В крупных аналитических базах данных параллельное сканирование обычно означает привлечение большего числа вычислительных ресурсов, поэтому теоретически запросы должны выполняться быстрее. Однако в реальных бизнес-сценариях производительность запросов зависит не только от скорости самого сканирования, но и от того, нужно ли «перемещать» данные. Часто сканирование само по себе достаточно быстрое, но реальным узким местом становятся промежуточное перемещение данных, дополнительное перераспределение и связанное с этим усложнение исполнительной цепочки. Именно для решения этой проблемы и был создан MARS3 Bucket. Это не просто нарезка данных на более мелкие блоки и не традиционное логическое бакетирование. Это такой способ организации данных, который обеспечивает более тесную координацию между параллельным сканированием и локальными вычислениями. Благодаря этому после параллельного сканирования данные сохраняют хорошую локальность, сокращается ненужное перемещение данных, и выгода от параллелизации легче преобразуется в реальное ускорение сквозных запросов. Тесты показывают, что использование MARS3 Bucket для сложных аналитических запросов (например, TPCH, TPCDS) даёт примерно двукратный прирост производительности по сравнению с предыдущей версией YMatrix.
Чтобы понять суть проблемы, необходимо разобраться с двумя концепциями: совместное размещение данных (co-location) и параллельное сканирование.
Совместное размещение данных (co-location)
В базе данных YMatrix данные распределённо хранятся на нескольких сегментах (data nodes). Все сегменты вместе образуют полный набор данных. При создании таблицы необходимо указать ключ распределения. Данные записываются на основе хэша ключа распределения, который отображается на конкретный сегмент. Если таблицы имеют одинаковый ключ распределения, то одинаковые значения ключа гарантированно попадают на один и тот же сегмент. Благодаря этому операции JOIN и GROUP BY по ключу распределения могут выполняться максимально эффективно — большая часть работы происходит локально на узле, без перемещения данных. Это явление называется co-location.
Параллельное сканирование
YMatrix использует MPP-архитектуру (Massively Parallel Processing). С точки зрения всей таблицы, каждый сегмент данных сканируется одновременно — это параллелизм на уровне всего instance.
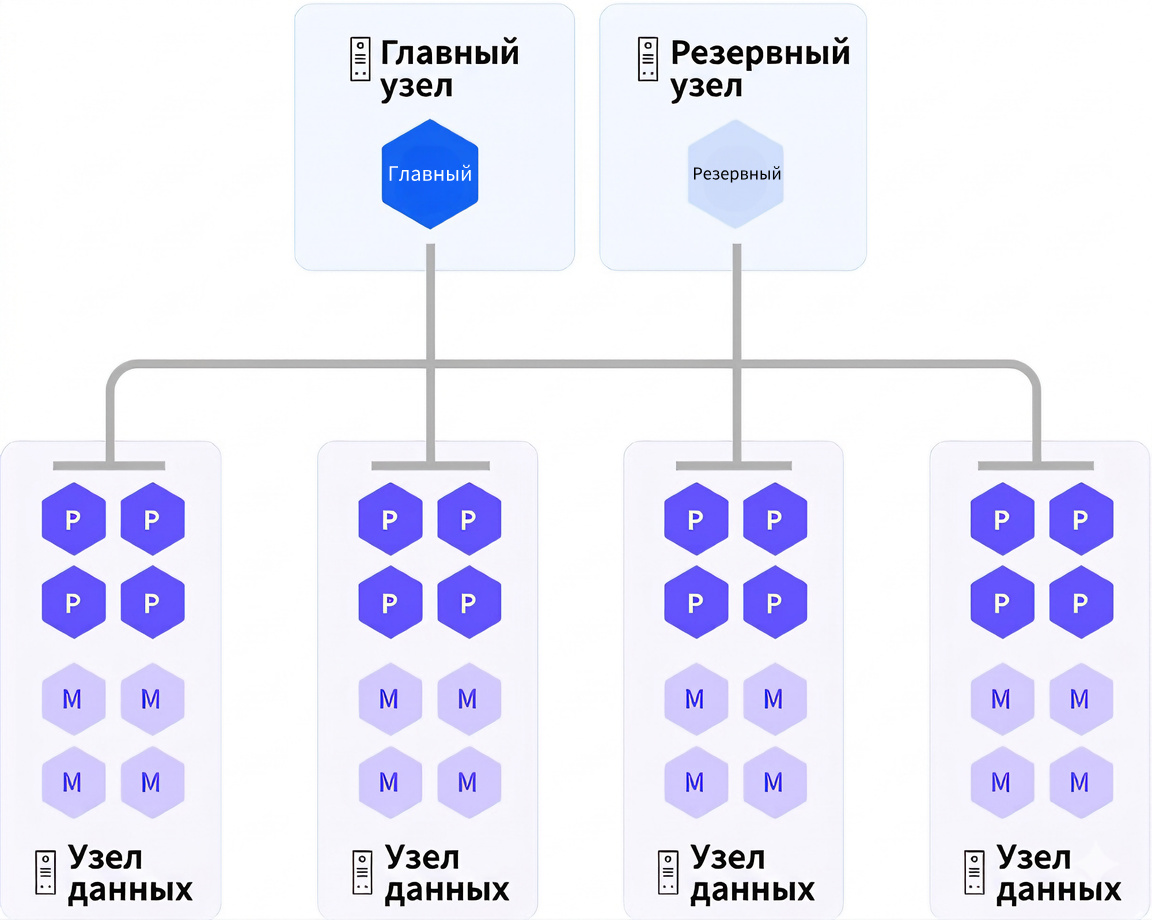
Другой уровень параллелизма — внутри одного сегмента. Несколько процессов могут одновременно сканировать данные, находящиеся на одном узле. Это параллелизм внутри узла.
Вернёмся к вопросу: почему параллельное сканирование не всегда делает запрос быстрее? Во-первых, само параллельное сканирование имеет определённую стоимость: координация между процессами, обмен данными, накладные расходы на создание и управление процессами. В распределённых базах данных ситуация усложняется. Производительность запроса зависит не только от сканирования, но и от того, могут ли данные после сканирования обрабатываться дальше «на месте». Если таблица изначально распределена по хэшу некоторого ключа, то GROUP BY или JOIN по этому ключу могут выполняться локально, поскольку одинаковые значения ключа уже находятся на одном сегменте. master'у остаётся только дождаться результатов от каждого сегмента и выполнить финальную агрегацию.
Однако при использовании параллельного сканирования всё становится сложнее. Параллельное сканирование фокусируется на том, чтобы несколько процессов одновременно вычитывали данные, но оно не гарантирует, что строки с одинаковым ключом останутся вместе. Обычно параллельное сканирование распределяет задачи по страницам или диапазонам. Если одинаковые ключи попадают в разные процессы сканирования, то для корректного выполнения агрегации или JOIN база данных потребует дополнительную передачу данных. В результате работа, которая могла бы быть выполнена локально, превращается в последовательность: «сначала параллельное сканирование, затем перетасовка данных, затем продолжение вычислений».
Рассмотрим пример. Пусть на одном сегменте есть строки со значениями 1, 2, 2, 3, каждая на отдельной странице:
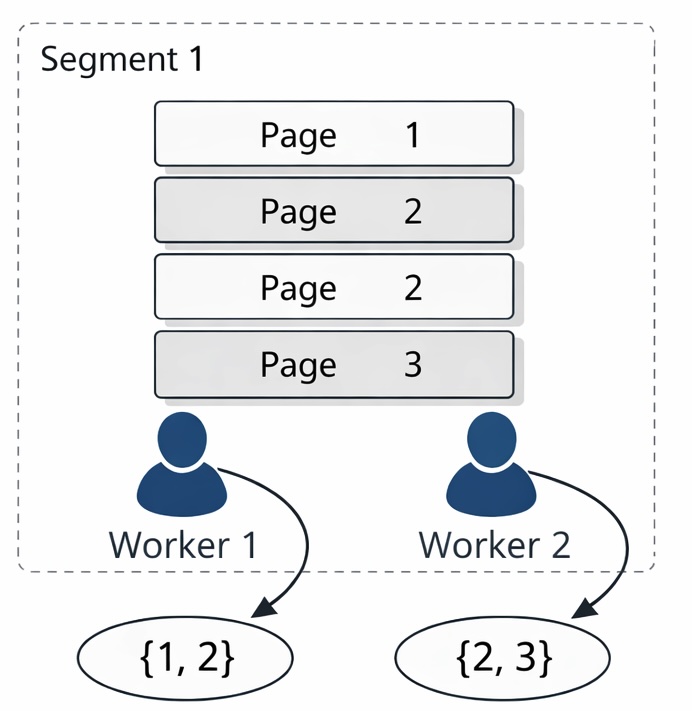
Предположим, два worker'а участвуют в сканировании. worker 1 считывает 1 и 2, worker 2 считывает 2 и 3. В этом случае нельзя гарантировать, что каждое значение (в частности, 2) обрабатывается только одним worker'ом. Для обеспечения корректности результата необходимо собрать и перераспределить промежуточные результаты. База данных вынуждена передавать строки со значением 2 на один узел для дальнейших вычислений. Нетрудно представить, что если таких строк миллионы или даже десятки миллионов, стоимость такого «переезда данных» становится огромной, а исполнительный план — более длинным и сложным. Для заказчика это означает реальную проблему: параллелизм включён, загрузка CPU выросла, но из-за возросшего перемещения данных общая эффективность запроса может не увеличиться.
Для решения описанной проблемы был разработан MARS3 Bucket. Это не просто функция бакетирования и не логическое разделение на уровне синтаксиса. Его ключевая цель — после параллельного сканирования сохранить хорошую локальность данных, чтобы большая часть вычислений продолжала выполняться локально. Если традиционное распределение данных можно описать как «сначала решаем, на какой сегмент попадут данные», то MARS3 Bucket делает следующий шаг: не только определяет сегмент, но и внутри сегмента создаёт более организованное деление на bucket'ы. В результате при параллельном сканировании несколько worker'ов больше не соревнуются за страницы по принципу «кто первый захватил, тот и сканирует». Вместо этого каждый worker сканирует свою группу bucket'ов. Это и есть самое существенное отличие от обычного параллельного сканирования.
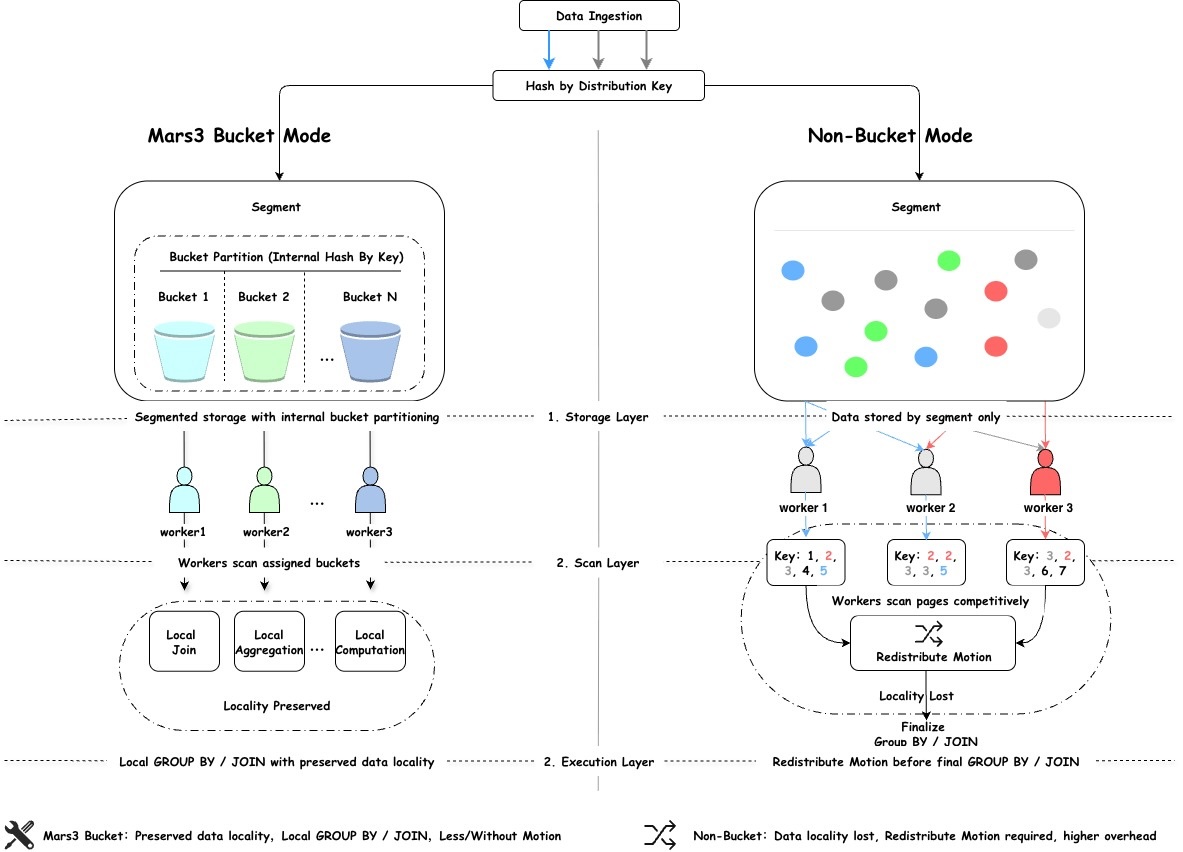
В режиме MARS3 Bucket данные внутри сегмента предварительно организованы в bucket'ы. При сканировании несколько worker'ов обрабатывают разные bucket'ы. Поскольку отображение ключа в bucket детерминировано, одинаковые ключи с большей вероятностью пойдут по одному и тому же пути обработки. Нижележащим операторам становится проще выполнять вычисления локально, без лишнего перемещения данных. Для заказчика основная выгода заключается в том, что параллелизм используется не только для «сканирования», но и для «вычисления». Рассмотрим пример. Пусть есть таблица t_sales с ключом распределения c1. Выполняется SQL: select c1, count(*) from t_sales group by c1; — группировка по c1 и подсчёт строк. В режиме без параллельного сканирования каждый сегмент последовательно сканирует данные локально и сразу выполняет hash-агрегацию. Поскольку таблица распределена по c1, все строки с одинаковым c1 находятся на одном сегменте, перемещение данных между сегментами не требуется. Каждый сегмент формирует корректный локальный результат, и master только собирает их.
Gather Motion 4:1
-> HashAggregate
Group Key: c1
-> Seq Scan on t_salesПри включении обычного параллельного сканирования план выполнения выглядит иначе:
Gather Motion 12:1
-> Finalize HashAggregate
Group Key: c1
-> Redistribute Motion 12:12
Hash Key: c1
-> Partial HashAggregate
Group Key: c1
-> Parallel Seq Scan on t_salesИз-за того, что worker'ы читают страницы конкурентно (случайным образом), оптимизатор не может гарантировать, что каждый c1 обрабатывается только одним worker'ом. Сначала каждый worker выполняет частичную агрегацию (Partial HashAggregate). Затем обязателен этап Redistribute Motion по ключу c1, потому что один и тот же c1 всё ещё присутствует в результатах разных worker'ов. Для финальной корректности требуется перераспределение данных. Именно это «съедает» потенциальный выигрыш от параллелизма.
Для MARS3 Bucket план выглядит так:
Gather Motion 12:1
-> HashAggregate
Group Key: c1
-> Parallel Custom Scan (MxVScan) Благодаря организации данных по bucket'ам, каждый worker сканирует один или несколько bucket'ов. Выходной поток сканирования сохраняет информацию о распределении (знает семантику распределения). Поэтому в плане выполнения больше не требуется явно добавлять Redistribute Motion. Передача данных не нужна. Каждый сегмент выполняет вычисления локально, после чего результаты отправляются на master для финальной агрегации. Таким образом, параллелизм эффективно использует ресурсы CPU и значительно ускоряет выполнение SQL.
Синтаксис использования MARS3 Bucket следующий: при создании таблицы нужно указать количество bucket'ов.
create table foo (c1 int, c2 int) using mars3 with (mars3options='nbuckets = 2').Допустимые значения nbuckets: от 1 до 128. Значение по умолчанию — 1 (один bucket, т.е. бакетирование не применяется).
Основная цель Bucket — предоставить каждому worker'у внутри сегмента собственный bucket для сканирования. Поэтому рекомендуется задавать nbuckets не меньше желаемого количества параллельных worker'ов внутри сегмента. Однако большее количество bucket'ов не всегда лучше, так как оно усложняет запись, обслуживание и внутреннюю навигацию.
Рекомендации:
Размер таблицы < 50 ГБ: не использовать бакетирование (nbuckets=1). Подходит для таблиц-измерений и таблиц с малым набором результатов, которые редко участвуют в больших запросах и чаще используются в точечных или узких запросах.
50 ГБ – 500 ГБ: начинать с nbuckets=4 или 8. Подходит для крупных таблиц фактов размером в десятки-сотни гигабайт, которые часто участвуют в агрегациях и сложных аналитических запросах.
500 ГБ – 2 ТБ: предпочтительно nbuckets=8 или 16. Обычно этого достаточно, чтобы соответствовать типичной степени параллелизма внутри сегмента, не увеличивая число bucket'ов чрезмерно.
2 ТБ: выбирать 16 или 32 в зависимости от реальной степени параллелизма внутри сегмента и результатов нагрузочного тестирования; возможно, стоит рассмотреть более высокие значения.
В распределённых запросах замедление часто вызвано не самими вычислениями, а перемещением данных. MARS3 Bucket помогает избежать лишнего перераспределения данных, позволяя обрабатывать промежуточные результаты локально.
Когда промежуточное перемещение данных сокращается, путь выполнения запроса становится короче и чище. Для сложных аналитических SQL-запросов выгода проявляется не только на этапе сканирования, но и во всей цепочке: меньше промежуточных этапов, меньше накладных расходов на координацию, меньше затрат на промежуточную обработку.
Более быстрое сканирование автоматически не означает более быстрый запрос. MARS3 Bucket позволяет преобразовать возможности параллелизма в реальное ускорение всего запроса, а не только в более интенсивную работу отдельных операторов. Для заказчика это означает, что прирост производительности напрямую отражается на времени выполнения запроса.
В сценариях MPP-запросов самой дорогой операцией часто является не сканирование и не вычисление, а передача данных в процессе выполнения. Если параллельное сканирование не сохраняет семантику распределения данных, оно рискует превратить дополнительные вычислительные ресурсы в ещё больший объём передаваемых данных, а не в повышение эффективности запросов.
MARS3 Bucket помогает избежать этой ситуации. Он делает так, что параллельное сканирование внутри сегмента становится более организованным и лучше приспособленным для вычислений, реально перенося параллелизм на этап «вычисления». Для крупных аналитических сценариев, критически зависящих от локальных агрегаций и JOIN, это означает меньшее перемещение данных, меньшее количество этапов выполнения и более высокую вероятность превратить возможности параллельной обработки в реальный выигрыш в производительности «от начала до конца», что значительно снижает стоимость владения для заказчика.
Глубокий анализ: В эпоху ИИ базы данных вступают в «эпоху унифицированного хранения» (Часть III)
Новый фундамент баз данных в эпоху ИИ: исследование векторизованного выполнения в PostgreSQL
Глубокий анализ: В эпоху ИИ базы данных вступают в «эпоху унифицированного хранения» (Часть II)
Модель потоковой обработки PostgreSQL
Глубокий анализ: В эпоху ИИ базы данных вступают в «эпоху унифицированного хранения» (Часть I)