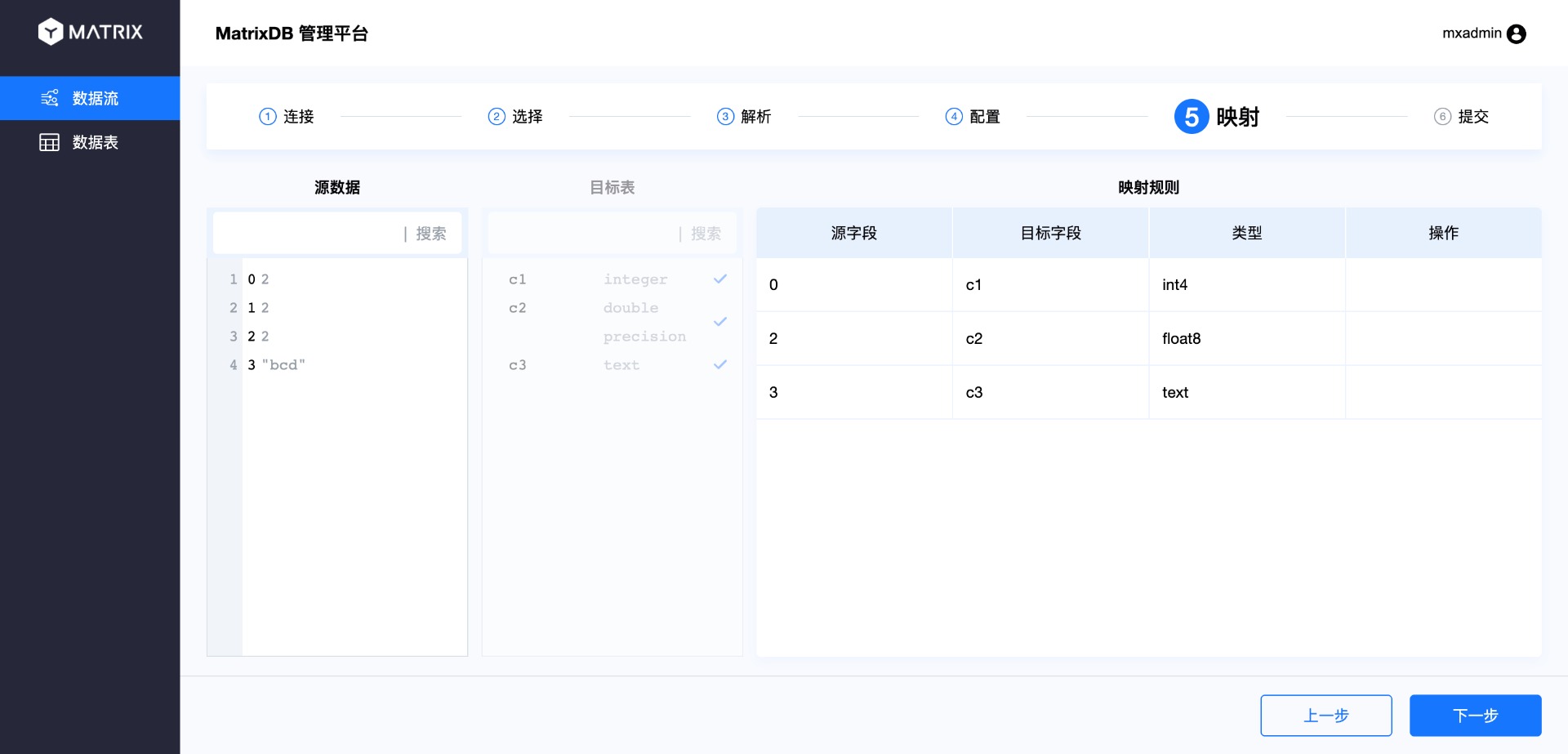
Повторите этот шаг для сопоставления всех столбцов.
Обратите внимание на два момента:
Типы сопоставляемых столбцов должны совпадать, в противном случае появится следующая ошибка:
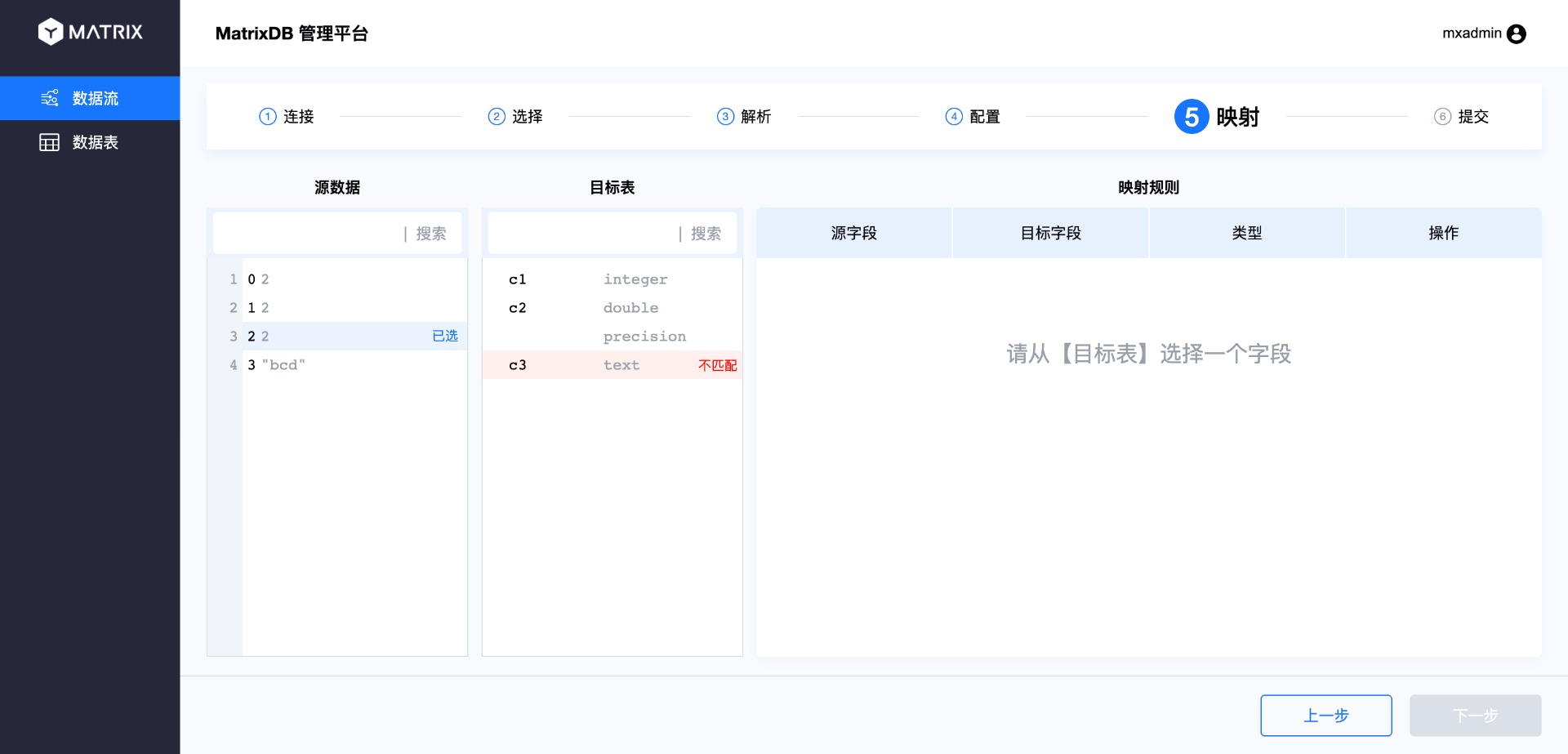
Если количество столбцов в CSV не совпадает с количеством столбцов в таблице базы данных или они не могут быть сопоставлены один к одному, допускается наличие несопоставленных столбцов. Несопоставленные столбцы из исходных данных будут проигнорированы; несопоставленные столбцы целевой таблицы будут заполнены значениями NULL или значениями по умолчанию согласно правилам создания таблицы.

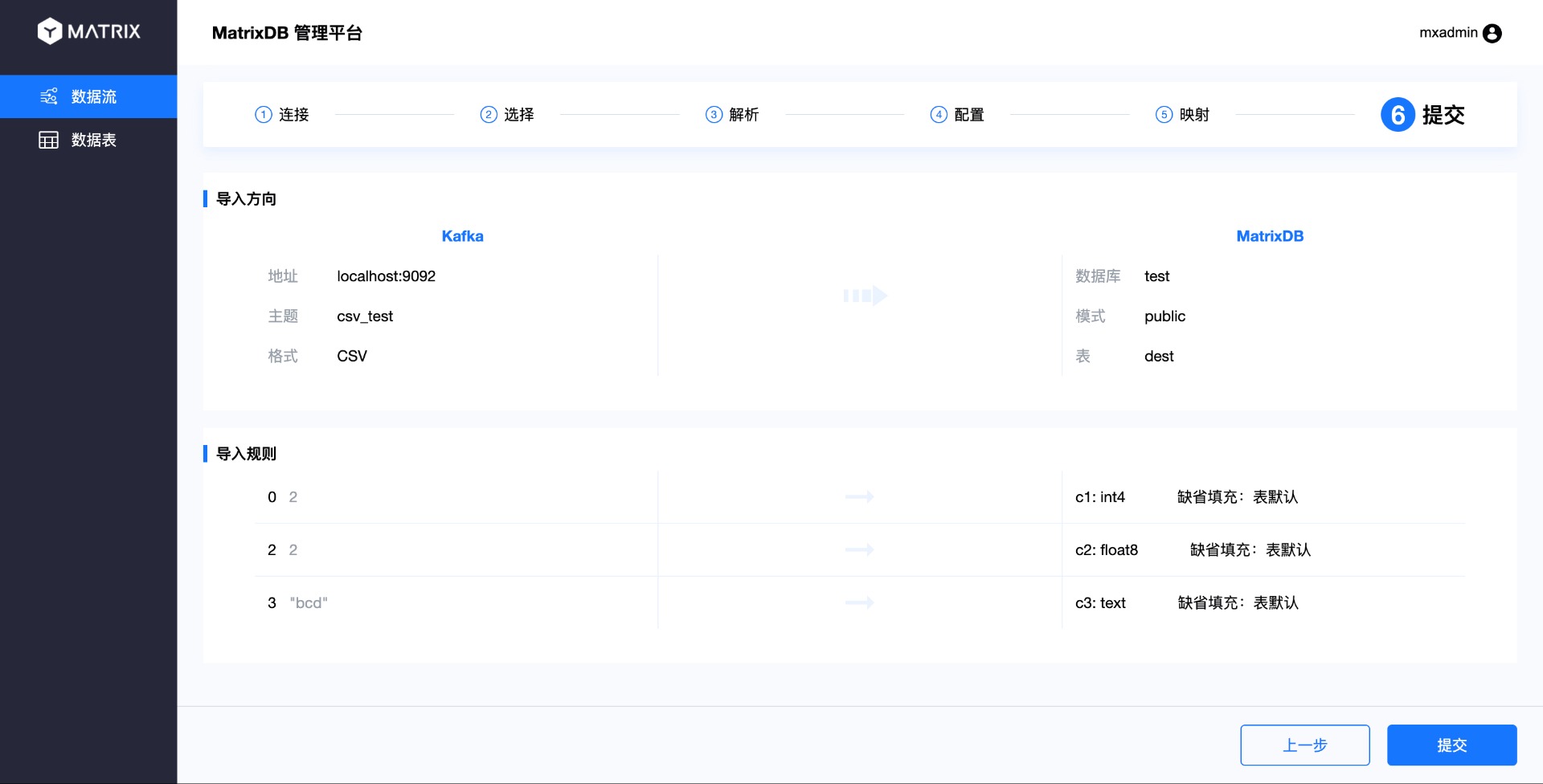
После завершения сопоставления открывается последняя страница — «Отправка». На этой странице отображаются все ранее выбранные параметры. Убедившись в корректности, нажмите «Отправить».
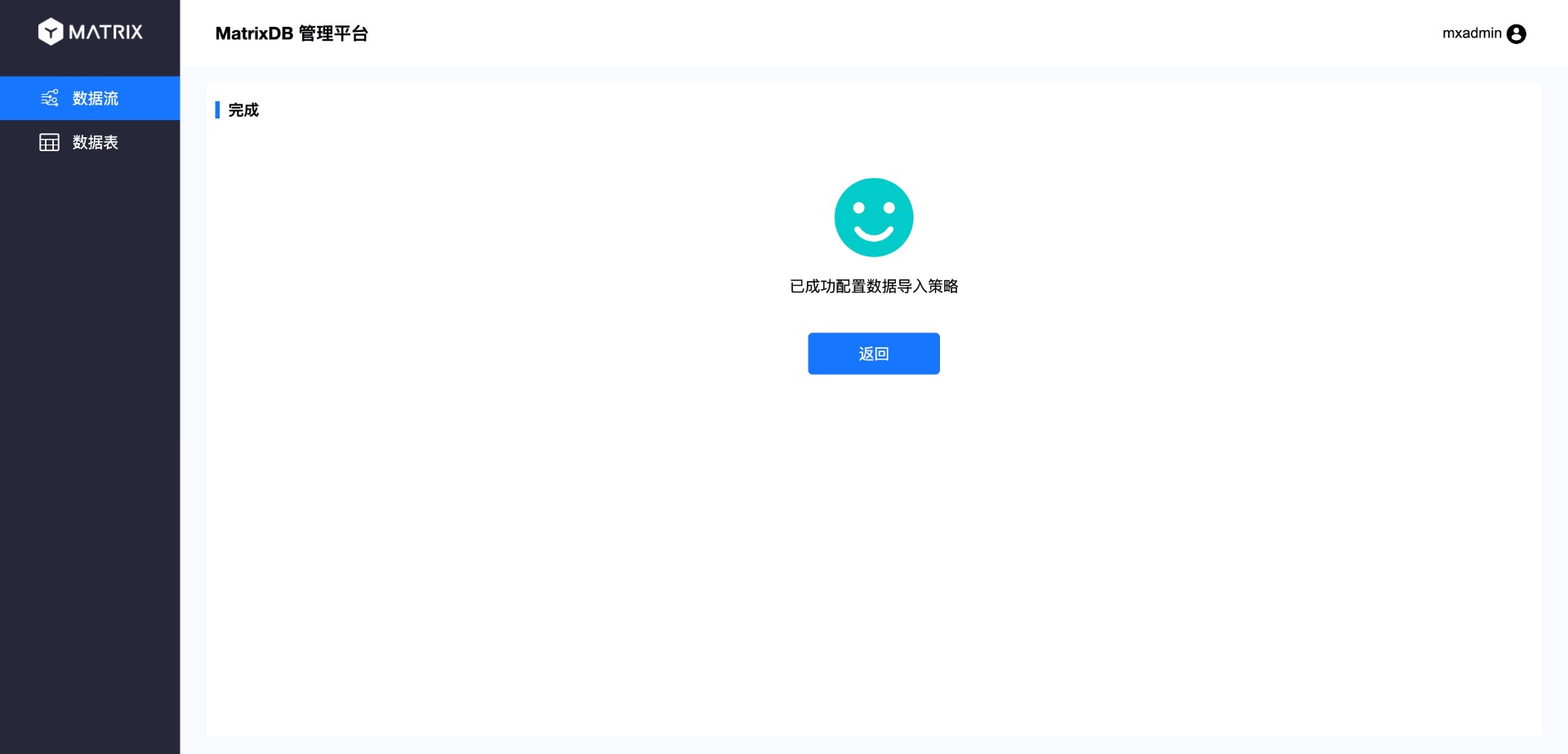
В конце откроется страница завершения:
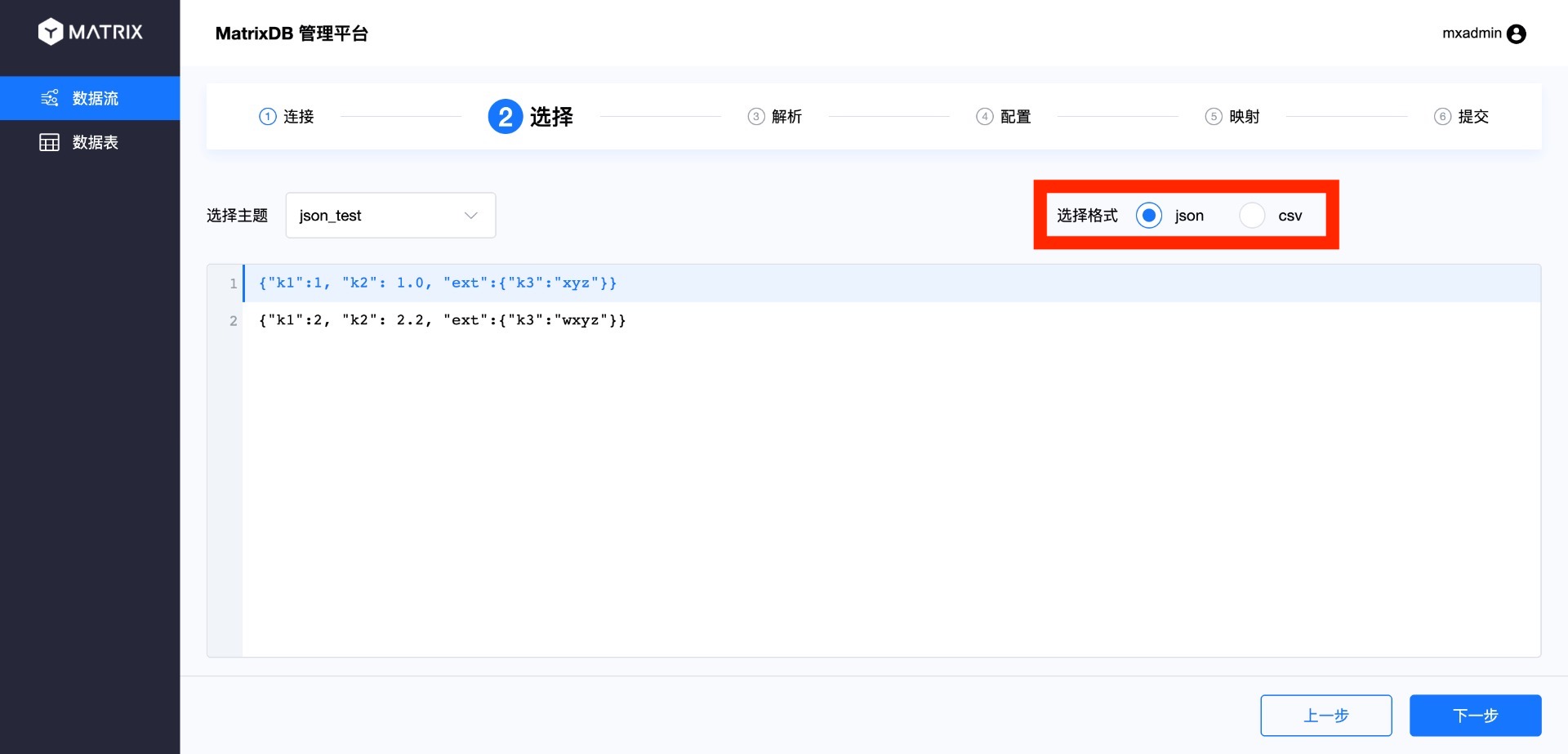
В настоящее время доступ к данным Kafka поддерживает два формата: CSV и JSON. Ранее был продемонстрирован доступ к данным в формате CSV. Теперь рассмотрим различия при работе с форматом JSON.
На странице выбора выберите формат JSON.
Как видно из страницы анализа, индексация столбцов JSON начинается с символа $, а затем следует . плюс имя столбца.
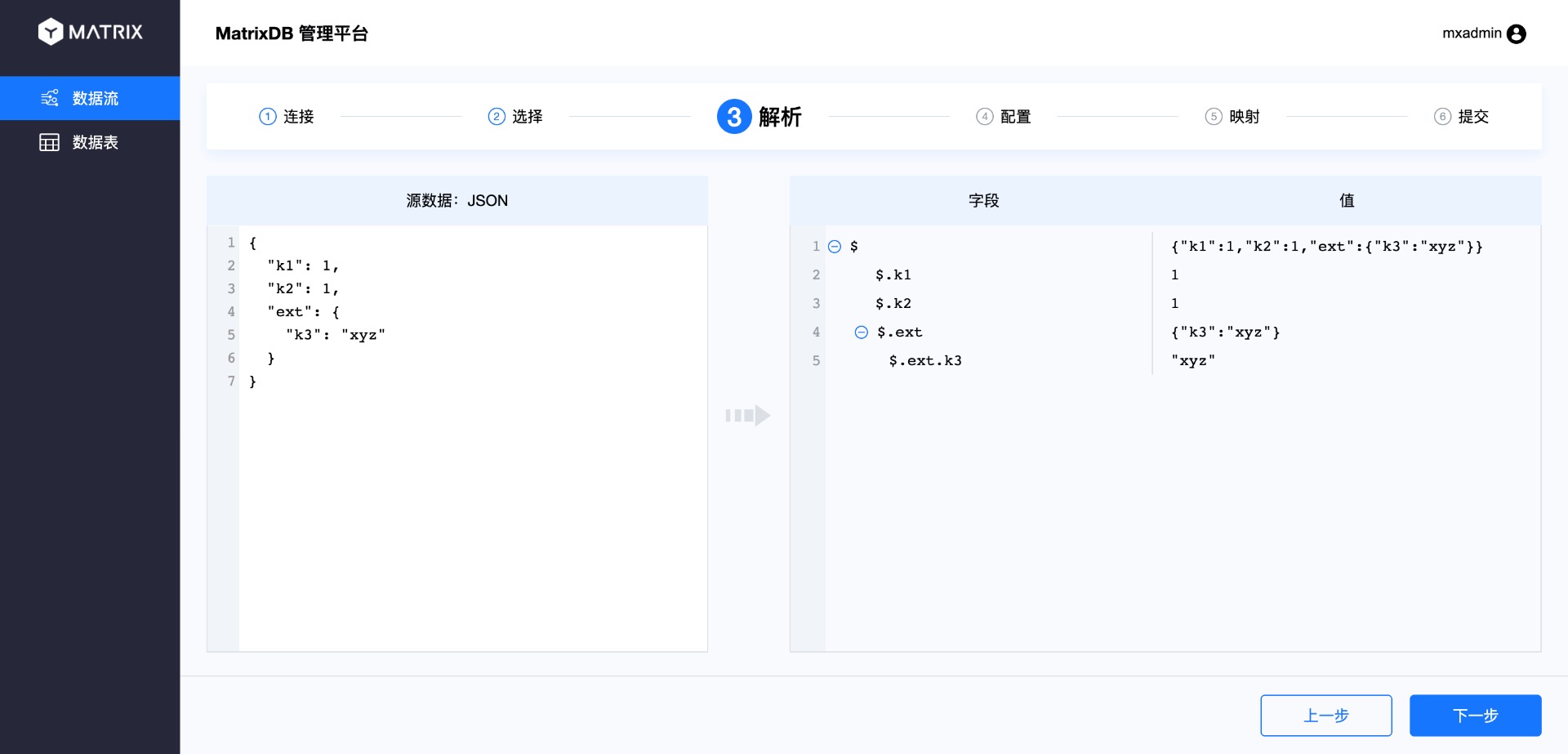
Так как JSON поддерживает многоуровневую структуру, на странице сопоставления можно выбирать столбцы из разных уровней:
После создания процесса доступа в соответствии с описанным выше порядком работа завершена. Данные, записанные в топик, а также новые поступающие данные, будут передаваться в целевую таблицу. Вернувшись на главный интерфейс, вы увидите информацию о созданном процессе потока данных:
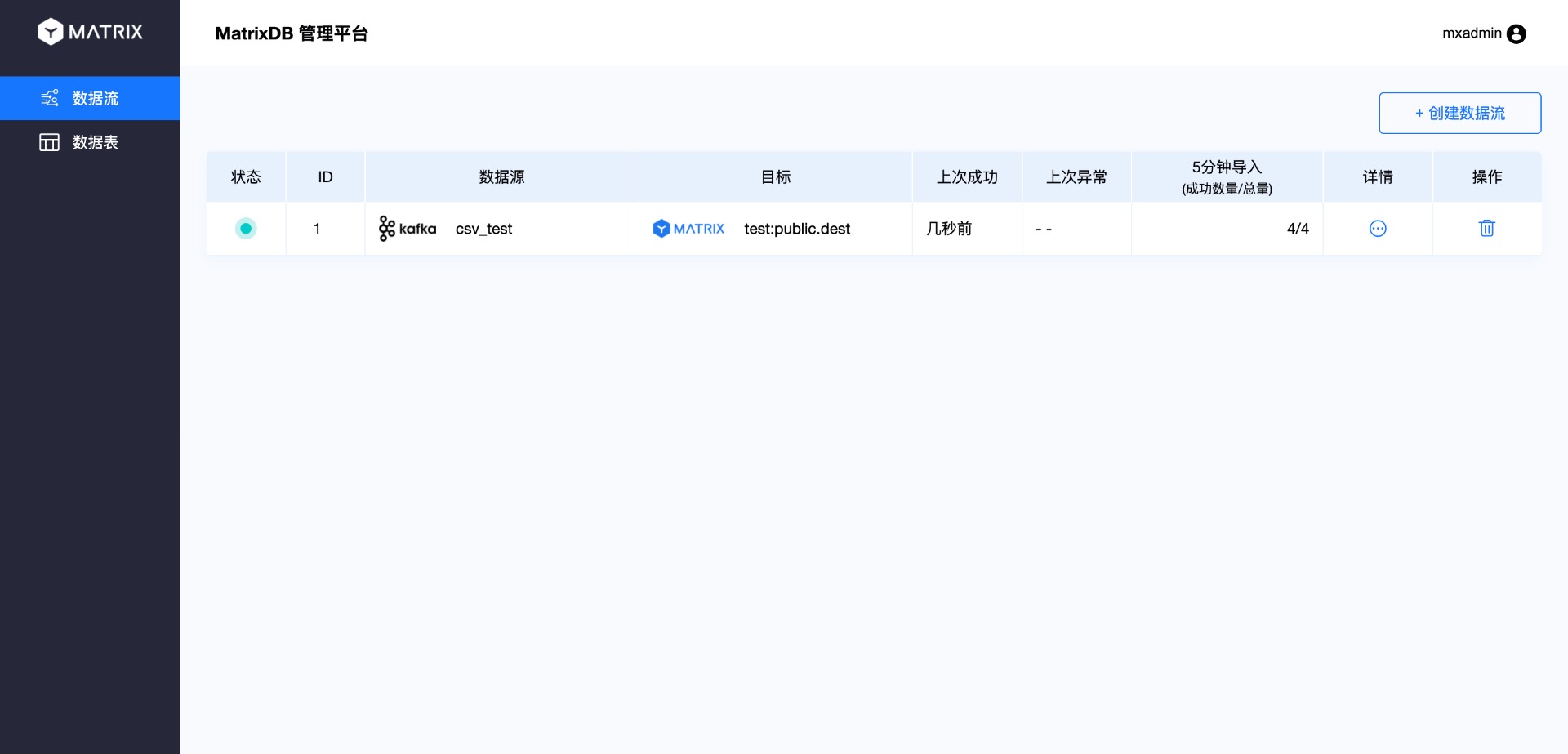
Нажмите «Подробности», чтобы перейти на страницу детализации:
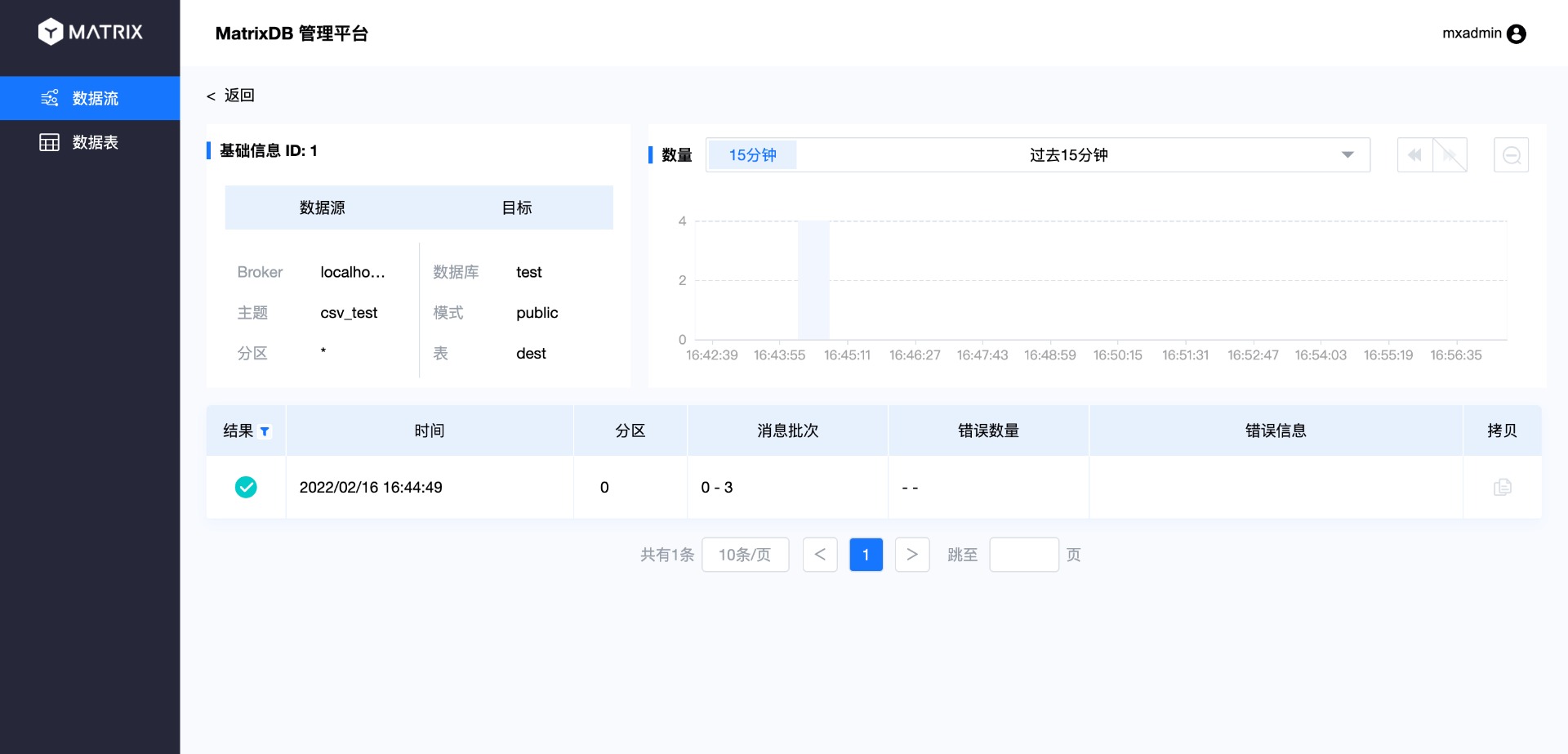
Далее войдите в базу данных, чтобы проверить корректность получения данных:
test=# select * from dest;
c1 | c2 | c3
----+----+-----
1 | 1 | abc
2 | 2 | bcd
1 | 1 | abc
2 | 2 | bcd
(4 rows)